来源:research.googleblog.com;reddit
编译:文强;胡祥杰;刘小芹
【新智元导读】
数据重要还是算法重要?一篇新的论文或许给出了答案。使用一个 300 倍于 ImageNet 的新数据集,谷歌研究人员发现,随着数据增长,模型完成计算机视觉任务的性能直线上升。即使在 300 倍 ImageNet 这么大规模的情况下,性能都没有遭遇平台。谷歌研究人员表示,构建超大规模的数据集应当成为未来研究的重点,他们的目标是朝 10 亿+ 级别的数据进发。

今年 3 月,谷歌大脑负责人 Jeff Dean 在 UCSB 做了一场题为《通过大规模深度学习构建智能系统》的演讲。

Jeff Dean 在演讲中提到,当前的做法是:
解决方案 = 机器学习(算法)+ 数据 + 计算力
未来有没有可能变为:
解决方案 = 数据 + 100 倍的计算力?
由此可见,谷歌似乎认为,
机器学习算法能被超强的计算力取代
。
现在,谷歌和 CMU 合作的一篇最新论文,又从数据的角度探讨了这个问题。
过去十年中,计算机视觉领域取得了显著的成功,其中大部分可以直接归因于深度学习模型的应用。此外,自 2012 年以来,这些系统的表征能力也因下面 3 个因素取得了大幅进步:
(a)具有高复杂性的更深的模型
(b)增加的计算能力和
(c)大规模标签数据集的可用性
然而,尽管每年计算能力和模型复杂性都在进一步增加(从 7 层的 AlexNet 到 101 层的 ResNet),可用的数据集却没有相应的扩大。与 AlexNet 相比,101 层的 ResNet 的容量也大大增加,可后者训练时仍然使用的是大约 2011 年建立的 ImageNet——一个百万级的图像数据集。
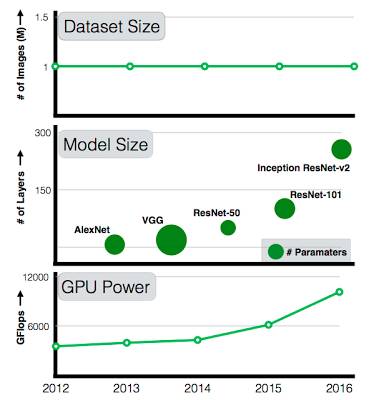
虽然计算力(GPU)和模型大小不断增长,数据集的规模一直停步不前
于是,谷歌的研究人员便想:如果将训练数据的量增加 10 倍,精度是否会翻倍?增加 100 倍甚至 1000 倍呢?准确性会上升到某一水平就不再提高,还是会随着数据的增加越来越高?
谷歌 JFT-300M:构建比 ImageNet 大 300 倍的数据集
在最新上传到 arXiv 的论文《再探深度学习时代数据的超凡有效性》(Revisiting Unreasonable Effectiveness of Data in Deep Learning Era)中,谷歌研究人员朝着解答大数据与深度学习间的疑问迈出了第一步。作者表示,他们的目标是探索:
-
(a)向现有的算法馈送越来越多带有噪声标签的图像,是否能改善视觉表征;
-
(b)了解在分类、物体检测和图像分割等标准视觉任务中,数据和性能之间关系的性质;
-
(c)使用大规模学习的计算机视觉任务中当前最先进的模型的表现。
不过,要做到这一点,最大的问题是:在哪里能找到比 ImageNet 大 300 倍的数据集?
答案——不出意外——当然是“在谷歌”。
在今天发表于 Google Research 的文章里,
谷歌机器感知组成员 Abhinav Gupta 介绍,为了改善计算机视觉算法,谷歌一直在开发建立这样的数据集。现在,他们已经建立了一个名叫“JFT-300M”的内部数据集,含有 18291 个类别。顾名思义,JFT-300M 有 300M 图像,是 ImageNet 的 300 倍。
这 300M 图像有 10 多亿个标签(单个图像可以有多个标签)。标记这些图像的算法结合了原始 Web 信号,网页间的连接和用户的反馈。在此基础上,谷歌研究人员还使用了一个算法,在这些 10 亿图像标签中,挑选出了大约 375M 精度最大的标签。
但是,经过这样的操作后,标签上仍有相当大的噪音:所选图像 20% 左右的标签是噪音标签。Abhinav Gupta 表示,由于没有详尽的注释,他们无法估计实验中标签的召回率。
最后,实验结果验证了一些假设,但同时也产生了一些惊喜:
首先,
更好的表征学习有助于提升性能
。研究人员的第一个观察是,大规模数据有助于进行表征学习,从而提高实验中每个视觉任务的表现。研究结果表明,共同构建一个大规模的预训练数据集十分重要。这也表明,无监督和半监督表征学习方法的前景光明。
此外,从实验结果看,
数据的规模会在一定程度上抵消标签空间中的噪音
。
其次,性能随训练数据的数量级呈线性增长。 谷歌研究人员表示,也许最令他们惊讶的发现是,模型性能与用于表征学习的训练数据数量(log-scale)间的关系呈线性!
即使在 300M 的规模,也没有观察到什么平台
。
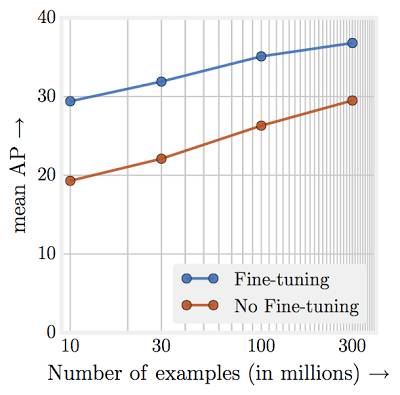
在 JFT-300M 不同子集上的预训练后,进行物体检测的性能。x 轴表示对数刻度的数据集大小,y 轴是 COCO-minival 子集中 mAP@[0.5,0.95]中的检测性能。
容量至关重要
。为了充分利用 300M 的图像,需要更高容量(更深)的模型。例如,COCO 对象检测基准的增益,使用 ResNet-50(1.87%)相比 ResNet-152(3%)要小得多。
此外,使用 JFT-300M 的新数据集,谷歌研究人员在好几个基准上都取得了当前最佳结果。例如,单一模型 COCO 检测基准从 34.3 AP 提升为 37.4 AP。
Gupta 补充强调说,由于没有搜索最佳的超参数集合(因为需要相当大的计算量),所以本次实验得出的结果很可能还不是最佳。也就是说,这次他们的实验可能还没有完全将数据对性能的影响表现出来。
由此,Gupta 指出,虽然难度很大,但获取针对某一任务的大规模数据应当成为未来研究的重点。
在模型越来越复杂的现在,谷歌的目标是——朝着 10 亿+ 的数据集前进。
Reddit 评论:不需要那么大的数据集,需要更高效的算法模型
Reddit 上网友对谷歌这篇新论文有很多讨论。新智元摘选其中有代表的观点。其中,获得点赞数最多的评论来自网友









