随着互联网大数据的爆炸式增长,它蕴含的巨大价值引起了科技界、企业界和各国政府的高度重视。在大数据背景下,图片、文本、语音、视频以及关系型结构信息等异构多模态数据混合在一起,成为信息的主要表现形式。这些数据具有重要的研究意义以及应用价值,如多模态内容深度语义分析、监控视频与身份图片匹配以及用户行为预测等。
一般而言,异质多模态数据存在两个基本特性:互补性与一致性,即多模态数据具有一致的语义概念和互补的信息表达。这些特性有助于深入理解多模态数据并有利于处理相应的实际任务。然而,传统的数据分析理论、方法与技术无法很好地处理多模态数据的异构特性。如何设计有效的多模态大数据表示、度量和语义理解方法以缓解模态间异质问题成为当前多模态数据分析与理解的主要任务。同时,考虑到多模态数据可能存在模态缺失,模态标注信息存在语义相关特性等问题,如何针对上述实际场景设计更为有效的策略也将是多模态数据分析的研究难点。下面为大家介绍几个代表性工作。
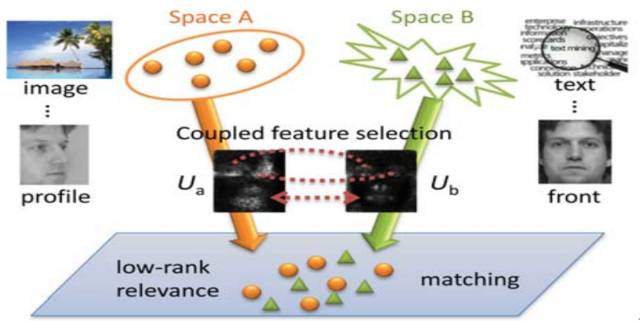
为了解决异质多模态数据存在的语义鸿沟问题,我们提出了一种双线性特征学习模型。首先,基于线性投影,我们将不同模态数据映射到同一语义空间,在该子空间下,不同模态数据的相关性得以进行挖掘。同时,通过结构化稀疏约束,我们可以选择具有较强判别能力的特征进行有效的特征学习。模型的最后增加迹范数以进一步对多模态数据关系构建进行补充和增强。在跨模态数据匹配任务上,我们在两个比较有挑战的数据集上进行了一系列的实验,结果表明我们取得了相比于经典方法更优的性能[1]。
原文链接:
https://mp.weixin.qq.com/s/13iZJYrQ-AUuIp88R5yjkA




