来源:伯乐在线,
作者:玻璃猫
------
【导读】
------
理解机器学习真的没那么难。
在一个风和日丽的周末……


故事一:瑞雪兆丰年








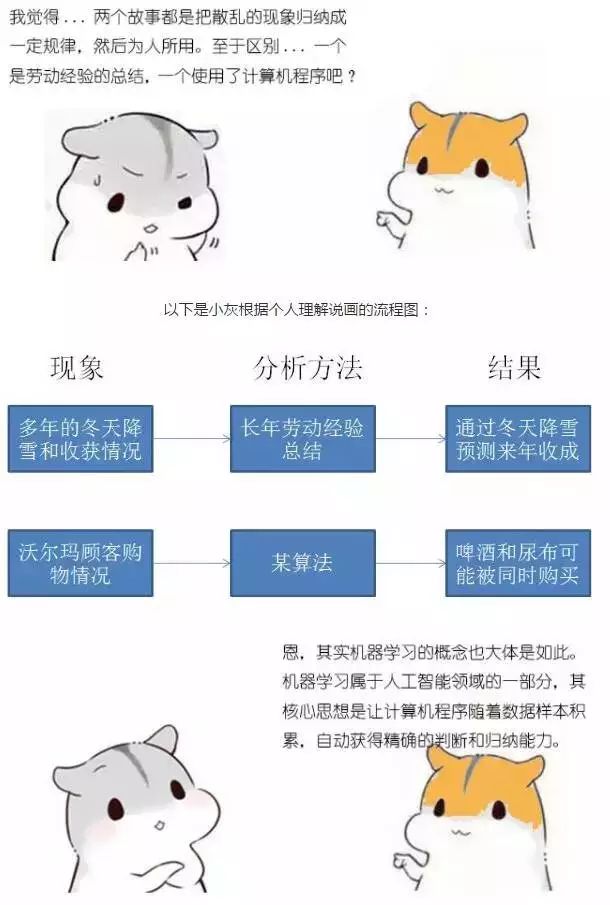
这就是瑞雪兆丰年的故事。头年的瑞雪和来年的丰收,本是两个看起来并不相关的现象,但是智慧的农民伯伯通过几十年甚至几代人的经验,总结出了两个现象之间的规律。
现代的农业学家通过科学的分析,弄清了瑞雪兆丰年规律背后的本质原理。但是对于古代农民伯伯来说,知道规律就足够了,可以通过规律来为下一年的生产生活做出有效的调整。
故事二:啤酒和尿布
上个世纪90年代,沃尔玛超市已经是美国最大的零售企业,拥有大量的顾客资源。那时候的沃尔玛已经采用了先进的计算机技术,随时记录着每天众多顾客购物车中所挑选的商品明细。



从此,沃尔玛的销售额得到了显著提升,啤酒尿布的故事也广为流传,成为了销售界和IT界津津乐道的成功典范……
这就是沃尔玛啤酒和尿布的故事。顾客购买啤酒的行为和顾客购买尿布的行为,原本是两个看起来没什么关联的现象。但是沃尔玛的技术专家以大量的用户购物数据为样本,通过先进的算法,最终寻找到了两者之间的重要关联和规律。
为什么购买啤酒的人更有可能同时购买尿布呢?是因为有了小孩的男人比别人更爱喝啤酒?还是因为爱喝啤酒的男人比别人更顾家?这些臆测似乎都有些牵强。
但是沃尔玛不需要关心规律背后的本质。对企业来讲,利用发现的规律,获得实实在在的利益就足够了。


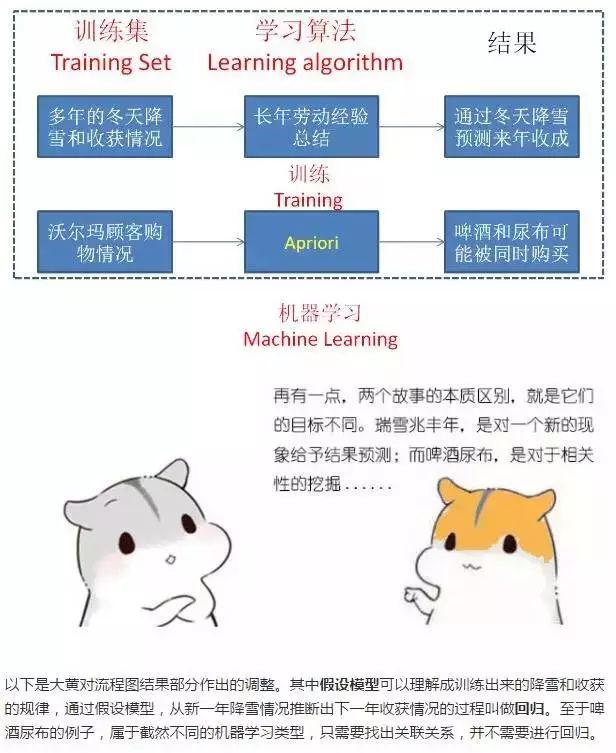
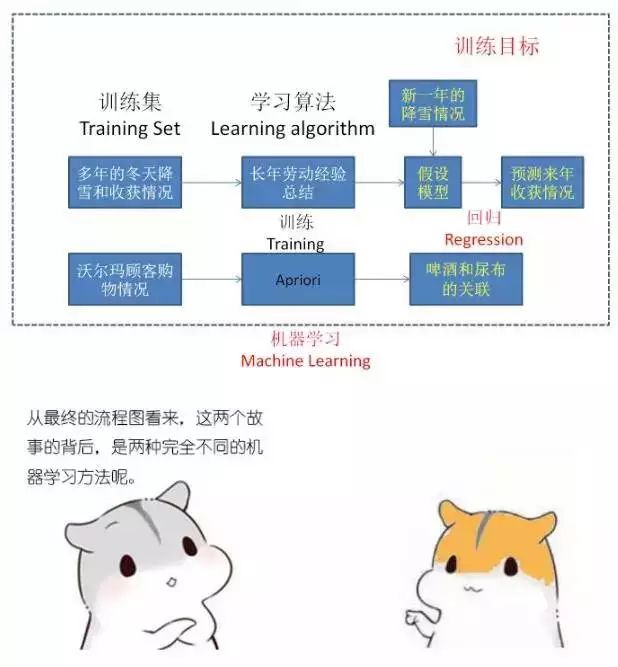

机器学习按照方式不同主要分为三大类,有监督学习(Supervised learning)、无监督学习(Unsupervised learning)以及半监督学习(Semi-supervised learning)。
监督学习:
通过已有的一部分输入数据与输出数据之间的对应关系,生成一个函数,将输入映射到合适的输出。在瑞雪兆丰年的例子中,头年降雪量就是输入,来年亩产量就是输出。
非监督学习:
直接对输入数据集进行建模,寻找关联。例如啤酒尿布的例子,只需要寻找关联性,并不需要什么明确的目标值输出。
半监督学习:
综合利用有输入输出的数据,和只有输入的数据来进行训练。可以简单理解成监督学习和非监督学习的综合。

阅读原文,更多热门;扫码识别,关注“机器人网”






