作者:鲁伟
一个数据科学践行者的学习日记。数据挖掘与机器学习,R与Python,理论与实践并行。个人公众号:数据科学家养成记 (微信ID:louwill12)
作为一名毫无开发经验的非计算机出身的数据爱好者,初入此坑时深受爬虫难学之苦,当初未通Python之道,写个scrapy框架就痛苦至极。想想现在大数据技术那么牛逼了,为什么我抓个数据还处处被封,后来又觉得是自己技术不够强大。本文以拉勾网为例给大家介绍一款便捷快速的R语言爬虫方法,通过Rvest包+SelectorGdaget选择器即可轻松实现简单的数据抓取。
01准备工具:Rvest包+SelectorGadget选择器
下载安装Rvest包:
install.packages("Rvest")
library(Rvest)
要想全面了解Rvest包的朋友可以去查官方帮助文档:
help(package="Rvest")
Selectorgadget插件作为一个轻便快捷的CSS选择器,好用程度简直爆炸,鼠标点击几下即可生成你想要抓取的html节点信息。这么一款神器,调用方法也是极其简单,打开任何一款搜索网页,键入Selectorgadget,点击第一个链接,也是Selectorgadget官方链接,拉到页面底端倒数第二个链接,将其拖拽到你的浏览器收藏夹,待下次打开需要爬取的网页时点击即可启用。
需拖拽的链接如图(Or drag this link to your bookmark bar):
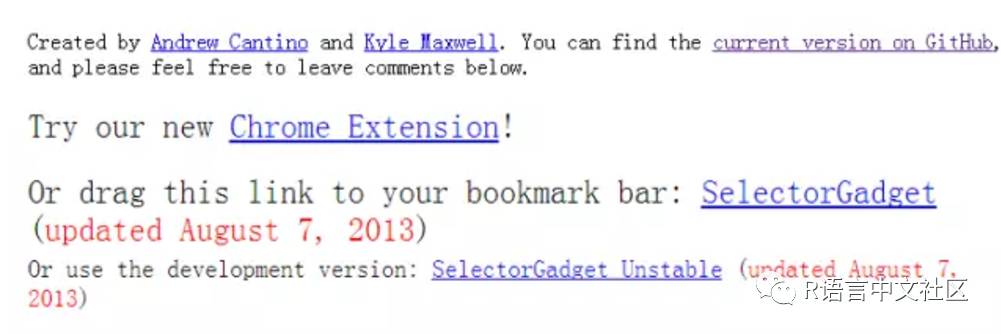 下次调用时,打开需要抓取的网页,点击我们拖拽到收藏夹的Selectorgadget会在网页右下角出现一个长方形条框,点击网页中任何我们想抓取的信息,条框内即可生成相应的文本表达式,将这些文本表达式复制到Rvest包对应的爬虫函数中,即可轻松完成抓取。需要注意的是,使用Selectorgadget选择节点信息是一个筛选的过程,其间需要将我们不需要的信息(点击后变红)重复点击以删除,留下需要的信息(绿色和黄色部分)。
下次调用时,打开需要抓取的网页,点击我们拖拽到收藏夹的Selectorgadget会在网页右下角出现一个长方形条框,点击网页中任何我们想抓取的信息,条框内即可生成相应的文本表达式,将这些文本表达式复制到Rvest包对应的爬虫函数中,即可轻松完成抓取。需要注意的是,使用Selectorgadget选择节点信息是一个筛选的过程,其间需要将我们不需要的信息(点击后变红)重复点击以删除,留下需要的信息(绿色和黄色部分)。
02,拉勾网数据抓取
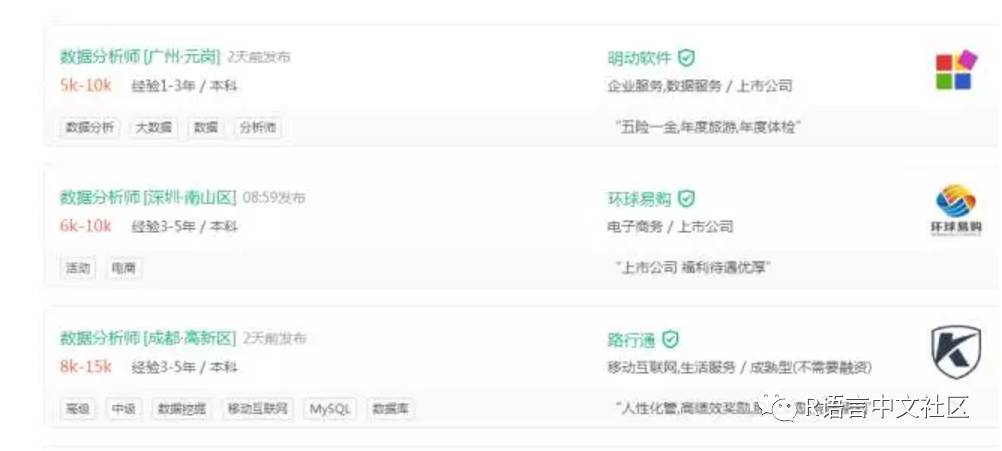
我们选择抓取拉勾网数据分析师岗位信息:
抓取代码如下:
library(stringr)
library(xml2)
library(rvest)
i1:30
lagou_data#创建数据框存储数据
for (i in 1:30){
web"https://www.lagou.com/zhaopin/shujufenxi/",i),encoding="UTF-8")
job%>%html_nodes("h2")%>%html_text()
job[16]job#将多余信息设置为NA并剔除
company%>%html_nodes(".company_name a")%>%html_text()
inf1%>%html_nodes(".p_bot .li_b_l")%>%html_text()
inf2%>%html_nodes(".industry")%>%html_text()
temptation%>%html_nodes(".li_b_r")%>%html_text()
#存储以上信息
job_inflagou_data}
write.csv(job_inf,file="D:/Rdata/datasets/job_inf.csv")
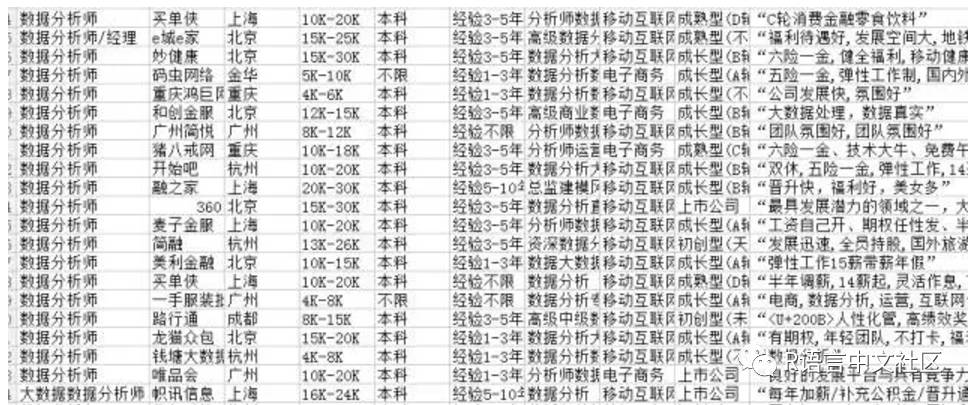
清洗整理后最终抓取部分数据示例如图:
03,简单小结
用rvest包结合SelectorGadget 选择器能够快速实现R语言下的网络数据抓取,并适当结合stringr包中的字符串处理函数对网页数据进行清洗和整理,抓取过程省时省力,适合R语言和爬虫入门的朋友使用学习。



微信回复关键字即可学习
回复 R R语言快速入门免费视频
回复 统计 统计方法及其在R中的实现
回复 用户画像 民生银行客户画像搭建与应用
回复 大数据 大数据系列免费视频教程
回复 可视化 利用R语言做数据可视化
回复 数据挖掘 数据挖掘算法原理解释与应用
回复 机器学习 R&Python机器学习入门










