张文彤:
现任上海昊鲲企业管理咨询有限公司技术创新与发展中心负责人。华西医科大学卫生统计学硕士,复旦大学流行病与卫生统计学博士。曾在复旦大学公共卫生学院任教数载,积累了丰富的教学经验。期间在国内权威期刊及国外SCI期刊发表论文十余篇,主持国家自然科学基金一项,获复旦大学“世纪之星”称号。精通各种统计软件,主编SPSS、SAS、Stata等统计软件教材7本,其中一本SPSS教材被教育部评为2003-2004年度教育部研究生推荐教材。
数据挖掘是什么?先举一个例子:
1.案例数据为一份关于药物研究的数据。患有同种疾病的不同病人,服用五种药物中的一种(drugA、drugB...)后,都取得了同样的治疗效果;现在需要
利用数据挖掘技术
发现以往药物处方适用的规律,对于不同特征(血压、胆固醇、钠钾含量等)的病人给予更适合哪种药物的建议。
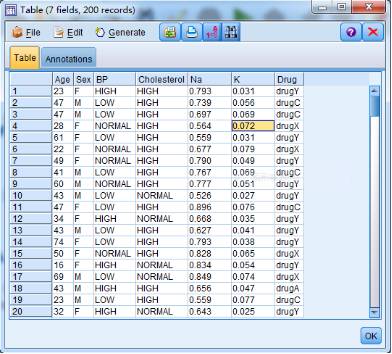
2.观察各个变量的数据特征:可以看到MODELER对此计算除了最小值、最大值、均值、标准差、偏态系数等基本描述统计,同时还输出了数值型变量的直方图以及分类型变量的柱形图。
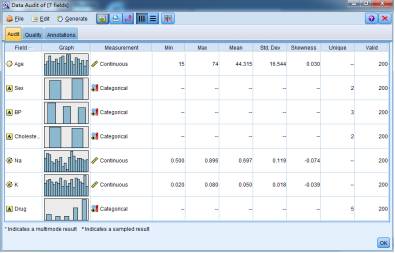
3.通过散点图反应服用不同药物的病人钠钾含量指标; 图形显示服用drugY的病人,其唾液中的K含量明显低于其他类病人,由此可见,单纯K含量较低的病人选用drugY比较理想。
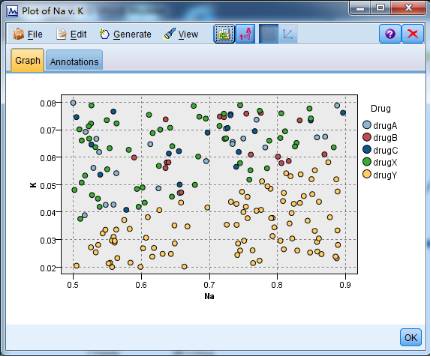
4.通过直方图反应钠钾浓度指标(Na/K)与服用对应药物的关系。图形显示,对于Na/K比值处在高水平的病人,drugY是理想的选择。
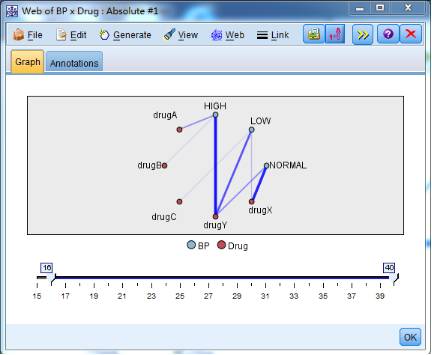
5.通过网状图反映不同血压特征病人的药物选择。图中线条粗细反映病人的BP与选用drug的情况。可以看到,无论血压状况如何,都可以服用drugY。
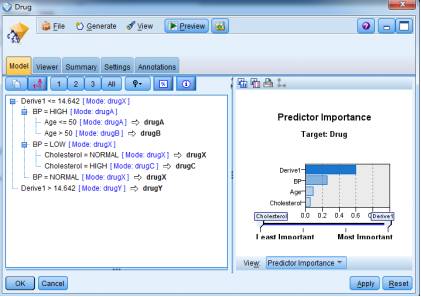
6.通过建立模型C5.0,从年龄、性别、血压、钠钾浓度指标的综合角度分析选择不同药物的依据。 根据图形显示,可以看出:Na/K比值是选择药物的首要考虑因素,其次是血压、年龄、和胆固醇水平。其中性别对药物选择没有影响。
SPSS Modeler数据挖掘实战案例培训,张文彤老师主讲!
培训时间:
2017年5月19日-5月21日(3天)
培训地点:
上海市闵行区古北路1838号创新园区3号楼
培训费用:
现场班:3600元/人,全日制在校学生(不含博士)2800元/人
直播班:2600元/人,全日制在校学生(不含博士)8折优惠。
PS:现场限额20人
(案例部分)
案例1:
商贸数据库整理
案例2:
直邮客户分析
案例3:
药物选择决策支持
案例4:
超市商品购买关联分析
案例5:
淘宝大卖家之营销数据分析
案例6:
住院费用影响因素挖掘(略讲)
案例7:
电信行业流失分析
案例8:
信用评分方法
案例9:
保险业欺诈发现
案例10:
网络挖掘(略讲)
本课程需要学员熟悉Windows系统的基本操作。
本课程的重点在应用Modeler进行数据挖掘的实战分析,因此要求学员已经具有基本的统计理论基础(正态分布、标准差、t检验等),并了解数据管理方面的一些基本知识。
学员不要求事前学习过IBM SPSS Modeler,但如能在课前对该软件的基本操作加以了解,将会大大有利于课程的进行。
点击
阅读原文
,报名课程!
曹老师
电话:
010-53605625
手机:
18810531180(微信)
QQ:
2881989706
邮箱:
[email protected]





