*本文仅为部分摘要,请点击文章底部“阅读全文”查看原文。
Today, many companies use big data to make super relevant recommendations and growth revenue. Among a variety of recommendation algorithms, data scientists need to choose the best one according a business’s limitations and requirements.
To simplify this task, the Statsbot team has prepared an overview of the main existing recommendation system algorithms.
Collaborative filtering
Collaborative filtering (CF) and its modifications is one of the most commonly used recommendation algorithms. Even data scientist beginners can use it to build their personal movie recommender system, for example, for a resume project.
When we want to recommend something to a user, the most logical thing to do is to find people with similar interests, analyze their behavior, and recommend our user the same items. Or we can look at the items similar to ones which the user bought earlier, and recommend products which are like them.
These are two basic approaches in CF: user-based collaborative filtering and item-based collaborative filtering, respectively.
In both cases this recommendation engine has two steps:
-
Find out how many users/items in the database are similar to the given user/item.
-
Assess other users/items to predict what grade you would give the user of this product, given the total weight of the users/items that are more similar to this one.
-
What does “most similar” mean in this algorithm?
All we have is a vector of preferences for each user (row of the matrix R) and the vector of user ratings for each product (columns of the matrix R).
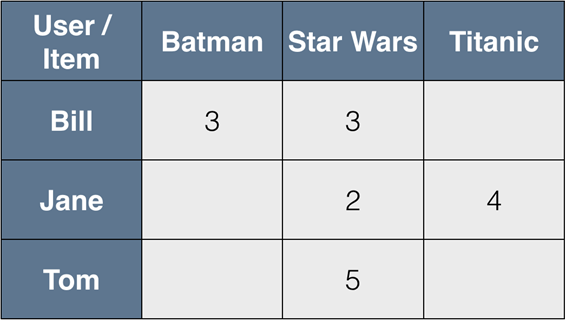
First of all, let’s leave only the elements for which we know the values in both vectors.
For example, if we want to compare Bill and Jane, we can mention that Bill hasn’t watched Titanic and Jane hasn’t watched Batman until this moment, so we can measure their similarity only by Star Wars. How could anyone not watch Star Wars, right? :)
The most popular techniques to measure similarity are cosine similarity or correlations between vectors of users/items. The final step is to take the weighted arithmetic mean according to the degree of similarity to fill empty cells in the table.
本文转载自 爱可可-爱生活 ,如有侵权请联系删除。





