传统年代的数据,产生于电脑桌前,互联网开始时候的数据量,虽然也有时间变量,但量少,用 RMDBS 可以满足管理的需求.
但从现在开始,物联网,移动端,每一样东西都开始产生数据,并且有记录下来的可能,我们用来分析,诊断,交流。数据可能来自于: 手机,汽车,纳米机器人,电冰箱,床,牙刷,咖啡杯,路面传感器,等等。互联网,产生数据的是人;物联网,产生数据的是机器。
那么时序数据是不是仅仅在传统的数据库字段里面加上了时间戳数据?
是,也不是。
以往的数据表里面,一般也是带有时间戳的,但是,当数据量变达到某个量级的时候,就已经是质变了,需要不同的技术手段来应对。主要的是以下几种:
-
基于 K/V 数据库构建:opentsdb(基于 hbase,LSM tree 存储),blueflood,kairosDB(基于 cassandra),influxdb,prometheus(基于 leveldb)[6];
-
基于搜索引擎来存储时序数据:ElasticSearch;
-
基于 B+ 树类型的存储:influxDB,采用变种的 LSM tree,他叫做 TSM,通过 timestamp 的对齐和 tag 组合 hash 来分摊负载;
-
基于关系型数据库构建:mysql,postgresql ,其实本质上和上面的一样,就是基于 B+ 类的数据存储都。但如果量大,那么就需要改装。Facebook 就是用传统的 postegre 数据库改装成了满足时序数据读写要求的数据库;[6]
时序数据的具体特征如下:
-
每秒数十万的数据涌入是常态,大集群环境下每秒钟上千万数据点的写入;
-
要求近实时的查询近期的热点数据;
-
数据从不同地点的采集点传输过来,早发生的数据不一定早到达,简言之就是乱序入库 ;
-
以时间截面为主,其他维度数据为辅 ;
-
要求对数据具备聚合能力,可以采用入库阶段的物化视图来加速这种聚合,也可以采用实时聚合,在查询时完成;
-
已发生的数据不会更改,更不会删除,保留所有数据轨迹;
以交通管控为例,下班高峰期,在丰台的 6 点整数据为 2 万条,一秒后,朝阳区发生的数据为 10 万条,这 10 万条虽然晚了一秒,但由于朝阳区距离数据中心更近,量更大,这十万条的入库顺序就在丰台区的 2 万条之前,时间戳上表现就是局部逆序存储,但是整体是有序的。
他的主要业务用途是以下几个方面:
-
场景回放:这在事故调查,情景分析等决策阶段的需求很广泛;
-
分析统计:常用于总结阶段性的工作成果,统一汇总后能从数据层面发现问题;
-
周期预测:从已有的周期规律中,结合当下环境,估计下一个同样事件的发生概率,这在交通拥堵治理,金融政策制定,市政管理,气象等等领域非常常用;
-
定点跟踪:跟踪某个主题的时序数据,例如“朝阳”区的空气按分钟的检测数据,它和全国其他所有 10000 个区县存在一起,当我们需要某几个区县比对数据的时候,需要在毫秒级别能查询出来;
时序数据来源于广泛的公共服务领域,例如以下场景:
-
公共安全:刑侦、情报分析,个体跟踪,区间筛选;
-
公共卫生:大面积传染病监控预警,药品使用监控,病理指标跟踪,病例特征预警;
-
物联网:城市管网数据,例如水文环境监测,空气质量 pm2.5 检测,地质环境监测;
-
金融行业:交易记录,存取记录,交易跟踪,欺诈模式检测,违规交易跟踪;
-
能源行业:城市用电量数据,高峰预警,阶梯计价,故障检测,城市油气消耗(加油站);
-
交通行业:交通实时路况,路口流量监测,车牌检测;
-
互联网行业:用户访问日志、广告点击日志;
-
物流行业:配送记录数据;
-
制造业:生产过程管控,流程效率分析数据采集,供应链实时数据采集;
LunarBase 是专门为海量数据的存储和大吞吐量的查询设计的. 用 C 语言和 java 开发而成,采用了数据库引擎和搜索引擎的融合设计,这无疑能够大大的简化生产环境,因为不需要为了不同的数据类型专门维护一套集群了。它为应用提供以下的基础功能:
-
数据库引擎,数据存储,列存储,标准 CRUD 操作;
-
Sql 标准查询;
-
搜索引擎 [3]:LunarBase 为全文本字段做索引,和 Lucene,Sphinx 类似;
-
实时计算 [2]:充分的利用机器资源,自主的回收物理资源,包括磁盘和内存;
-
Logger 日志:关闭实时计算,关闭全文搜索,LunarBase 就能作为一个日志系统,顺序的插入记录。这在机械磁盘上的性能是非常高效的;
-
嵌入分布式框架:嵌入 Presto 或者 Spark,能够使用标准的 SQL 语言来查询 LunarBase。
-
分布式集群:Lunar-node 是利用 Lunarbase 作为内核的服务器版本,通过虚拟节点达到 Scale out,用户可以使用两端提交的方式实现事务,也可以用消息系统来实现,这取决于业务的形式;
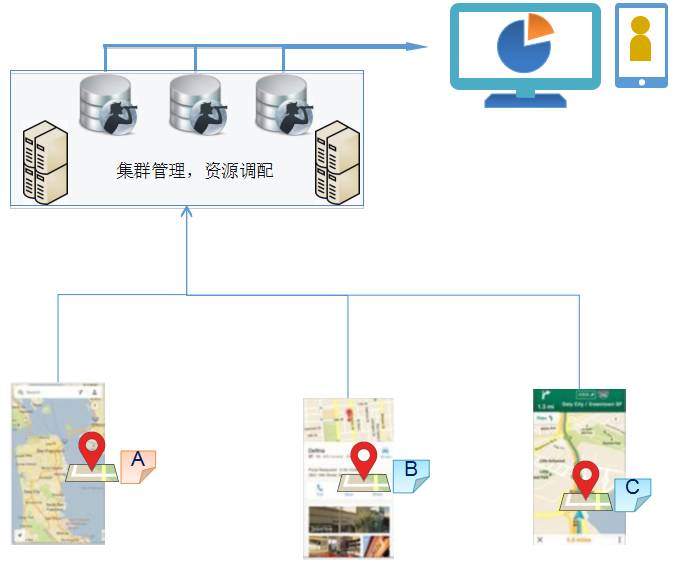
在公共安全领域中,经常需要追踪某个电话,某个车牌的最近轨迹,这就属于个体跟踪,例如在案发的时候,某个电话在前后 10 分钟内收到和打出的电话记录。在环境监测应用中,调取某个区县的空气质量数据,把某几个区县的时间线做比对,发现问题所在,等等。
具体的技术就是 Lunarbase 提供的分布式的搜索引擎和聚合分析的整合使用。
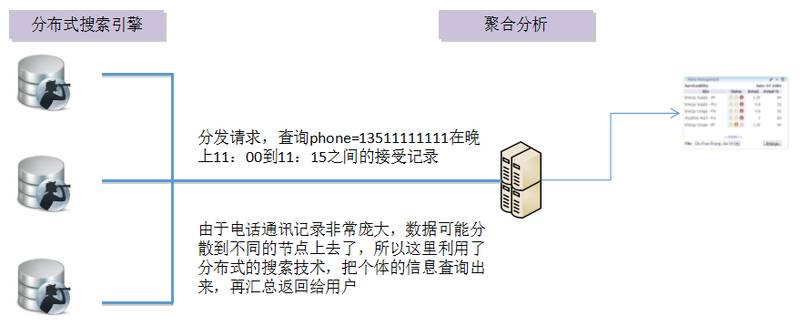
传统的数据库技术,在几十亿条数据里面做这种点查询,一般就歇菜了,具备搜索引擎技术的产品不多,Lucene,ElasticSearch(内核使用 lucene),sphinx 等等都是优秀的产品,但后面我们会提到他们在数值范围查询上面的无能为力。
搜索引擎是采用 inverted table 的形式来索引某个具体点的信息,这在文本检索里面很常用,例如要查询某个关键词出现的所有网页。这种索引具备访问磁盘次数少,吞吐量大的优点。LunarBase 和 ElasticSearch 一样,都实现了这种按列索引的模块,虽然原理相同,但是实现方式还是有很大的不同。这很好理解,比如:洛克希德马丁的 F22 使用的航空发动机和苏 35 的发动机肯定是不一样的工艺。
时序数据主要用到以下的概念,和传统数据库都能对应上:
吞吐量的基本要求:
30 个 pc 服务器的集群,每秒插入数据点要求在千万级,数据点通常比较短,通常几十个字节,这是和其他数据应用不大一样的地方。
复杂查询响应要求在秒级。
对于时序数据,时间戳是整体有序,局部乱序的(例如第一节的交通管控的例子)。如果用 RMDBS 的 B+ 树,或者其变种 LSTM 等等,速度上不会慢多少,也可以对付一般的应用。但如果是要时间线中抽取某几个 tag 的时间线,用 B 树类的就不合适了,tag 的标签绝对是乱序的,而且同一标签会有海量的时间点数据。如果加上不同 tag 的比对,这对底层的查询存储设计的考验就很大。搜素引擎的技术是很适合这个应用的。
LunarBase 里面对于数值型的数据采用了 LunarMax 实时计算模块 [2],LunarBase 根据数据类型,会建立不同的索引,对于范围查询,主要由里面的 LunarMax 实时计算模块支持,只需要在配置文件中,把实时模式打开就行:
rt_mode = on
然后指定 LunarBase 为每个列索引最多使用多少内存:
rt_virtual_mem_enabled = onrt_vm_swap = /home/DBTest/Swaprt_max_memory = 28
从上到下,首先打开虚拟内存,然后指定虚存使用的 swap 空间,用户的服务器环境可能会运行多种服务,每个都在争抢资源,那么 LunarBase 的这个设计就很贴心,用户可以通过最后的这个 rt_max_memory,告诉 LunarBase,对每个需要实时查询的列,最多使用多少物理内存,比如 256M 的物理内存,这就限制住了 LunarBase 自身的内存消耗。需要更多,就使用交换空间的,通过指定一块(固态)硬盘空间来作为大的虚拟内存使用,比如 100GB,一般都是够用了。
这一点和操作系统的内存管理一样,LunarBase 使用自己的虚拟内存管理系统,这块空间是独占的,不和操作系统争抢。
同时搜索引擎一样会产生的磁盘垃圾。因为目前的科技而言,存储主要使用的是块设备,碎片是无法避免的。有些解决方案通过定期的整理磁盘块来减少碎片,提高检索效率,有的把它叫做 compaction,或者其他的,目的是类似的,把垃圾去掉,把有关的放到一起,利于查询。但是在整理期间,搜索性能是很受影响的。LunarMax 是通过一种主动搜集整理的技术,均摊了清除碎片的开销,这一点对于生产环境是非常贴心的功能。
环境
:
运行总共 10 个虚拟机节点,每个运行 Ubuntu,分布运行在 3 台 pc 服务器上。每个节点分配 4GB 内存和 100GB 存储空间,节点间通过虚拟网卡通讯,客户端在同一局域网内发送数据。这是一个很低的配置:
CPU:
[rocku@iz25dXXXsuZ ~]$ cat /proc/cpuinfo
vendor_id : GenuineIntel
cpu family : 6
model : 62
model name : Intel(R) Xeon(R) CPU E5-2650 v2 @ 2.60GHz
stepping : 4
cpu MHz : 2593.427
cache size : 20480 KB
Memory:
[rocku@iz25dXXXsuZ ~]$ grep MemTotal /proc/meminfo
MemTotal: : 3921020KB
OS:
[rocku@iz25dXXXsuZ ~]$ uname -a
Linux iz25dXXXsuZ 2.6.32-573.18.1.e16.x86_64
GCC:
[rocku@iz25dXXXsuZ ~]$ gcc -v
gcc version 4.8.4 (GCC)
JAVA:
[rocku@iz25dXXXsuZ ~]$ java -version
java version 1.8.0_60
Java(TM) SE Runtime Enviroment (build 1.8.0_60-b27)
Java HotSpot(TM) 64-bit Server VM (build 25.60-b23, mixed mode)
数据:
模拟全国环境监测数据,每十毫秒的数据点(大约 10 个)拼成一条,总长度平均约 1000 字节。tag 10000 个区县的名称,总共 20 亿个数据点,附加列标注了该数据是否超过阈值,这是在客户端取好发送过来的。数据是这样的:
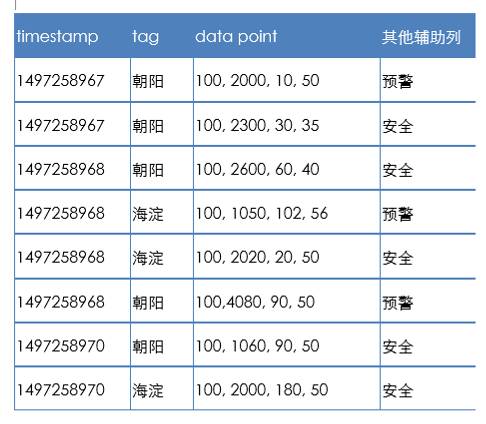
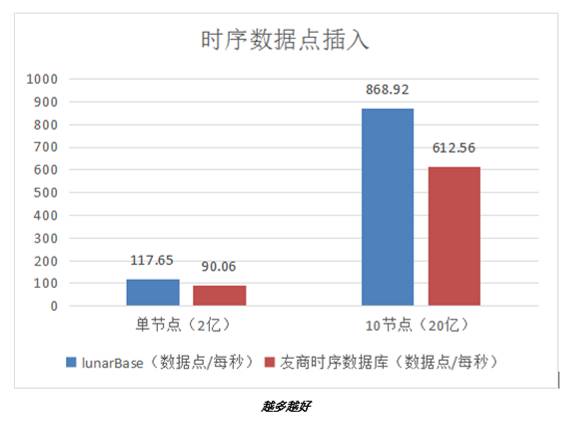
我们用另一时序数据库做了同样的一组数据。 分别做 10 次平均值。
LunarBase 在单节点的测试数据是 118 万个数据点 / 每秒,10 节点集群:815 万个数据点 / 每秒。
在查询提取 tag 数据,数据发送到所有 10 个节点做查询,提取朝阳,海淀,东城等等 tag 的数据,查询 10000 次做平均:
查询:
单 tag 提取,按时间戳排序:最大:67.35ms最小:0.05ms平均:3ms
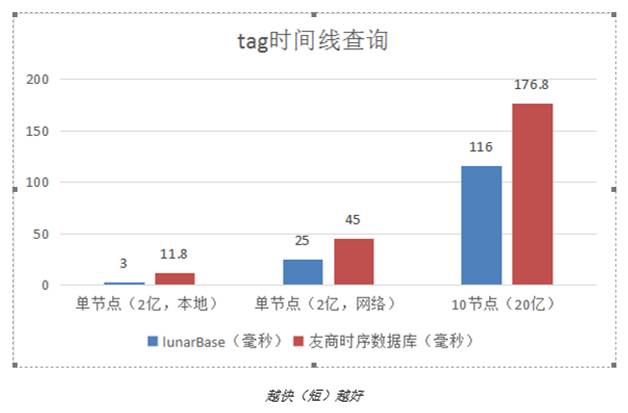
可以看到在 20 亿数据的查询中,时间花在了网络和聚合的处理上。在实际的案例中,推荐使用 infiniBand 来加速局域网的通讯。
关于 LunarBase 如何对数据做分片,做分布式的谓词下推,聚合下推来优化查询,我们会在后续的文章中陆续介绍。
参考文献
[1] LunarBase 白皮书:https://github.com/LunarBaseEngin/LunarBase/blob/master/LunarBase%20--%20A%20database%20engin%20for%20managing%20very%20large%20amounts%20of%20data%20--%20EN%20--V0.8.pdf
[2] LunarMax 实时计算系统:https://github.com/LunarBaseEngin/LunarBase/wiki/Real-Time-Analysis:-LunarMax
[3] LunarBase 搜索引擎:https://github.com/LunarBaseEngin/LunarBase/wiki/insert-to-search-engine
[4] LunarBase official benchmark:https://github.com/LunarBaseEngin/LunarBase/wiki/BenchMark
[5] LunarBase 五分钟入门:https://github.com/LunarBaseEngin/LunarBase/blob/master/README.md
[6] 时间序列数据库的秘密(1):http://www.infoq.com/cn/articles/database-timestamp-01
原文:https://github.com/LunarBaseEngin





