前言
前面看了一些Tensorflow的文档和一些比较有意思的项目,发现这里面水很深的,需要多花时间好好从头了解下,尤其是cv这块的东西,特别感兴趣,接下来一段时间会开始深入了解ImageNet比赛中中获得好成绩的那些模型: AlexNet、GoogLeNet、VGG(对就是之前在nerual network用的pretrained的model)、deep residual networks。
ImageNet Classification with Deep Convolutional Neural Networks
ImageNet Classification with Deep Convolutional Neural Networks 是Hinton和他的学生Alex Krizhevsky在12年ImageNet Challenge使用的模型结构,刷新了Image Classification的几率,从此deep learning在Image这块开始一次次超过state-of-art,甚至于搭到打败人类的地步,看这边文章的过程中,发现了很多以前零零散散看到的一些优化技术,但是很多没有深入了解,这篇文章讲解了他们alexnet如何做到能达到那么好的成绩,好的废话不多说,来开始看文章
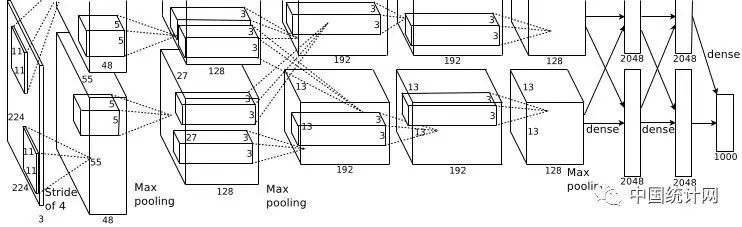
这张图是基本的caffe中alexnet的网络结构,这里比较抽象,我用caffe的draw_net把alexnet的网络结构画出来了
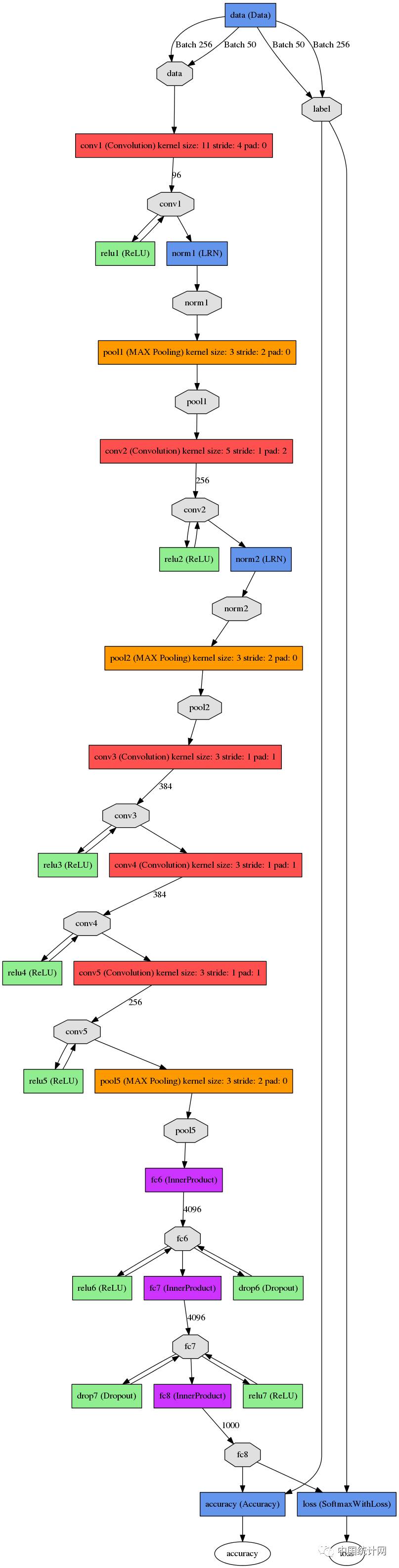
AlexNet的基本结构
alexnet总共包括8层,其中前5层convolutional,后面3层是full-connected,文章里面说的是减少任何一个卷积结果会变得很差,下面我来具体讲讲每一层的构成:
第一层卷积层 输入图像为227*227*3(paper上貌似有点问题224*224*3)的图像,使用了96个kernels(96,11,11,3),以4个pixel为一个单位来右移或者下移,能够产生5555个卷积后的矩形框值,然后进行response-normalized(其实是Local Response Normalized,后面我会讲下这里)和pooled之后,pool这一层好像caffe里面的alexnet和paper里面不太一样,alexnet里面采样了两个GPU,所以从图上面看第一层卷积层厚度有两部分,池化pool_size=(3,3),滑动步长为2个pixels,得到96个2727个feature。
第二层卷积层使用256个(同样,分布在两个GPU上,每个128kernels(5*5*48)),做pad_size(2,2)的处理,以1个pixel为单位移动(感谢网友指出),能够产生27*27个卷积后的矩阵框,做LRN处理,然后pooled,池化以3*3矩形框,2个pixel为步长,得到256个13*13个features。
第三层、第四层都没有LRN和pool,第五层只有pool,其中第三层使用384个kernels(3*3*384,pad_size=(1,1),得到384*15*15,kernel_size为(3,3),以1个pixel为步长,得到384*13*13);第四层使用384个kernels(pad_size(1,1)得到384*15*15,核大小为(3,3)步长为1个pixel,得到384*13*13);第五层使用256个kernels(pad_size(1,1)得到384*15*15,kernel_size(3,3),得到256*13*13,pool_size(3,3)步长2个pixels,得到256*6*6)。
全连接层: 前两层分别有4096个神经元,最后输出softmax为1000个(ImageNet),注意caffe图中全连接层中有relu、dropout、innerProduct。
(感谢AnaZou指出上面之前的一些问题) paper里面也指出了这张图是在两个GPU下做的,其中和caffe里面的alexnet可能还真有点差异,但这可能不是重点,各位在使用的时候,直接参考caffe中的alexnet的网络结果,每一层都十分详细,基本的结构理解和上面是一致的。
AlexNet为啥取得比较好的结果
前面讲了下AlexNet的基本网络结构,大家肯定会对其中的一些点产生疑问,比如LRN、Relu、dropout, 相信接触过dl的小伙伴们都有听说或者了解过这些。
这里我讲按paper中的描述详细讲述这些东西为什么能提高最终网络的性能。
ReLU Nonlinearity
一般来说,刚接触神经网络还没有深入了解深度学习的小伙伴们对这个都不会太熟,一般都会更了解另外两个激活函数(真正往神经网络中引入非线性关系,使神经网络能够有效拟合非线性函数)tanh(x)和(1+e^(-x))^(-1),而ReLU(Rectified Linear Units) f(x)=max(0,x)。
基于ReLU的深度卷积网络比基于tanh的网络训练块数倍,下图是一个基于CIFAR-10的四层卷积网络在tanh和ReLU达到25%的training error的迭代次数:
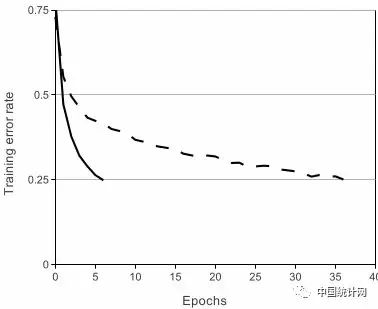
实线、间断线分别代表的是ReLU、tanh的training error,可见ReLU比tanh能够更快的收敛
Local Response Normalization
使用ReLU f(x)=max(0,x)后,你会发现激活函数之后的值没有了tanh、sigmoid函数那样有一个值域区间,所以一般在ReLU之后会做一个normalization,LRU就是文中提出(这里不确定,应该是提出?)一种方法,在神经科学中有个概念叫“Lateral inhibition”,讲的是活跃的神经元对它周边神经元的影响。
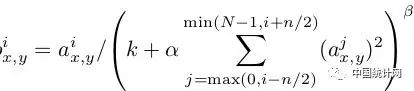
Dropout
Dropout也是经常挺说的一个概念,能够比较有效地防止神经网络的过拟合。
相对于一般如线性模型使用正则的方法来防止模型过拟合,而在神经网络中Dropout通过修改神经网络本身结构来实现。对于某一层神经元,通过定义的概率来随机删除一些神经元,同时保持输入层与输出层神经元的个人不变,然后按照神经网络的学习方法进行参数更新,下一次迭代中,重新随机删除一些神经元,直至训练结束
Data Augmentation
其实,最简单的增强模型性能,防止模型过拟合的方法是增加数据,但是其实增加数据也是有策略的,paper当中从256*256中随机提出227*227的patches(paper里面是224*224),还有就是通过PCA来扩展数据集。
这样就很有效地扩展了数据集,其实还有更多的方法视你的业务场景去使用,比如做基本的图像转换如增加减少亮度,一些滤光算法等等之类的,这是一种特别有效地手段,尤其是当数据量不够大的时候。
文章里面,我认为的基本内容就是这个了,基本的网络结构和一些防止过拟合的小的技巧方法,对自己在后面的项目有很多指示作用。





