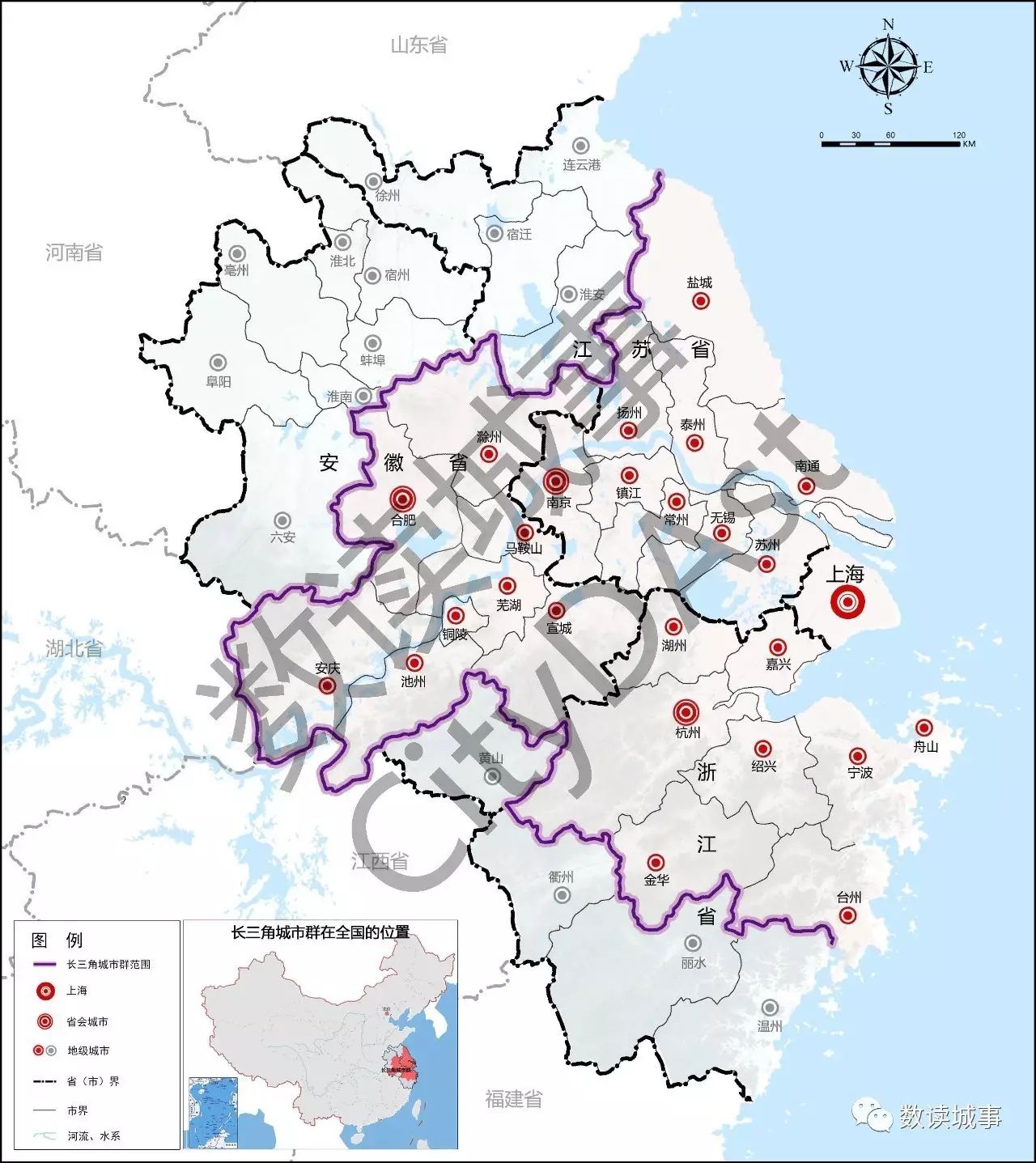
长三角城市群
在上海市、江苏省、浙江省、安徽省范围内,由以上海为核心、联系紧密的多个城市组成,主要分布于国家“两横三纵”城市化格局的优化开发和重点开发区域。
范围包括:上海市,江苏省的南京、无锡、常州、苏州、南通、盐城、扬州、镇江、泰州,浙江省的杭州、宁波、嘉兴、湖州、绍兴、金华、舟山、台州,安徽省的合肥、芜湖、马鞍山、铜陵、安庆、滁州、池州、宣城等26市,国土面积21.17万平方公里,2014年地区生产总值12.67万亿元,总人口1.5亿人,分别约占全国的2.2%、18.5%、11.0%。
▲
长三角城市群范围
图片来源:《长江三角洲城市群发展规划》
微博签到数据的可视化
主页菌获取了江苏省、上海市、安徽省和浙江省的微博签到数据,数据包括签到点名称,地址、类型、签到次数、签到照片数量等,几十万条吧大概==反正就是有点卡想换电脑那种。

▲
微博签到数据示例
将微博签到数据空间化落在地理空间上,选择适合的符号系统,呈现出来的效果类似于夜间灯光数据集,或许这张图也可以叫做「微博签到点亮长三角」。
在图里我们可以看到,数据最为集中的区域主要是长江沿线以及环杭州湾一带,也可以大概看出长三角城市群内核心区域的大概范围。
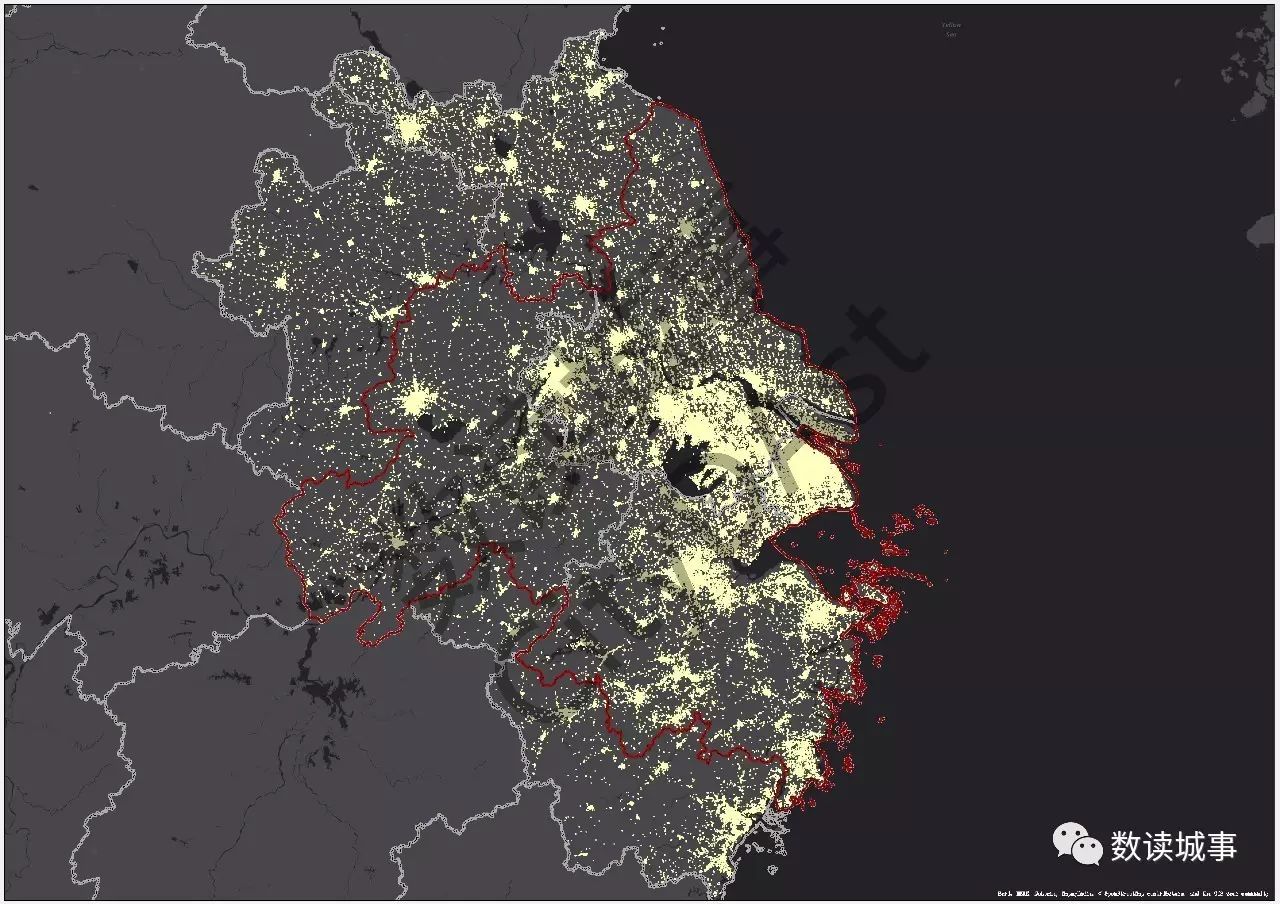
▲微博签到点亮长三角
主页菌通过对微博签到数据进行核密度分析,通过每个签到点的签到次数和签到照片数量进行计算得到每个签到点的网络活力:
网络活力=签到次数+1.5*签到照片数量
每个点的网络活力作为核密度分析的权重值,计算半径为1000米。(主页菌认为签到同时拍照比单纯的签到具有更高的活力,因此乘以了1.5,这里还有待商榷)
特别注意到的是,上海——苏锡常都市圈的关系尤为紧密,上海——苏州——无锡——常州呈现出绵延连片的趋势,特别是县级市、小城镇在其中担当了相当重要的作用,昆山、常熟、张家港、江阴等地也显示出了较强的网络密度。
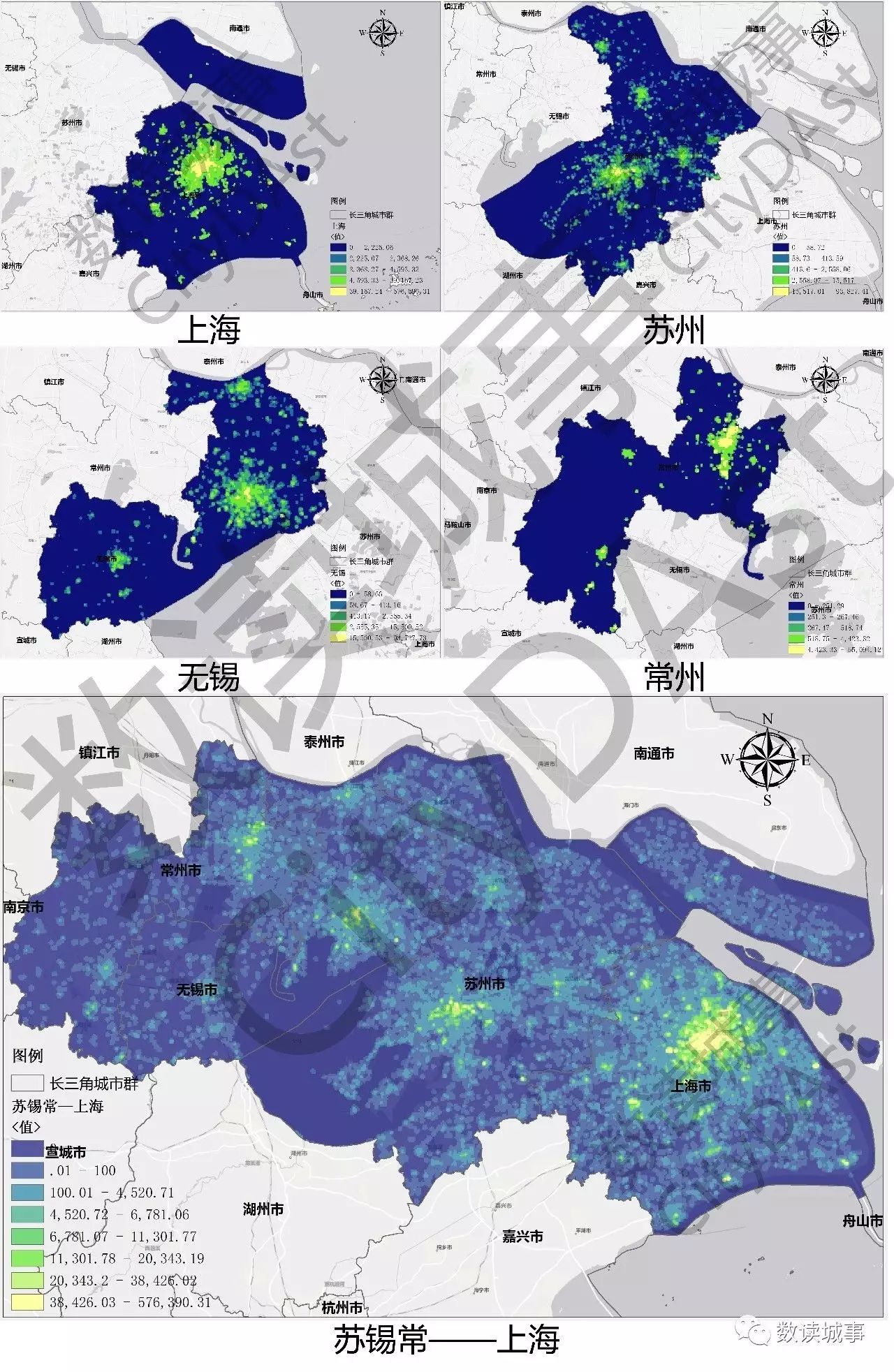
▲上海、苏州、无锡、常州微博签到密度
通过汇总将每个城市的网络活力的数值进行求和运算,得到每个城市的网络活力总量。总的来看,结果还是和经验认知相符的。
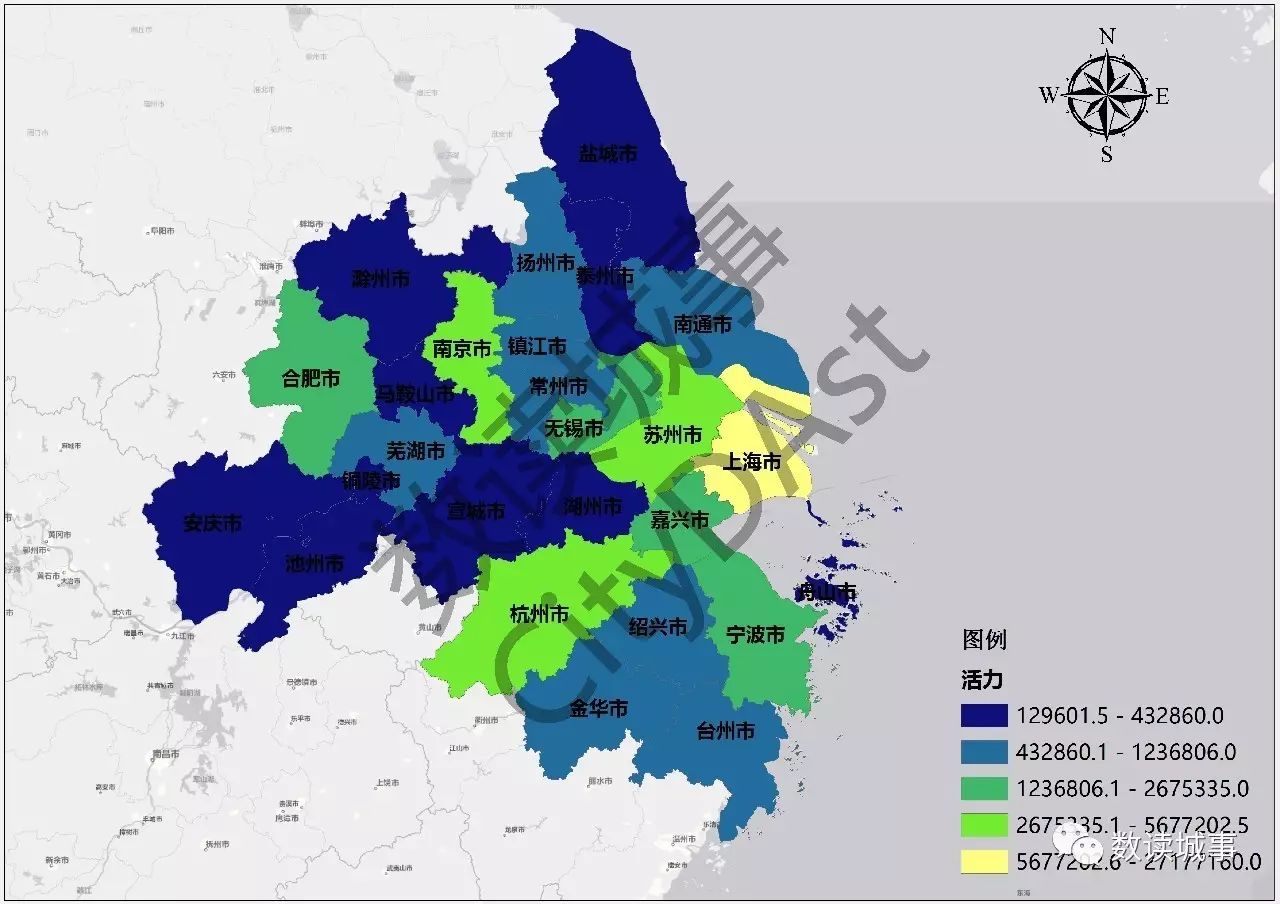 ▲
长三角城市群各城市网络活力总量
▲
长三角城市群各城市网络活力总量
长三角城市群经济基础条件
由于时间限制,主页菌仅选取了人口、人口密度、GDP和人均GDP这几个指标进行分析,资料来源于上海、浙江、安徽和江苏的2016统计年鉴,人口选择常住人口,这里仅进行最简化的经济基础条件的分析。
人口
从各城市的人口总量来看,呈现出沿海、沿江分布的特点,由于各市行政区划面积存在较大差异,需要比较人口密度的指标。
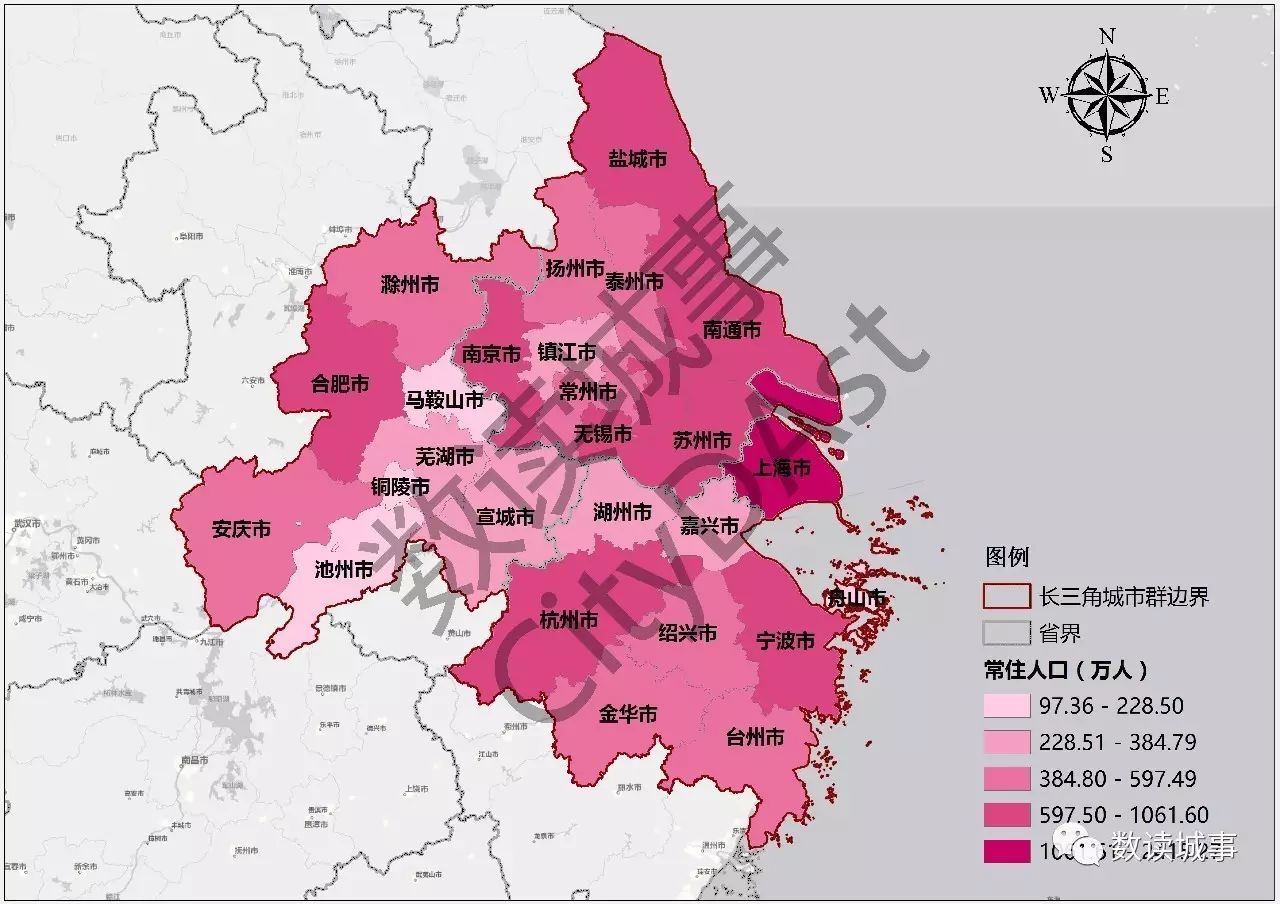
▲长三角城市群各城市常住人口数量(万人)
从人口密度分布情况来看,沿海沿江的特点更为明显,上海作为城市群内的中心城市,人口密度当之无愧位于第一,沿长江经济带的城市,特别是长江以南的苏州无锡等城市人口密度也相对较高。
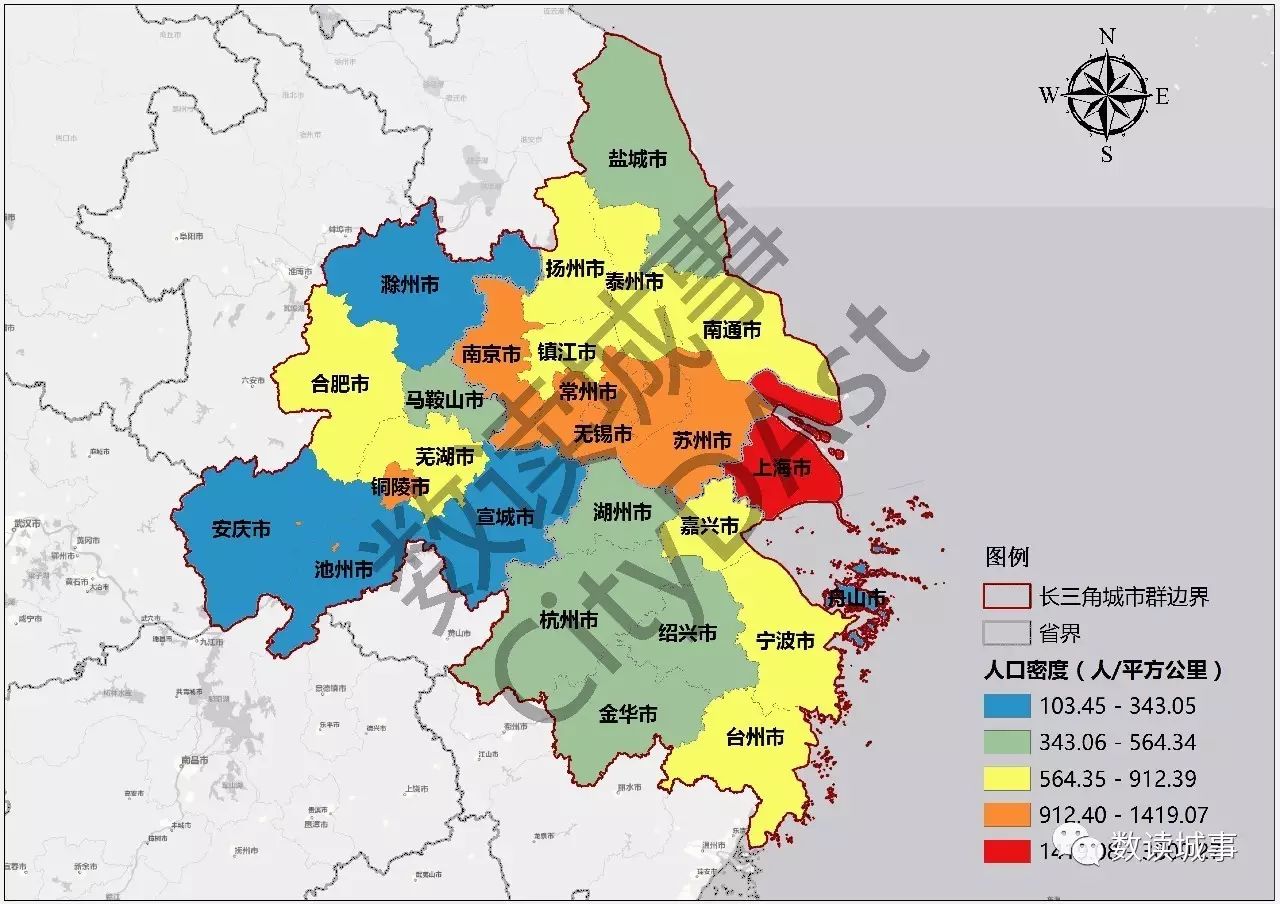
▲长三角城市群各城市人口密度(人/平方公里)
经济
从生产总值与人均生产总值情况来看,长三角城市群边缘城市的经济体量与核心城市存在较大差异。
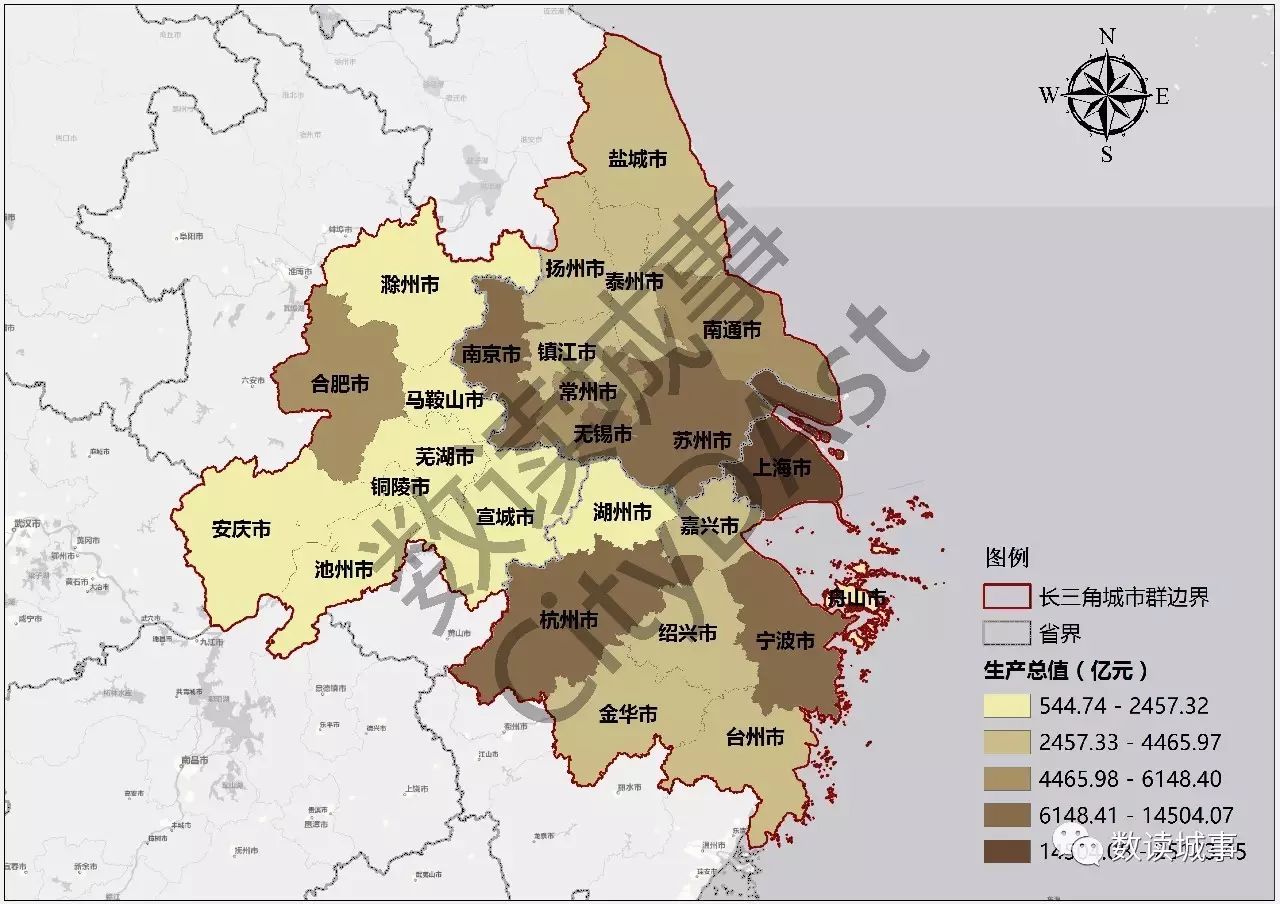
▲长三角城市群各城市地区生产总值(亿元)
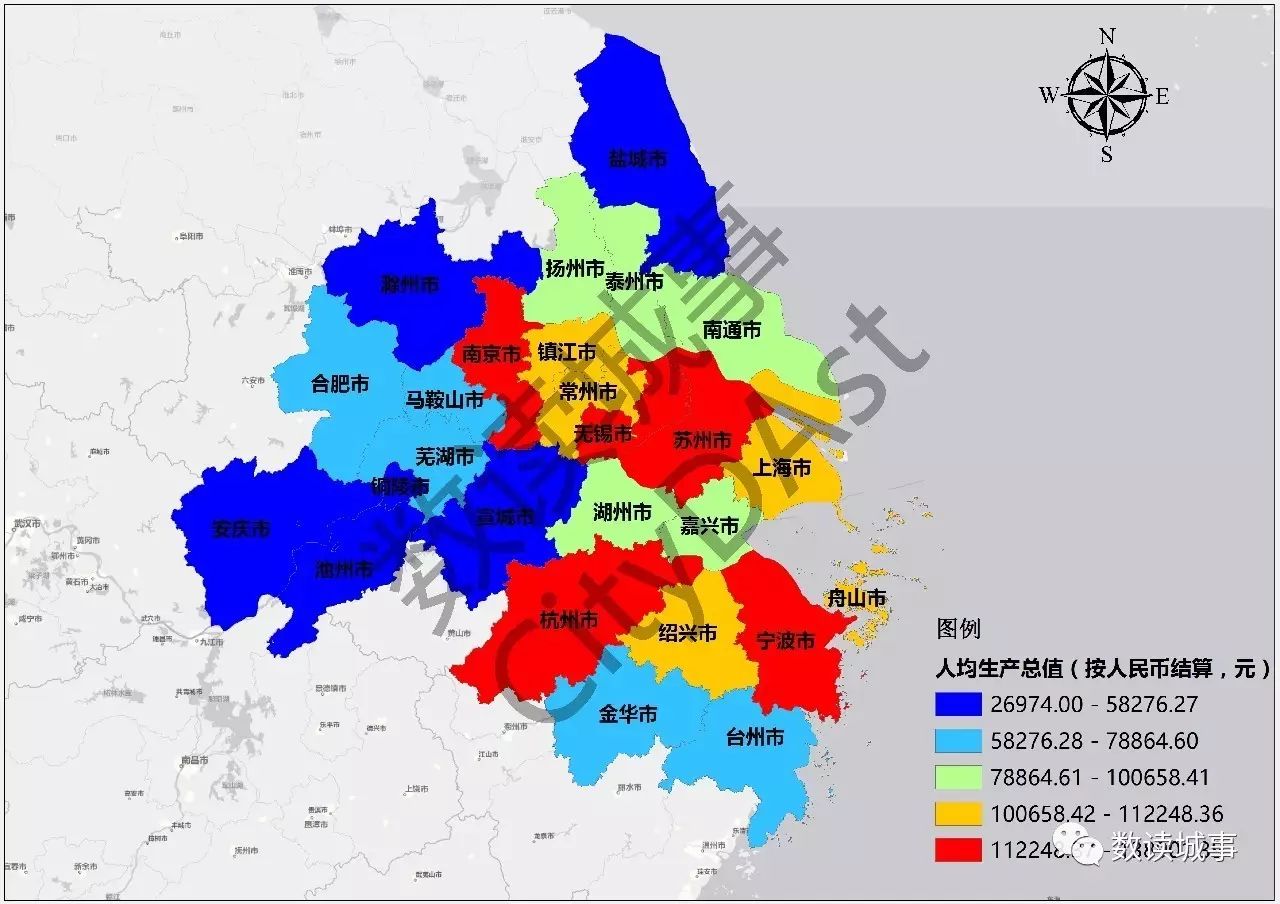
▲长三角城市群各城市人均生产总值(元)
案例
对于城市群内的城市等级划分,主页菌选取
K均值聚类算法
。
K均值聚类算法
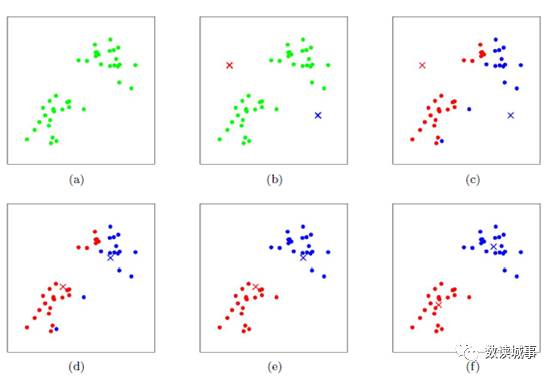
是先随机选取K个对象作为初始的聚类中心。然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。一旦全部对象都被分配了,每个聚类的聚类中心会根据聚类中现有的对象被重新计算。这个过程将不断重复直到满足某个终止条件。终止条件可以是没有(或最小数目)对象被重新分配给不同的聚类,没有(或最小数目)聚类中心再发生变化,误差平方和局部最小。
(以上内容来源于百度百科)
下图展示了对n个样本点进行K-means聚类的效果,这里
k取2
。
指标选取






