
近几年,人工智能计算机视觉技术在安防、工业制造等场景的产业智能化升级进程中发挥着举足轻重的作用。“人员进出管理”作为各行业中的关键场景,应用需求十分迫切。如居家防盗、机房管理以及景区危险告警等场景,需要对异常目标(人、车或其他物体)不经允许擅自进入规定区域进行及时检测。利用深度学习视觉技术,可以及时准确地对闯入行为进行识别并发出告警信息,切实保障人员的生命财产安全。相比传统人力监管的方式,不仅可以实现7X24小时不间断的全方位保护,还能极大地降低管理成本,解放劳动力。

但在真实产业中,要实现高精度的人员闯入识别不是一件容易的事,在实际场景中存在着各种问题,给准确识别带来了极大挑战:
-
场景复杂
:在实际场景中,摄像头采集到的图像会受到诸如光照、天气、植物、建筑等因素的干扰,即使同一场景在不同时间的图像形态差异也非常大,需要模型有极好的特征学习能力与泛化性才能”应对自如”。
-
性能要求极致
:为了保障目标区域的安全,当目标区域内出现异常侵入时须及时预警。然而出于对硬件成本及便携性的考虑,实际部署环境多为移动端或嵌入式设备,模型在追求高精度的同时,也必须具有极小的体积与极快的预测速度。
针对上述问题,本次飞桨产业实践范例库基于真实场景中的视频及图像数据,推出了重点区域人员闯入管控实践示例,提供从数据准备、技术方案、模型训练优化,到模型部署的全流程可复用方案,有效解决了不同光照、不同天气等室外复杂环境下的图像分类问题,并且极大地降低了数据标注和算力成本,适用于厂区巡检、家居防盗、景区管理等多个产业应用。
https://github.com/PaddlePaddle/PaddleClas/tree/develop/docs/zh_CN/samples/Personnel_Access
所有源码及教程均已开源,欢迎大家使用,star鼓励~
基于深度学习实现人员闯入管控任务要在室内和室外不同环境、不同拍摄角度以及不同光照条件下的人员闯入进行识别, 并且要求识别速度不低于35FPS才能进一步端侧移植,因此,如何在有限算力下实现高精度识别将会是入侵探测应用最核心的问题。
针对上述难点,充分考虑模型性能表现及部署支持后,最终选用了飞桨图像分类开发套件PaddleClas中的PP-LCNet模型作为基准模型,同时采用PaddleClas的超轻量图像分类方案(Practical Ultra Light Classification,简称PULC),实现对模型的快速优化,仅用超轻量模型就可实现与SwinTransformer模型接近的精度,同时预测速度提高50倍,极大地提升了部署性能。
https://github.com/PaddlePaddle/PaddleClas

图2
Paddle
Clas超轻量图像分类方案示意图
如上图所示,PaddleClas实用图像分类方案主要包括4种优化方式,具体说明如下:
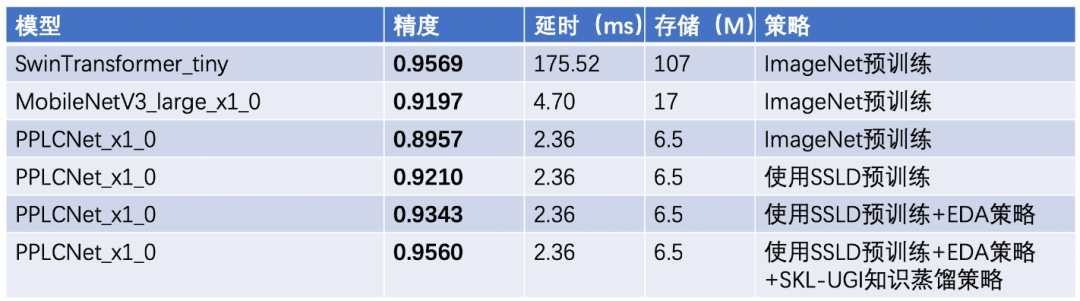
PP-LCNet作为针对CPU量身打造的骨干网络模型,在速度、精度方面均远超如MobileNetV3等同体量算法,在有人/无人场景中,速度较SwinTransformer的模型快50倍以上,较MobileNetV3 large 1.0快50%。
SSLD半监督蒸馏算法可以使小模型学习到大模型的特征和ImageNet22k无标签大规模数据的知识。在训练小模型时,使用SSLD预训练权重作为模型的初始化参数,可以使有人/无人分类模型有2.5个点的精度提升。
该方案融合了图像变换、图像裁剪和图像混叠3种数据增强方法中,并支持自定义调整触发概率,能使模型的泛化能力大大增强,提升模型在实际场景中的性能。模型可以在上一步的基础上,精度再提升1个多点。
SKL(symmetric-KL)在经典的KL知识蒸馏算法的基础上引入对称信息,提升了算法的鲁棒性。同时,该方案可以方便地在训练中加入无标签训练数据(Unlabeled General Image),可以进一步提升了模型效果。该算法可以使模型精度继续提升两个多点。
考虑到优化方案中的蒸馏策略需要挑选合适的模型作为教师模型,用来指导实际应用的小模型更好地进行特征学习。所以在模型训练部分主要分为三个阶段:
从github克隆PaddleClas项目,安装飞桨和其他依赖库,并下载数据集。
我们这里使用了PULC推荐的权重配置,运行以下命令,即可训练教师模型:

利用刚刚训练好的教师模型,我们可以快速训练轻量分类模型:

由于PaddleClas已经提供了完备易用的部署支持,在实际过程中只需要2步就能完成本地部署:




图3 实际运行效果示意图
PaddleClas是一个提供了从数据处理、模型准备、模型优化、到预测部署全流程工具的图像分类开发套件。
其中的轻量级图像识别系统PP-ShiTu更是综合了目标检测、图像分类、度量学习、图像检索等多重技术,能够完美解决小样本、高相似、多类别等产业落地难点,CPU上仅需0.2s轻松识别十万类,而且十分简单易用,极大地降低开发门槛。










