(点击上方公众号,可快速关注)
来源:伯乐在线专栏作者 - 纯洁的微笑
如有好文章投稿,请点击 → 这里了解详情
我们本身是一家互联网金融公司,公司的主流业务就是p2p,因为各种原因吧,15年底启动建设众筹平台。考虑到前期开发过程中的一些弊端和架构经验,本次架构引用了dubbo做soa服务的治理,web容器nginx+tomcat,后端语言采用java,框架选择spring+mybaits,前端模板引擎使用的是btl,app采用原生+h5的模式。这个架构可以参考我之前写的文章《从零到百亿互联网金融架构发展史》中的第三代系统架构,之前的文章主要介绍了架构的变迁,本篇文章主要介绍在第三代平台中遇到的问题以及解决方法。
首先介绍一下众筹系统的部署架构(如下图),网站和app请求都是首先到最前端的nginx,如果只是静态内容的访问nginx直接处理后返回;动态请求分别转发到后端的tomcat前端服务层,前端服务层只关注页面端业务逻辑不涉及数据库的操作,如果只是页面框架渲染以及不涉及数据库的请求,在前端服务层直接处理返回;如果涉及到数据库操作或者核心业务逻辑,前端服务层通过dubbo调用后端的接入层服务或者核心层服务。
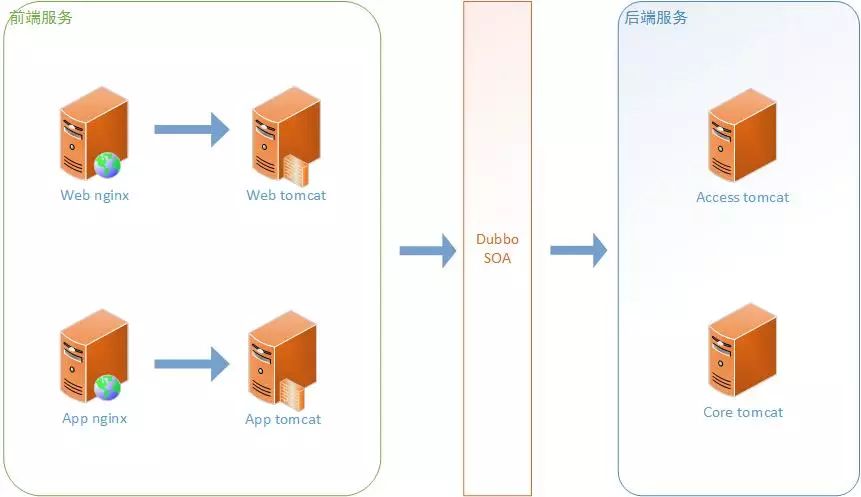
上线在生产测试期间,发现tomcat过一段时间就会莫名奇妙的down掉,特别是后端的tomcat down掉的频率比较高。后端的tomcat down掉之后对前端的页面展示没有影响,会影响后端的交易。
jvm参数配置
查看tomcat业务日志,报错如下:
2016-04-14 12:01:55,025 - org.jboss.netty.channel.DefaultChannelPipeline -59679839 [New I/O worker #29] WARN null - [DUBBO] An exception was thrown by a user handler while handling an exception event ([id: 0x5f980c11, /xxx:55386 => /xxx:6666] EXCEPTION: com.alibaba.dubbo.remoting.ExecutionException: class com.alibaba.dubbo.remoting.transport.dispatcher.all.AllChannelHandler error when process received event .), dubbo version: 2.8.4, current host: xxx
com.alibaba.dubbo.remoting.ExecutionException: class com.alibaba.dubbo.remoting.transport.dispatcher.all.AllChannelHandler error when process caught event .
at com.alibaba.dubbo.remoting.transport.dispatcher.all.AllChannelHandler.caught(AllChannelHandler.java:67)
at com.alibaba.dubbo.remoting.transport.AbstractChannelHandlerDelegate.caught(AbstractChannelHandlerDelegate.java:44)
at com.alibaba.dubbo.remoting.transport.AbstractChannelHandlerDelegate.caught(AbstractChannelHandlerDelegate.java:44)
at com.alibaba.dubbo.remoting.transport.AbstractPeer.caught(AbstractPeer.java:127)
at com.alibaba.dubbo.remoting.transport.netty.NettyHandler.exceptionCaught(NettyHandler.java:112)
at com.alibaba.dubbo.remoting.transport.netty.NettyCodecAdapter$InternalDecoder.exceptionCaught(NettyCodecAdapter.java:165)
at org.jboss.netty.channel.Channels.fireExceptionCaught(Channels.java:525)
at org.jboss.netty.channel.AbstractChannelSink.exceptionCaught(AbstractChannelSink.java:48)
at org.jboss.netty.channel.Channels.fireMessageReceived(Channels.java:296)
at com.alibaba.dubbo.remoting.transport.netty.NettyCodecAdapter$InternalDecoder.messageReceived(NettyCodecAdapter.java:148)
at org.jboss.netty.channel.Channels.fireMessageReceived(Channels.java:268)
at org.jboss.netty.channel.Channels.fireMessageReceived(Channels.java:255)
at org.jboss.netty.channel.socket.nio.NioWorker.read(NioWorker.java:88)
at org.jboss.netty.channel.socket.nio.AbstractNioWorker.process(AbstractNioWorker.java:109)
at org.jboss.netty.channel.socket.nio.AbstractNioSelector.run(AbstractNioSelector.java:312)
at org.jboss.netty.channel.socket.nio.AbstractNioWorker.run(AbstractNioWorker.java:90)
at org.jboss.netty.channel.socket.nio.NioWorker.run(NioWorker.java:178)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.lang.OutOfMemoryError: unable to create new native thread
at java.lang.Thread.start0(Native Method)
at java.lang.Thread.start(Thread.java:714)
at java.util.concurrent.ThreadPoolExecutor.addWorker(ThreadPoolExecutor.java:949)
at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1360)
at com.alibaba.dubbo.remoting.transport.dispatcher.all.AllChannelHandler.caught(AllChannelHandler.java:65)
... 19 more
查看output日志,发现其中有这么一句。
SEVERE: The web application [/xxx] appears to have started a thread named [DubboResponseTimeoutScanTimer] but has failed to stop it. This is very likely to create a memory leak.
根据日志提示貌似有内存泄露,以前确实还没有碰到过这个错误,一片迷茫。重新启动后,先用命令jstat -gc xxx 1000 30查看java 进程的gc情况,发现在30秒的世界内minor gc了n次,随怀疑年轻代内存配置少了,查看个区域内存的配置参数如下:
-Xms10g -Xmx10g -XX:PermSize=1g -XX:MaxPermSize=2g -Xshare:off -Xmn1024m
按照年轻代为堆内存为百分之三的原则修改为-Xmn4g,重新启动观察之后mimor gc的频率确实有所下降,测试大约过了3小时候之后又反馈tomcat down掉了,继续分析启动参数配置的时候发现了这么一句-XX:-+DisableExplicitGC,显示的禁止了System.gc(),但是使用了java.nio的大量框架中使用System.gc()来执行gc期通过full gc来强迫已经无用的DirectByteBuffer对象释放掉它们关联的native memory,如果禁用会导致OOM,随即怀疑是否是这个参数引发的问题,在启动参数中去掉它。
为了防止再次出现异常的时候能更加详细的分析堆内存的使用情况,在启动参数中添加了-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/usr/local/logs/java/,当tomcat down的时候让输出堆内存文件,一边也启动jvisualvm工具来实时的监控内存各个线程的使用情况。
数据库连接池
继续使用压测工具来压测,在压测的过程中发现名为com.mchange.v2.resourcepool.ssync.ThreadPoolAsynchronousRunner$PoolThred-#xxx的线程不断的增长,并且后台tomcat报错如下:
2016-04-13 16:55:15,175 - com.alibaba.dubbo.common.threadpool.support.AbortPolicyWithReport -83649035 [New I/O worker #27] WARN - [DUBBO] Thread pool is EXHAUSTED! Thread Name: DubboServerHandler-xxx:6666, Pool Size: 200 (active: 200, core: 200, max: 200, largest: 200), Task: 692 (completed: 492), Executor status:(isShutdown:false, isTerminated:false, isTerminating:false), in dubbo://xxx:6666!, dubbo version: 2.8.4, current host: xxx
2016-04-13 16:55:15,176 - com.alibaba.dubbo.common.threadpool.support.AbortPolicyWithReport -83649036 [New I/O worker #27] WARN - [DUBBO] Thread pool is EXHAUSTED! Thread Name: DubboServerHandler-xxx:6666, Pool Size: 200 (active: 200, core: 200, max: 200, largest: 200), Task: 692 (completed: 492), Executor status:(isShutdown:false, isTerminated:false, isTerminating:false), in dubbo://xxx:6666!, dubbo version: 2.8.4, current host: xxx
2016-04-13 16:55:15,177 - org.jboss.netty.channel.DefaultChannelPipeline -83649037 [New I/O worker #27] WARN - [DUBBO] An exception was thrown by a user handler while handling an exception event ([id: 0x2f345d45, /192.168.57.20:36475 => /xxx:6666] EXCEPTION: com.alibaba.dubbo.remoting.ExecutionException: class com.alibaba.dubbo.remoting.transport.dispatcher.all.AllChannelHandler error when process received event .), dubbo version: 2.8.4, current host: xxx
com.alibaba.dubbo.remoting.ExecutionException: class com.alibaba.dubbo.remoting.transport.dispatcher.all.AllChannelHandler error when process caught event .
at com.alibaba.dubbo.remoting.transport.dispatcher.all.AllChannelHandler.caught(AllChannelHandler.java:67)
at com.alibaba.dubbo.remoting.transport.AbstractChannelHandlerDelegate.caught(AbstractChannelHandlerDelegate.java:44)
at com.alibaba.dubbo.remoting.transport.AbstractChannelHandlerDelegate.caught(AbstractChannelHandlerDelegate.java:44)
at com.alibaba.dubbo.remoting.transport.AbstractPeer.caught(AbstractPeer.java:127)
at com.alibaba.dubbo.remoting.transport.netty.NettyHandler.exceptionCaught(NettyHandler.java:112)
at com.alibaba.dubbo.remoting.transport.netty.NettyCodecAdapter$InternalDecoder.exceptionCaught(NettyCodecAdapter.java:165)
at org.jboss.netty.channel.Channels.fireExceptionCaught(Channels.java:525)
at org.jboss.netty.channel.AbstractChannelSink.exceptionCaught(AbstractChannelSink.java:48)
at org.jboss.netty.channel.Channels.fireMessageReceived(Channels.java:296)
at com.alibaba.dubbo.remoting.transport.netty.NettyCodecAdapter$InternalDecoder.messageReceived(NettyCodecAdapter.java:148)
at org.jboss.netty.channel.Channels.fireMessageReceived(Channels.java:268)
at org.jboss.netty.channel.Channels.fireMessageReceived(Channels.java:255)
at org.jboss.netty.channel.socket.nio.NioWorker.read(NioWorker.java:88)
at org.jboss.netty.channel.socket.nio.AbstractNioWorker.process(AbstractNioWorker.java:109)
at org.jboss.netty.channel.socket.nio.AbstractNioSelector.run(AbstractNioSelector.java:312)
at org.jboss.netty.channel.socket.nio.AbstractNioWorker.run(AbstractNioWorker.java:90)
at org.jboss.netty.channel.socket.nio.NioWorker.run(NioWorker.java:178)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.util.concurrent.RejectedExecutionException: Thread pool is EXHAUSTED! Thread Name: DubboServerHandler-xxx:6666, Pool Size: 200 (active: 200, core: 200, max: 200, largest: 200), Task: 692 (completed: 492), Executor status:(isShutdown:false, isTerminated:false, isTerminating:false), in dubbo://xxx:6666!
at com.alibaba.dubbo.common.threadpool.support.AbortPolicyWithReport.rejectedExecution(AbortPolicyWithReport.java:53)
at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:821)
at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1372)
at com.alibaba.dubbo.remoting.transport.dispatcher.all.AllChannelHandler.caught(AllChannelHandler.java:65)
... 19 more
根据这些信息随怀疑数据库连接池有问题,为了更好的监控连接池的使用,因此前期使用c3p0也会出现的一些问题,所以我们决定将数据库连接池替换成druid,已经在别的项目中使用测试过,因此非常快速的更换投产。投产后继续用压测工具来测试,根据druid的后台监控页面发现(项目地址/druid/index.html),每次前端掉用一次数据库连接就加一次,执行完成之后数据库连接并没有释放。如下图红色区域,我们将数据库连接池调整成1000,不一会就占满了。
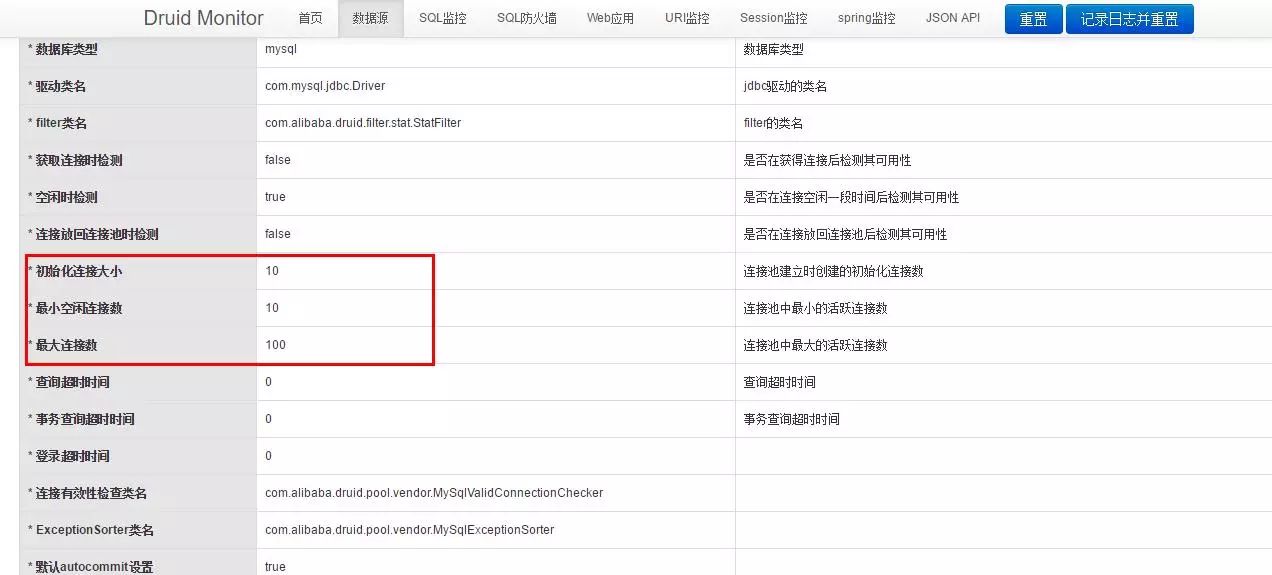
根据这些信息判断出,数据库执行sql后肯定没有释放数据库连接,导致数据库连接池用满后,后续的线程无法执行,检查代码之后发现果然有问题,请看下方代码,我们最先使用的是SqlSessionFactory,如果使用SqlSessionFactory,在执行完sql后必须要执行session.close()来关闭连接,才会被连接池重新回收。
public class SessionFactory {
@Resource
private SqlSessionFactory coreSqlSessionFactory;
protected SqlSession getSession() {
return coreSqlSessionFactory.openSession();
}
}
public class BaseDao extends SessionFactory{
public void add(Entity entity) {
this.getSession().update(entity.getClass().getSimpleName()+"."+Thread.currentThread().getStackTrace()[2].getMethodName(), entity);
}
}
但是使用SqlSessionTemplate却不用手动执行代码来关闭session,因此我们把上面SessionFactory类中的代码改成SqlSessionTemplate(如下),此问题便解决了。
public class SessionFactory {
@Resource
public SqlSessionTemplate coreSqlSession;
protected SqlSessionTemplate getSession() {
return coreSqlSession;
}
}
诡异的脚本
做完上面的优化之后,我们感觉问题应该解决了,但过了一段时间后tomcat又诡异的挂了,继续分析gc情况,分阶段使用jmap -dump:live,format=b,file=dump.hprof xxx命令生成堆转储快照来对比堆内存使用情况,监控线程使用情况,均发现没有问题。这个问题困扰了我们好几天,每天都监控这端口,一但发现tomcat down之后马上通知运营人员重启。一方面我们也查阅了各种资料,到网上查找各种tomcat自动down的原因,一一在我们服务器进行了测试、修复均不起作用。
终于在google各种tomcat down原因的时候发现了一篇Tomcat进程意外退出的问题分析,立刻想起了我们最近使用的一个脚本来,因为我们的tomcat禁止了通过bat文件来关闭,因此为了启动方便我们写了一个脚本文件,方便通过脚本来启动、停止、重启tomcat文件,这是这个脚本导致tomcat down的原因,不不,不叫原因叫元凶!脚本内容如下:
#!/bin/sh
# eg: tomcat.sh start xxx
#
proc_dir="/usr/local/xxx/tomcat-zc-web/bin"
proc_name=$2
if [ x$proc_name != x ]
then
proc_dir=${proc_dir//xxx/$proc_name}
fi
#echo $proc_dir
function stop () {
kill -9 `ps -ef |grep $proc_dir |grep -v grep|awk '{print $2}'`
}
function start () {
cd $proc_dir
./startup.sh
tail -300f /usr/local/logs/tomcat-business/$proc_name.log
}
case $1 in
start)
start;;
stop)
stop;;
restart)
stop
start;;
esac
就是因为tail -300f /usr/local/logs/tomcat-business/$proc_name.log这一句导致的问题,在别的项目使用的时候其实是没有这一句的,一般在使用的步骤是:
在这次投产的时候为了省一步操作,就将执行查看日志的命令,直接加在了启动命令的后面,当执行tomcat.sh start xxx这个命令的时候,即启动的tomcat,也自动会打印出tomcat的日志,那时候的想法非常好。
原因是,使用脚本命令启动后因为使用了tail -300f xxx 命令,tomcat的进程会成为shell脚本的子进程,这样的话,如过shell脚本停止的话,系统会自动杀掉tomcat进程导致tomcat down掉,在我们的脚本中去掉这条命令tomcat就正常了。最后感觉阿里的技术真的很牛X,那篇文章也是出自于阿里的员工。
经历这么些波折,后续的tomcat服务终于稳定了下来
看完本文有收获?请转发分享给更多人
关注「数据库开发」,提升 DB 技能

专栏作者简介 ( 点击 → 加入专栏作者 )
纯洁的微笑:一个热爱程序的人

打赏支持作者写出更多好文章,谢谢!








