
来源:Analytics Vidhya
编译:机器人圈公众号
人工智能,深度学习,机器学习—无论你在做什么,如果你对它不是很了解的话——去学习它。否则的话不用三年你就跟不上时代的潮流了。
——
Mark Cuban
马克.库班的这个观点可能听起来很极端——但是它所传达的信息是完全正确的! 我们正处于一场革命的旋涡之中——一场由大数据和计算能力引起的革命。
只需要一分钟,我们来想象一下,在20世纪初,如果一个人不了解电力,他/她会觉得如何?你会习惯于以某种特定的方式来做事情,日复一日,年复一年,而你周围的一切事情都在发生变化,一件需要很多人才能完成的事情仅依靠一个人和电力就可以轻松搞定,而我们今天正以机器学习和深度学习的方式在经历一场相似的旅程。
所以,如果你还没有探索或理解深度学习的神奇力量——那你应该从今天就开始进入这一领域。
如果你是一个想学习或理解深度学习的人,这篇文章是为你量身定做的。在本文中,我们将介绍深度学习中常用的各种术语。
如果你想知道我为什么要写这篇文章——
我之所以在写,是因为我希望你开始你的深度学习之旅,而不会遇到麻烦或是被吓倒。
当我第一次开始阅读关于深度学习资料的时候,有几个我听说过的术语,但是当我试图理解它的时候,它却是令人感到很迷惑的。而当我们开始阅读任何有关深度学习的应用程序时,总会有很多个单词重复出现。
在本文中,我为你创建了一个类似于深度学习的字典,你可以在需要使用最常用术语的基本定义时进行参考。我希望在你阅读这篇文章之后,你就不会再受到这些术语的困扰了。
为了帮助你了解各种术语,我已经将它们分成3组。如果你正在寻找特定术语,你可以跳到该部分。如果你是这个领域的新手,那我建议你按照我写的顺序来通读它们。
1.
神经网络基础
(Basics of Neural Networks)
常用激活函数(Common Activation Functions)
2.
卷积神经网络
(Convolutional Neural Networks)
3.
循环神经网络
(Recurrent Neural Networks)
神经网络基础
1)
神经元(Neuron)
——
就像形成我们大脑基本元素的神经元一样,神经元形成神经网络的基本结构。想象一下,当我们得到新信息时我们该怎么做。当我们获取信息时,我们一般会处理它,然后生成一个输出。类似地,在神经网络的情况下,神经元接收输入,处理它并产生输出,而这个输出被发送到其他神经元用于进一步处理,或者作为最终输出进行输出。
2)
权重(Weights)
——
当输入进入神经元时,它会乘以一个权重。例如,如果一个神经元有两个输入,则每个输入将具有分配给它的一个关联权重。我们随机初始化权重,并在模型训练过程中更新这些权重。训练后的神经网络对其输入赋予较高的权重,这是它认为与不那么重要的输入相比更为重要的输入。为零的权重则表示特定的特征是微不足道的。
让我们假设输入为a,并且与其相关联的权重为W1,那么在通过节点之后,输入变为a * W1
3)
偏差(Bias)
——
除了权重之外,另一个被应用于输入的线性分量被称为偏差。它被加到权重与输入相乘的结果中。基本上添加偏差的目的是来改变权重与输入相乘所得结果的范围的。添加偏差后,结果将看起来像a* W1 +偏差。这是输入变换的最终线性分量。
4)
激活函数(Activation Function)——
一旦将线性分量应用于输入,将会需要应用一个非线性函数。这通过将激活函数应用于线性组合来完成。激活函数将输入信号转换为输出信号。应用激活函数后的输出看起来像f(a * W1 + b),其中f()就是激活函数。
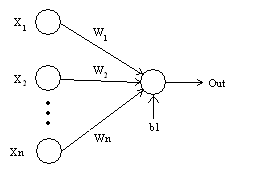
在下图中,我们将“n”个输入给定为X1到Xn而与其相应的权重为Wk1到Wkn。我们有一个给定值为bk的偏差。权重首先乘以与其对应的输入,然后与偏差加在一起。而这个值叫做u。
U =ΣW* X+ b
激活函数被应用于u,即 f(u),并且我们会从神经元接收最终输出,如yk = f(u)。
常用的激活函数
最常用的激活函数就是Sigmoid,ReLU和softmax
a)
Sigmoid——
最常用的激活函数之一是Sigmoid,它被定义为:
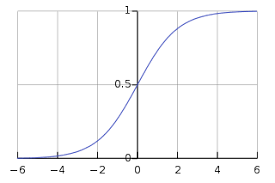
来源:维基百科
Sigmoid变换产生一个值为0到1之间更平滑的范围。我们可能需要观察在输入值略有变化时输出值中发生的变化。光滑的曲线使我们能够做到这一点,因此优于阶跃函数。
b)
ReLU(整流线性单位)
——与Sigmoid函数不同的是,最近的网络更喜欢使用ReLu激活函数来处理隐藏层。该函数定义为:

当X>0时,函数的输出值为X;当X
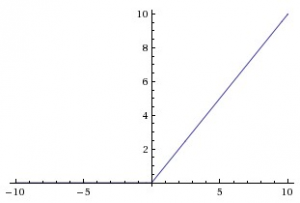
来源:cs231n
使用ReLU函数的最主要的好处是对于大于0的所有输入来说,它都有一个不变的导数值。常数导数值有助于网络训练进行得更快。
c)
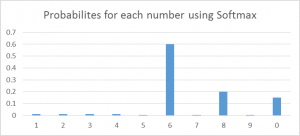
Softmax——
Softmax激活函数通常用于输出层,用于分类问题。它与sigmoid函数是很类似的,唯一的区别就是输出被归一化为总和为1。Sigmoid函数将发挥作用以防我们有一个二进制输出,但是如果我们有一个多类分类问题,softmax函数使为每个类分配值这种操作变得相当简单,而这可以将其解释为概率。
以这种方式来操作的话,我们很容易看到——假设你正在尝试识别一个可能看起来像8的6。该函数将为每个数字分配值如下。我们可以很容易地看出,最高概率被分配给6,而下一个最高概率分配给8,依此类推……
5)神经网络(Neural Network)——
神经网络构成了深度学习的支柱。神经网络的目标是找到一个未知函数的近似值。它由相互联系的神经元形成。这些神经元具有权重和在网络训练期间根据错误来进行更新的偏差。激活函数将非线性变换置于线性组合,而这个线性组合稍后会生成输出。激活的神经元的组合会给出输出值。
一个很好的神经网络定义——
“神经网络由许多相互关联的概念化的人造神经元组成,它们之间传递相互数据,并且具有根据网络”经验“调整的相关权重。神经元具有激活阈值,如果通过其相关权重的组合和传递给他们的数据满足这个阈值的话,其将被解雇;发射神经元的组合导致“学习”。
6)输入/输出/隐藏层(Input / Output / Hidden Layer)——
正如它们名字所代表的那样,输入层是接收输入那一层,本质上是网络的第一层。而输出层是生成输出的那一层,也可以说是网络的最终层。处理层是网络中的隐藏层。这些隐藏层是对传入数据执行特定任务并将其生成的输出传递到下一层的那些层。输入和输出层是我们可见的,而中间层则是隐藏的。
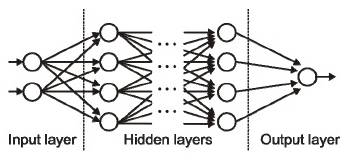
来源:cs231n
7)MLP(多层感知器)——
单个神经元将无法执行高度复杂的任务。因此,我们使用堆栈的神经元来生成我们所需要的输出。在最简单的网络中,我们将有一个输入层、一个隐藏层和一个输出层。每个层都有多个神经元,并且每个层中的所有神经元都连接到下一层的所有神经元。这些网络也可以被称为完全连接的网络。
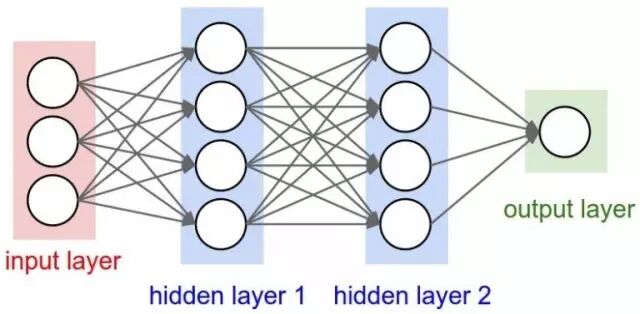
8)正向传播(Forward Propagation)——
正向传播是指输入通过隐藏层到输出层的运动。在正向传播中,信息沿着一个单一方向前进。输入层将输入提供给隐藏层,然后生成输出。这过程中是没有反向运动的。
9)成本函数(Cost Function)——
当我们建立一个网络时,网络试图将输出预测得尽可能靠近实际值。我们使用成本/损失函数来衡量网络的准确性。而成本或损失函数会在发生错误时尝试惩罚网络。
我们在运行网络时的目标是提高我们的预测精度并减少误差,从而最大限度地降低成本。最优化的输出是那些成本或损失函数值最小的输出。
如果我将成本函数定义为均方误差,则可以写为:
C= 1/m ∑(y–a)^2,
其中m是训练输入的数量,a是预测值,y是该特定示例的实际值。










