阿里云天池十一月之星
赵杰minerva_jiezhao 北京大学算法工程师
陈梓帆czifan
和 赵杰minerva_jiezhao
大牛来历
Hi,天池的各位小伙伴,很荣幸认识大家,我叫陈梓帆,来自北京大学,是一名在校研究生,现攻读前沿交叉学科研究院数据科学专业。
从本科开始一直在学习相关课程,从这个学科中感受到了学习带来的乐趣和挑战,原来看似无聊的数字代码,也可以在头脑风暴中变得灵活有趣,参加天池大赛,也是想锻炼自己,直面挑战,为以后的学习和工作打下坚实的基础,从理论到实践,也是一个需要不断尝试的过程,从校园进入社会也需要从一次次的实践中获取经验。希望我的分享可以给大家带来帮助!
个人公众号:Python编程和深度学习
GitHub:https://github.com/czifan
「获奖记录:」
2016.11,2015-2016-度国家奖学金
2017.11,2016-2017年度国家奖学金
2018.11,2017-2018年度国家奖学金
2017.03,“中国高校计算机大赛-团体程序设计竞赛”三等奖
2017.09,第八届中国计算机学会服务计算会议(NCSC2017)软件服务创新大赛三等奖
2019.06,湖南省省级优秀毕业生
2020.10,Spark“数字人体”AI挑战赛——脊柱疾病智能诊断大赛,亚军
2020.10,2020之江杯全球人工智能大赛——零样本目标分割,季军
Spark“数字人体”AI挑战赛——脊柱疾病智能诊断大赛:
https://tianchi.aliyun.com/competition/entrance/531796/introduction
之江杯全球人工智能大赛——零样本目标分割:
https://tianchi.aliyun.com/competition/entrance/531816/introduction
通过一次次的比赛,让我更加了解了,书本上的理论知识在遇到实际问题时,需要更加灵活的运用在各个场景里,学以致用才代表你真正掌握了这个知识点,才可以不断延伸,在一次次重复的过程中,获得更深的理解并加以应用,激发我更多的兴趣,去学习,去钻研。
采访纪实
「问:」
为什么参加天池比赛?原因是什么?
❝
参加比赛是因为我的在医学影像处理方向有过研究,做过定位相关的模型,这次比赛也是想利用天池提供的高难度数据测试并改善模型的质量。
❞
「问:」
参加天池比赛的收获有哪些?
❝
以实际需求驱动,在解决这一目标问题过程中,会进行相关工作的调研,
丰富自己的专业知识
,并且在激烈的榜单角逐中,
促使自己不断激发新的想法、优化算法模型
,在实现想法过程中也是
对自己工程实现能力的锻炼
。此外,参加天池大赛还能
认识到各路大佬
,与大佬的交流中能够学习到很多知识。
❞
「问:」
参加天池比赛在求职上会有帮助吗?具体是哪些?
❝
目前还未求职/申校,但在天池大赛上能够取得好的名次也是自身能力的一种体现,对于求职/申校应该会有一定积极的影响~
❞
「问:」
从比赛中,在团队协作和小组分工上收获了什么?
❝
在小组分工方面,陈梓帆负责写代码(工程相关),赵杰负责调研(数据分析,理论支持)。在一个较短的时间内,我们团队能够共同为一个目标进行奋斗,互相磨合之中也增进了团队成员间的协作能力和感情。
❞
「问:」
您认为参加天池比赛,可以帮助自己结识业界大牛吗?
❝
可以认识许许多多志同道合的大佬,一起交流分享能够促使自己快速进步。此外在决赛现场还能见到行业内的顶尖大牛!在复赛流程中结识了第二名的选手,互相交流了一些技术问题并收获了许多帮助,最后还决定一起参加另一场比赛。
❞
「问:」
参加天池大赛能帮助你熟悉项目流程吗?
❝
当然可以,例如这次spark大赛的复赛,采用云上docker进行训练和测试,更加贴近实际运用场景和需求。
赛题要解决的问题都是很实际也很有意义的问题论坛社区有足够优质的资料进行学习钉钉群交流及时,能够认识志同道合的大佬们主办方解决问题及时且能够耐心接受选手们问题的提问和反馈奖励机制也很棒
❞
大赛经验分享
「大赛名称:」
Spark“数字人体”AI挑战赛——脊柱疾病智能诊断大赛
「大赛地址:」
https://tianchi.aliyun.com/competition/entrance/531796/introduction
1 赛题分析
1.1 赛题回顾
本次比赛的任务是采用模型对核磁共振的脊柱图像进行智能检测。首先需要对5个椎体和6个椎间盘进行定位,这部分实际上就是11个关键点的检测任务;之后需要对每一个关键点对应的椎体/椎间盘进行疾病分类。
因此,整个比赛的任务可以分解为
关键点检测
和
关键点分类
两类大问题。
1.2 赛题分析
在开始建模之前,我们需要对数据有清晰的认识。通过对初赛训练集的分析,我们认为本次比赛存在如下三点挑战:
-
相比自然图像的大数据集,数据量比较少(毕竟医学影像获取和标注成本都比较高)
-
-
针对上述三个挑战,我们的解决方案如下:
-
-
-
数据增强、关键点标注抖动、基于先验统计的二分类阈值调整
2 模型方法
2.1 模型整体框架
我们首先将关键点定位分解为:粗定位和精回归两个子任务,并且在关键点检测的时候同时预测对应位置的关键点类别。模型整体框架如下图,主要由三部分组成:
-
backbone:采用resnet18[1]的前4个特征层(16倍下采样)提取图像的特征(注:这里去掉最后一个特征层不仅减少参数量且更容易训练,效果更好)
-
neck:通过几个特征融合块融合多尺度特征并且扩大模型的感受野
-
output:最后通过四个1X1卷积分别输出:关键点粗定位、关键点y轴上的细回归、关键点x轴上的细回归、关键点分类
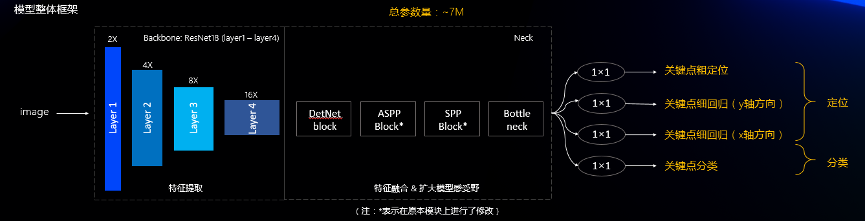
我们这种设计方案,相比于主流的heatmap-based关键点检测方法,不需要上采样层,不需要resnet最后一个特征提取层,使得学习任务更加简单,因此参数量和计算量都会更少(实验部分会有详细的对比分析)。
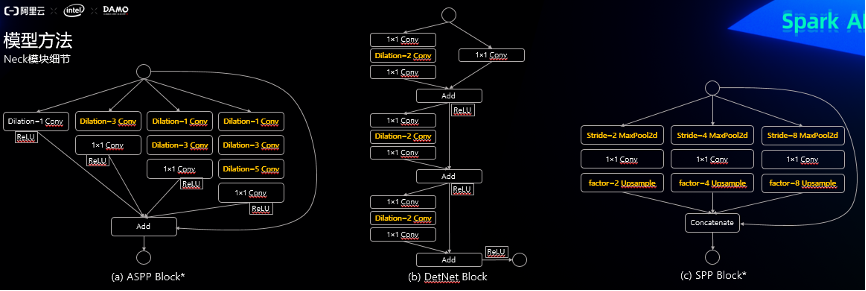
2.2 neck模块细节
neck部分的DetNet block[2]、ASPP Block[3]和SPP Block[4]都是用来融合多尺度特征且扩大模型感受野的,具体设计如下,DetNet block与原论文保持一致,ASPP/SPP Block都做了适应性的修改。
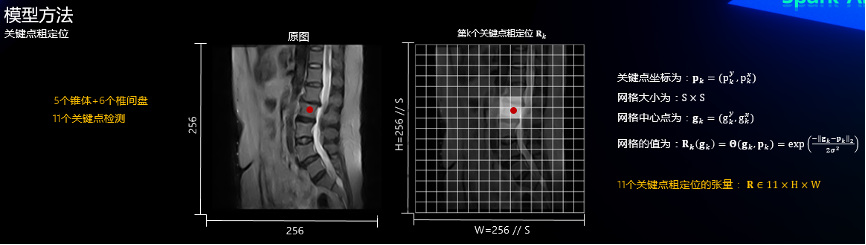
2.3 关键点粗定位
对于5个椎体+6个椎间盘共11个关键点进行检测,可以通过输出11个通道的张量分别代表11个关键点的预测。对于第k个关键点的粗定位,我们用一个网格图来表示,该图分辨率为原图下采样之后的分辨率,粗定位图上的每一个网格的值为其中心点与关键点的关系度量,如下图:
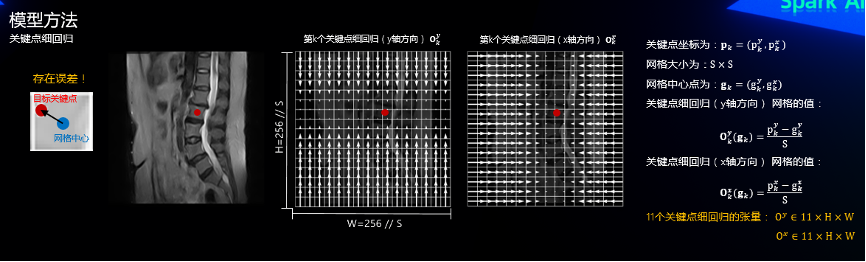
2.4 关键点细回归
有了关键点的粗定位图,我们可以找到离目标关键点最近的网格中心点,但每一个网格对应原图是一个的区域,显然直接取中心点离目标关键点有一定的误差,因此我们需要额外的两个与粗定位分辨率一样的定位细回归图(x轴和y轴两个方向),其每一个网格的值为其中心点到关键点在x/y轴上面的偏移,如下图。这里直接用偏移量的话由于范围太大了模型不太好学,因此我们把偏移量除以,使得关键点附近的网格的值都分布在1附近。
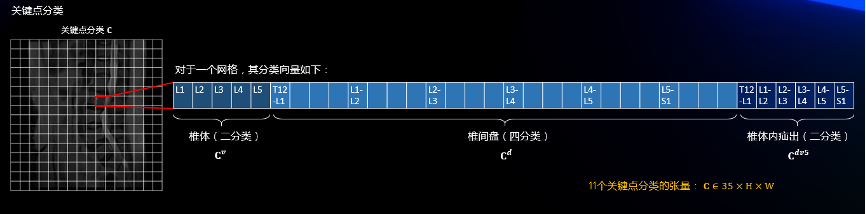
2.5 关键点分类
模型在进行粗定位和细回归的时候实际上已经学到了椎体/椎间盘的特征和位置信息,因此我们直接通过一个并行分支对相应网格位置进行分类预测。如下图,对于一个网格,如果其为椎体,那么需要一个5维度的向量表示对5个椎体的二分类;如果是椎间盘,那么需要一个4*6维度的向量表示对6个椎间盘的四分类,此外椎体内疝出(v5)可以与其他四类共存,因此我们额外采用6维度的向量进行表示。综上,一个网格应该对应35维度的向量。
2.6 损失函数
损失函数是一个多任务学习损失函数,由三部分构成:
-
对于关键点粗定位图的损失函数,直接采用MSELoss进行学习;
-
对于关键点细回归图的损失函数,首先过滤出粗定位图中激活值高的网格,而后只对细回归图上的这部分网格计算损失函数,如下图左边图中红框框所示。实际上这种做法能够使得模型更加关注目标区域,减少对无关区域的关注;
-
对于关键点分类图的损失函数,同样过滤出需要关注的网格,而后对于每一个网格,若该关键点是椎体,则计算前5维度向量的损失;若是椎间盘,则计算后4*6+6维度的损失。为了适应类别不平衡的问题,对于BCELoss和CrossEntropyLoss都采用了类别样本数倒数作为相应类别的权重。
总的损失函数是上面各部分的加权求和,权重我们根据经验值直接设置的。

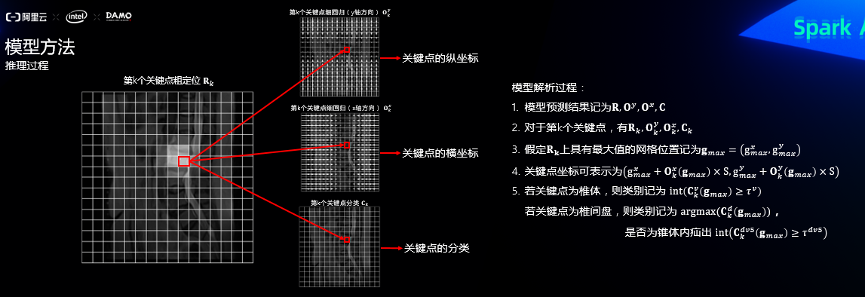
2.7 推理过程
推理的时候取关键点粗定位图值最高的网格(关系最密切的网格),再在细回归图和分类图取相同位置的网格,即可以解析出关键点坐标和关键点类别,如下图:
2.8 其他一些小技巧
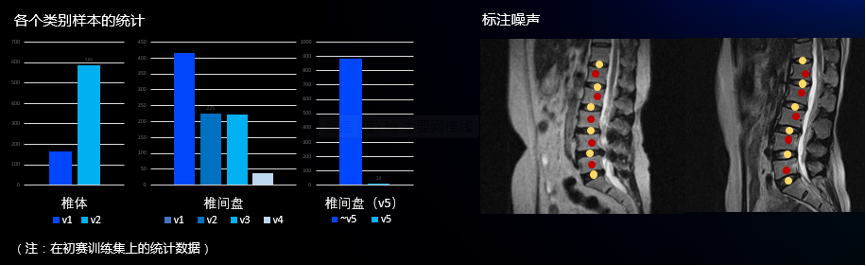
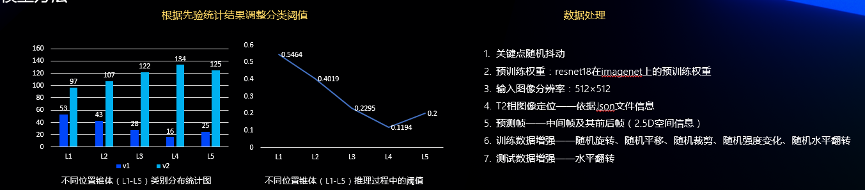
我们统计了初赛训练集上不同位置椎体的类别分布,如下图,我们发现不同位置其v1/v2的比例有所不同,靠近胸椎的椎体病变概率相对低一些,而在靠近尾椎的椎体更容易产生病变,这个发现和我们的直觉是一致的。因此我们模型会根据这个先验统计结果进行二分类的阈值调整,调整后的阈值如下图。同样地,对于椎体内疝出,我们也做了同样的策略。
此外,为了使得模型鲁棒性更强,减少标注噪声的影像,我们还采用了多种数据增强,如下图。其中对于关键点随机抖动,具体做法是对于标签关键点,我们会加上一个随机的小偏移量,以模拟医生标注可能抖动的问题。
2.9 模型融合
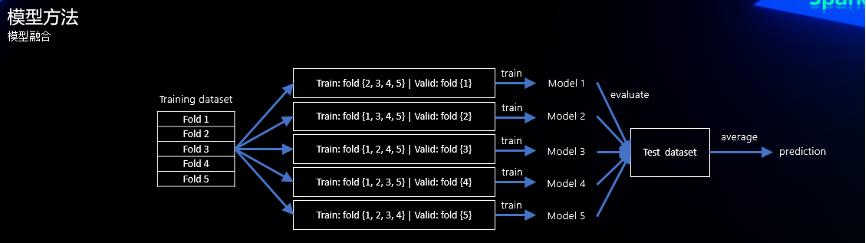
医学影像处理在数据不多的情况下,一般采用多折交叉验证使得模型验证更加稳定,因此我们采用了5折交叉验证训练了5个模型,而后将他们在测试集上的结果进行平均,得到最终成绩。
3 实验结果
3.1 复赛成绩及模型性能测试

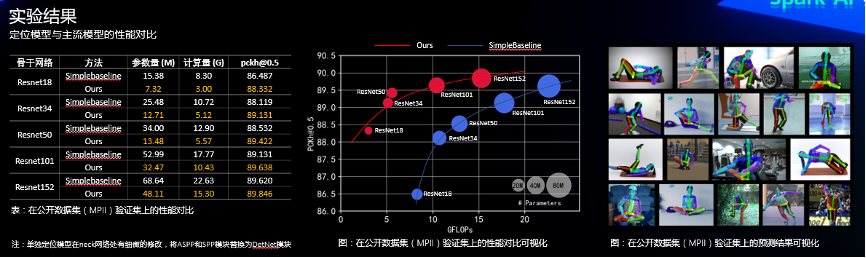
3.2 定位模型与主流模型的性能对比
由于复赛数据不可见,且每天一次提交,机会宝贵,因此我们额外在关键点检测的公开数据集[6]上进行我们模型与主流模型[5]的对比实验,如下图。证明了我们模型的有效性和高效性,且更容易收敛(小模型就可以达到不错的效果)。