像 Docker 这样的容器格式和 Kubernetes 之类的容器管理平台正越来越受到人们的欢迎,这不仅仅是因为人们喜欢微服务,出于很多原因,公司的首席信息官和工程高管都乐于接受微服务,他们也会把容器视为他们的混合云战略的关键组成部分。这是因为容器空间(Docker、Kubernetes 和 DC / OS 等)的核心技术、生态系统是全面开源的,这为用户提供了抽象的虚拟化工具。近日,卡尔斯鲁厄理工学院(KIT)的计算机科学学生 Frederic J. Tausch 在 GitHub 上发布了一篇详细教程,「可以帮助研究人员和爱好者们用他们的 Kubernetes GPU 集群轻松地对深度学习的训练过程进行自动操作和加速。」机器之心对本教程进行了编译。
教程地址及相关文件:https://github.com/Langhalsdino/Kubernetes-GPU-Guide
在这个教程中,我将要介绍如何轻松地在多个 Ubuntu 16.04 裸机服务器上进行 Kubernetes GPU 集群配置,并且提供一些有用的脚本和.yaml 文件,它们可以给你提供全部配置。
顺便说一句:如果你是用 Kubernetes GPU 集群做一些其他的东西,这篇教程也同样适用于你。
我为什么要写这篇教程?
我现在是新创办的 understand.ai 公司的一名实习生,我在平时的工作中注意到:先在本地设置机器学习算法,然后把它放进云端用不同参数和数据集去进行训练,这一过程是很麻烦的。
第二点,把它放进云端进行大量的训练往往比预想的还要费时间,这是令人沮丧的,并且通常包含很多缺陷。
基于这个原因我下定决心要解决这个问题,并且让第二部分变得容易,简单,快捷。
这是一篇实践教程,是关于怎样设置我们自己的 Kubernetes GPU 集群来提升工作速度的。
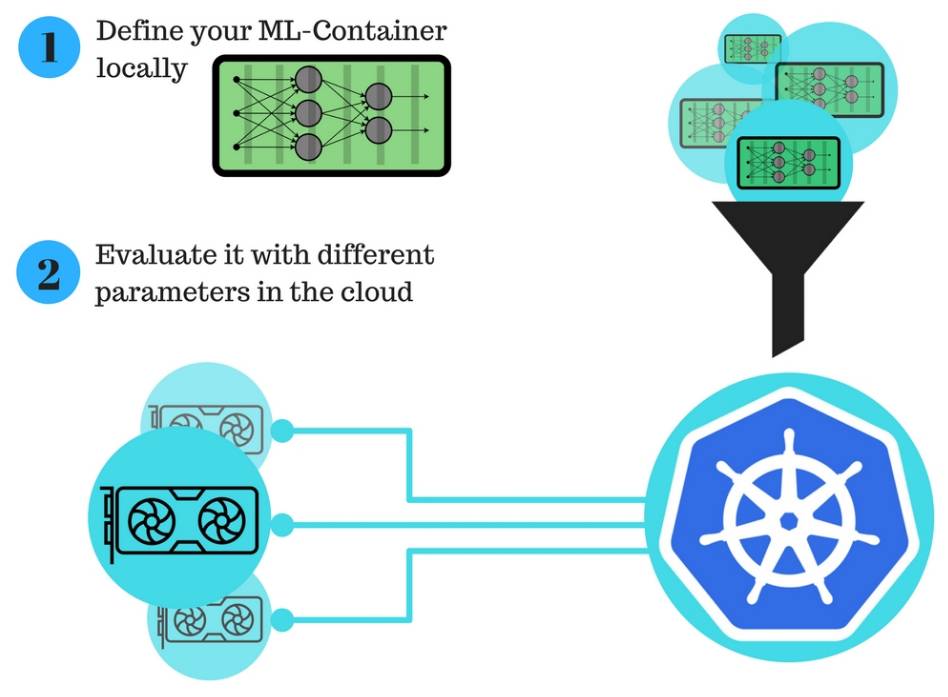
深度学习科研人员的新工作流程:
用 Kubernetes GPU 集群进行自动化的深度学习训练显著地改善了在云端进行模型训练的流程。
此说明呈现了新的工作流程,只包含两个简单步骤:
免责声明:
请注意,以下部分仅代表个人观点。Kubernetes 是一个正在快速升级的环境,这意味着本篇教程可能会在将来的某个时间失效,这取决于工作者们的空余时间和个人贡献。由于这个原因我们也很希望大家可以群策群力,做出新的贡献。
目录
-
Kubernetes 的快速回顾
-
集群结构概览
-
初始化节点
-
我的配置
-
配置指令
-
使用快速配置的脚本
-
步骤的详细说明
-
怎样创建你的 GPU 容器
-
.yml 的重要部分
-
GPU 实例的使用
-
一些有用的指令
-
致谢
-
作者
-
版权
Kubernetes 的快速回顾
如果你需要更新你的 Kubernetes 的相关知识,这些文章可能对你是有用处的:
-
Introduction to Kubernetes by DigitalOcean (https://www.digitalocean.com/community/tutorials/an-introduction-to-kubernetes)
-
Kubernetes concepts (https://kubernetes.io/docs/concepts/)
-
Kubernetes by example (http://kubernetesbyexample.com/)
-
Kubernetes basics - interactive tutorial (https://kubernetes.io/docs/tutorials/kubernetes-basics/)
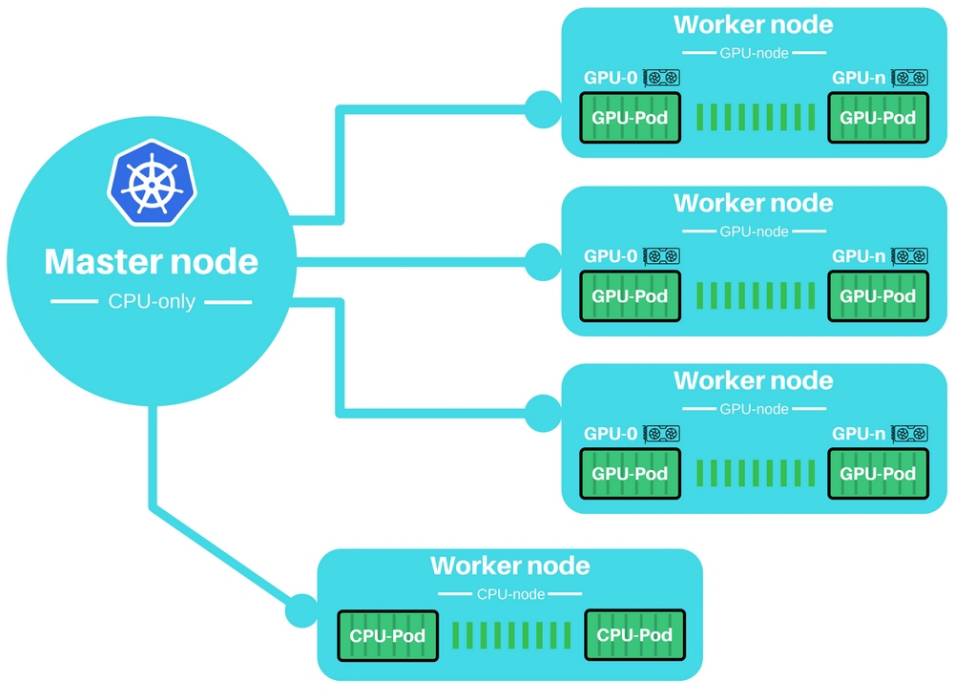
集群结构的概览
主要思想:即用一个小 CPU 作为主控节点(master node)来控制一个集群的 GPU-工作节点(GPU-worker nodes)。
初始化节点
在我们使用集群之前,先对集群进行初始化是很重要的。因此每个节点必须被手动初始化,然后才能加入到集群当中。
我的配置
此配置对上述案例十分适用——对其他实例或操作系统来说,往往需要一些额外的调试。
Master 主控节点
-
SSH 访问
-
ufw 停用
-
启用端口(udp 和 tcp)
Worker 工作站
-
SSH 访问
-
ufw 停用
-
启用端口(udp 和 tcp)
关于安全性:在使用过程中你应该关闭一些防火墙——为了更加简单,应该禁用 ufw。为实际的生产工作负载设置 Kubernetes 当然应该包括启用一些防火墙,像 ufw, iptables 或你的云端服务器的防火墙。也要注意在云端设置一个工作集群可能更加复杂。你的云端供应商通常会提供一个他们自己的防火墙,这是和主机防火墙相分离的。你可能必须要停用 ufw,并且也要启用云端供应商的防火墙,使本教程的步骤可以正常进行下去。
设置向导
这些说明涵盖了我们在 Ubuntu 16.04 系统上的操作经验,可能有些地方并不适合于转移到其他操作平台。
如下所示,我们构建了两个脚本,它们能完全启动主控节点(master node)和工作节点(worker node)。如果你希望快速运行,那么就只需要使用以下两个脚本就行。否则的话,我建议跟着设置向导一步步阅读。
快速通道—设置脚本
下面我们将利用脚本进行快速设定。首先需要复制对应的脚本到主节点和工作节点的机器上:
主控节点
执行上面的主控节点初始化脚本,并记下代号。代号通常看起来像:--token f38242.e7f3XXXXXXXXe231e
chmod +x init-master.sh
sudo ./init-master.sh
工作节点
执行上面的工作节点初始化脚本,并要求输入正确的主控节点代号和 IP,端口通常使用 6443。
chmod +x init-worker.sh
sudo ./init-worker.sh
:
详细的安装说明
主控节点
1. 添加 Kubernetes 资源库到软件包管理器中:
sudo bash -c 'apt-get update && apt-get install -y apt-transport-https
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add -
cat <
/etc/apt/sources.list.d/kubernetes.list
deb http://apt.kubernetes.io/ kubernetes-xenial main
EOF
apt-get update'
2. 安装 docker-engine、kubeadm、kubectl 和 kubernetes-cni 库
sudo apt-get install -y docker-engine
sudo apt-get install -y kubelet kubeadm kubectl kubernetes-cni
sudo groupadd docker
sudo usermod -aG docker $USER
echo 'You might need to reboot / relogin to make docker work correctly'
3. 因为我们希望使用 GPU 构建一个计算机集群,所以我们需要 GPU 能在主控节点中进行加速。当然,也许该说明会因为新版本的 Kubernetes 出现而需要更改。
3.1 将 GPU 支持添加到 Kubeadm 配置中,这个时候集群是没有初始化的。这一步需要在集群每一个节点的机器中完成,即使有一些没有 GPU。
sudo vim /etc/systemd/system/kubelet.service.d/<
>-kubeadm.conf
因此,添加 flag --feature-gates="Accelerators=true" 到 ExecStart 中,命令行大概如下所示:
ExecStart=/usr/bin/kubelet $KUBELET_KUBECONFIG_ARGS [...] --feature-gates="Accelerators=true"
3.2 重启 kubelet
sudo systemctl daemon-reload
sudo systemctl restart kubelet
4. 现在我们需要初始化主控节点。
这一步我们需要主控节点的 IP,同时该步骤也会提供添加其他工作结点的认证信息,所以还是需要记住代号。代号通常看起来像:--token f38242.e7f3XXXXXXXXe231e 130.211.XXX.XXX:6443
sudo kubeadm init --apiserver-advertise-address=
5. 自从 Kubernetes 1.6 从 ABAC roll-management 改为 RBAC,我们需要通知用户的认证信息。每一次在登录机器时,我们都需要执行这一步骤。
sudo cp /etc/kubernetes/admin.conf $HOME/
sudo chown $(id -u):$(id -g) $HOME/admin.conf
export KUBECONFIG=$HOME/admin.conf
6. 安装网络扩展以令 pod 能相互交流。Kubernetes 1.6 对安装这种网络扩展有一些环境要求,如:
下面该链接汇聚了一些合适的网络扩展:https://docs.google.com/spreadsheets/d/1Nqa6y4J3kEE2wW_wNFSwuAuADAl74vdN6jYGmwXRBv8/edit#gid=0
kubectl apply -f https://git.io/weave-kube-1.6
5.2 现在检查 pod,以确定所有 pod 在线验证了能正常运行。
kubectl get pods --all-namespaces
注意:如果你需要删除主控节点,那么你就需要重置它。
sudo kubeadm reset
工作节点
前面的部分和主控节点的步骤是差不多的,所以可能设置地快一些。
1. 添加 Kubernetes 资源库到软件包管理器中:
sudo bash -c 'apt-get update && apt-get install -y apt-transport-https
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | apt-key add -
cat <
/etc/apt/sources.list.d/kubernetes.list
deb http://apt.kubernetes.io/ kubernetes-xenial main
EOF
apt-get update'
2. 安装 docker-engine、kubeadm、kubectl 和 kubernetes-cni 库
sudo apt-get install -y docker-engine







