陈绪
未知的瞬间
2017云栖大会机器学习平台PAI专场,阿里巴巴高级技术专家陈绪带来千亿特征流式学习在大规模推荐排序场景的应用的演讲。主要从电商个性化推荐开始谈起,进而描述了技术挑战和PAI解决方案,重点分享了鲲鹏框架和算法调优,最好作了简要总结。
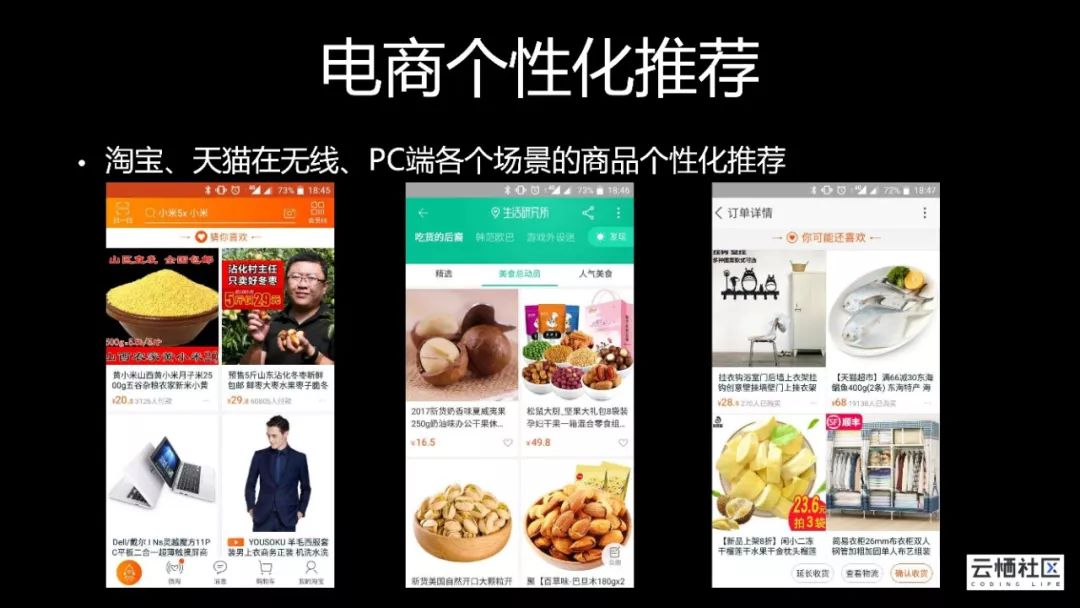
淘宝、天猫在无线、PC端各个场景的商品个性化推荐大家都很熟悉,这些展示都是由个性化推荐排序算法决定的。根据每个用户不同的兴趣,做到千人千面的个性化展示,比如手淘首页的猜你喜欢,它是阿里电商最大的推荐场景,还有人群导购、看了又看、买了又买等页面,背后都是由机器学习算法来规划商品个性化排序。
点击率预估算法
商品的个性化排序一般都转化成点击率预估问题,给定一个当前用户,并且给定用户相关上下文的一些特征,来预测对于一个特定的商品的点击概率有多大,我们希望用户点击率越高的商品排在前面,点击或者不点击是二分类问题,通过采集用户商品各种维度特征进行建模,最终训练排序模型。
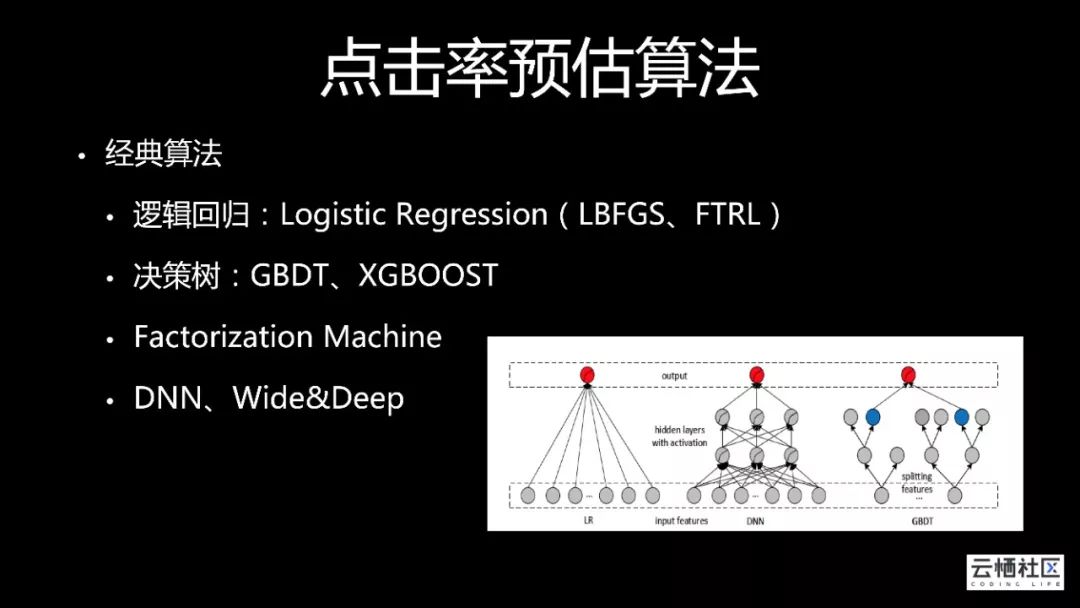
点击率预估算法是经典的研究课题,很早以前就有逻辑回归:Logistic Regression(LBFGS、FTRL)线性算法,还有决策树GBDT、XGBOOST提供非线性分类能力,近几年逐渐往更深层次发展研究,比如Factorization Machine、DNN、Wide&Deep。



挑战和解决方案
具体到阿里电商场景,我们也有特定的问题和挑战。
阿里电商推荐的业务特点:
最大场景达到百亿级别的PV/天,训练样本很大,亿级别用户维度和亿级别商品维度使我们做特征工程交叉组合时非常容易形成爆炸式天文数字的特征维度,还有快速实时变化的用户兴趣和热门商品。
传统的点击率预估算法和平台的挑战是特征规模有限(10亿~100亿)难以刻画全网用户行为和商品特征,热门商品每天也在快速变化,离线训练难以捕捉用户短期内兴趣模式。
基于以上问题,我们做了大量算法框架和平台优化,在PAI平台上开发千亿特征流式学习这样的机器学习框架。
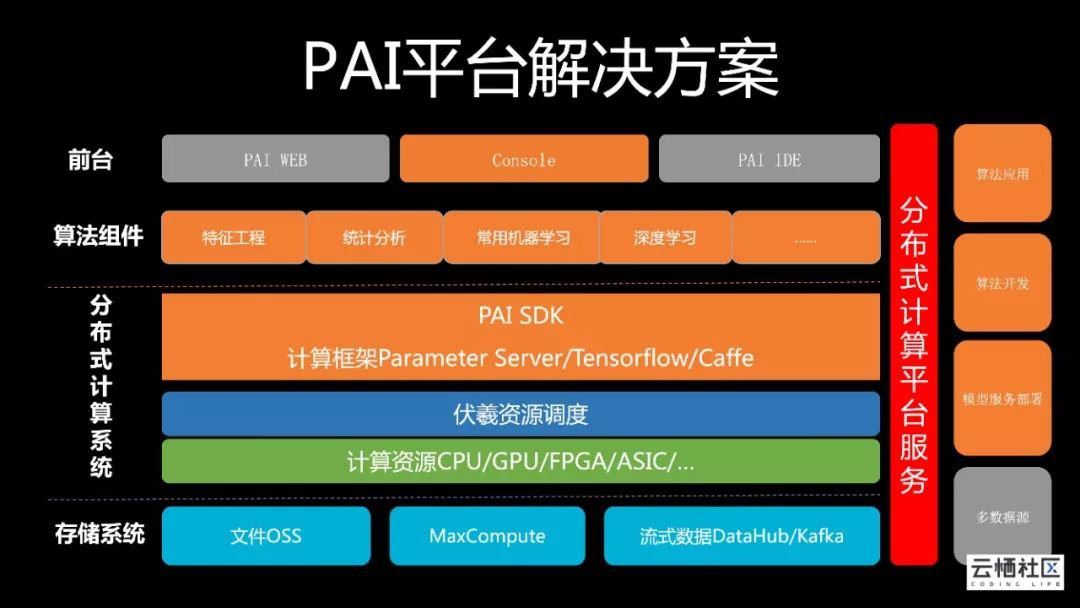
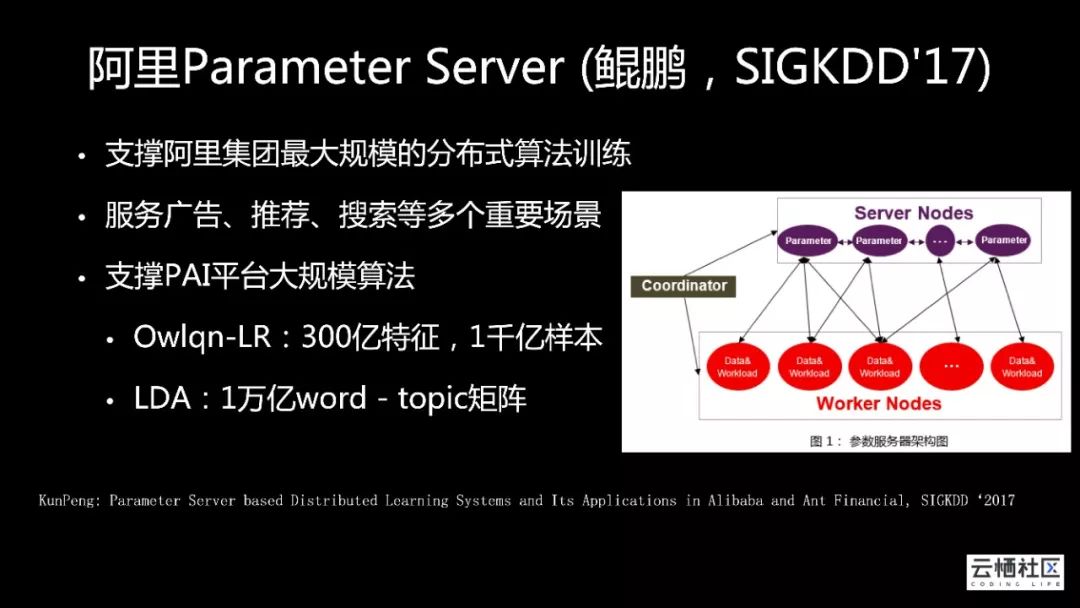




PS支撑阿里集团最大规模的分布式算法训练,我们从2014年开始研发,到目前为止服务广告、推荐、搜索等多个重要场景,支撑PAI平台大规模算法,Owlqn-LR:300亿特征、1千亿样本,LDA:1万亿word - topic矩阵等,我们也逐步向公有云用户开放算法训练服务。
PS框架面临的挑战有很多,包括参数规模和样本规模巨大,为了能够更精确的学习商品特征,我们需要将规模提升到几千亿甚至上万亿级别;模型更新间隔短(分钟级别)才能尽快捕捉线上用户变化信息特征;算法效果稳定性要求高,在鲲鹏基础上做了大量针对性功能和优化来适应新型算法场景。
PS框架具备以下特点:
200~400台Server,平均35GB内存。
使用定制的ArrayHashMap存储特征权重向量,去除特征ID化环节,插入、迭 代性能较std::unordered_map提升300%。我们以高频率向模型中插入新特征到模型中,也会以非常高的频率剔除过期特征,在工程实践上做了大量改进,能够适应高频率特征集合的高频率变化。
当并行server数量非常高时,我们做了大量通信性能优化,使得我们对大量特征样本量实时训练更新,Sparse、Dense参数合并通信,通信链路无锁。
我们将以前离线batch方式转换成实时在线训练,由全量样本训练向流式增量训练(Online Learning)演化,由训练Job转化为不间断训练Service,整个过程中内存数据不落盘,实时感知新数据分区触发训练,将训练样本读到训练进程中,将更新后的模型实时推到在线预测服务中去。
同时,框架还支持灵活控制实时训练触发间隔,如果某些场景需要高频模型,最高可以精确到分钟级触发。
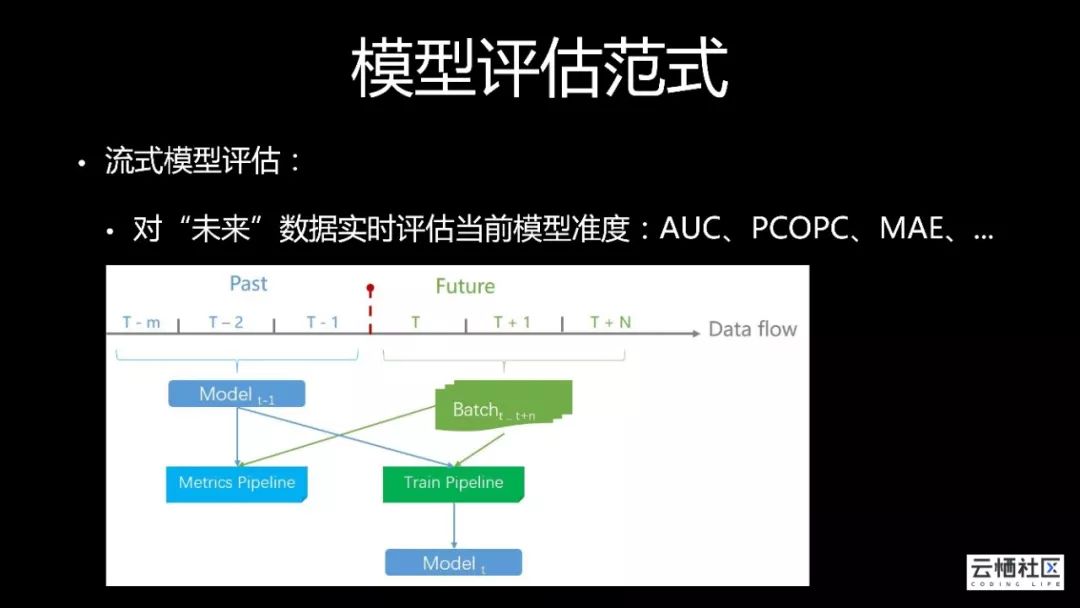
我们在多数据源支持统一checkpoint、Exactly Once Failover,所有数据保证严格训练一遍;支持单节点异步failover,在训练过程中,如果有个别进程crash,整个进程不需要打断,可以继续不受影响继续更新模型;我们也可以灵活断点调参,结合流式预估、流式评价算子,加速调参过程。





延展阅读:
李晗
未知的瞬间
李晗,阿里妈妈精准定向技术部&云营销业务中心,高级技术专家,现任展示广告平台策略机制团队负责人,牵头负责整个商品展示广告业务线,主导整个定向单品广告无线商业化进程,实现手淘核心消费者链路的商业接入和业务优化,实现消耗千万量级规模的增长。
以手淘首页猜你喜欢场景商业化为契机,构建核心机制和技术体系,协同推荐团队进行流量接入模式的探索和创新。
从无到有构建整个广告平台机制策略算法体系。
创新提出三方共赢的平台 OCPC 智能调价算法,率先推动强化学习技术赋能策略算法,围绕平台调控能力提升构建全链路参数学习。
同时兼任展示广告matching算法团队负责人, 主导整体阿里妈妈展示广告matching技术的三代技术演进和升级,打造整体matching算法的体系化建设。
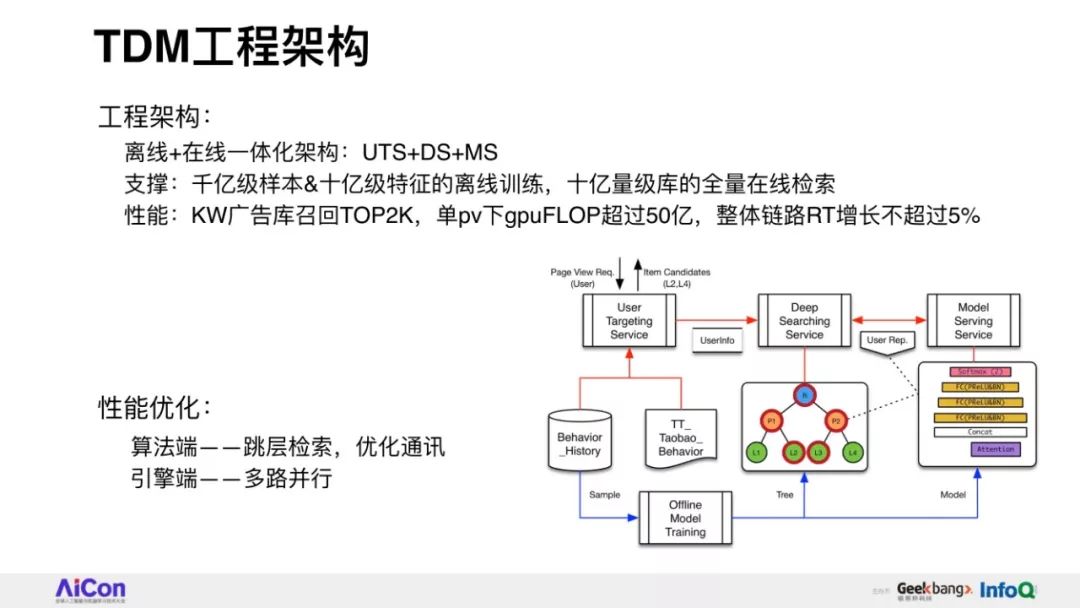
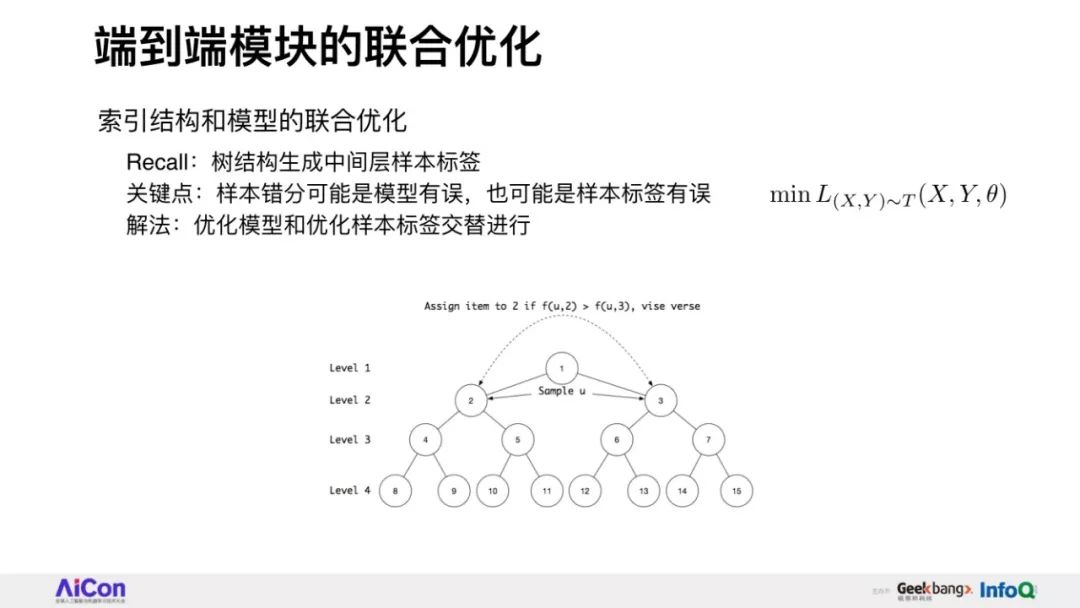
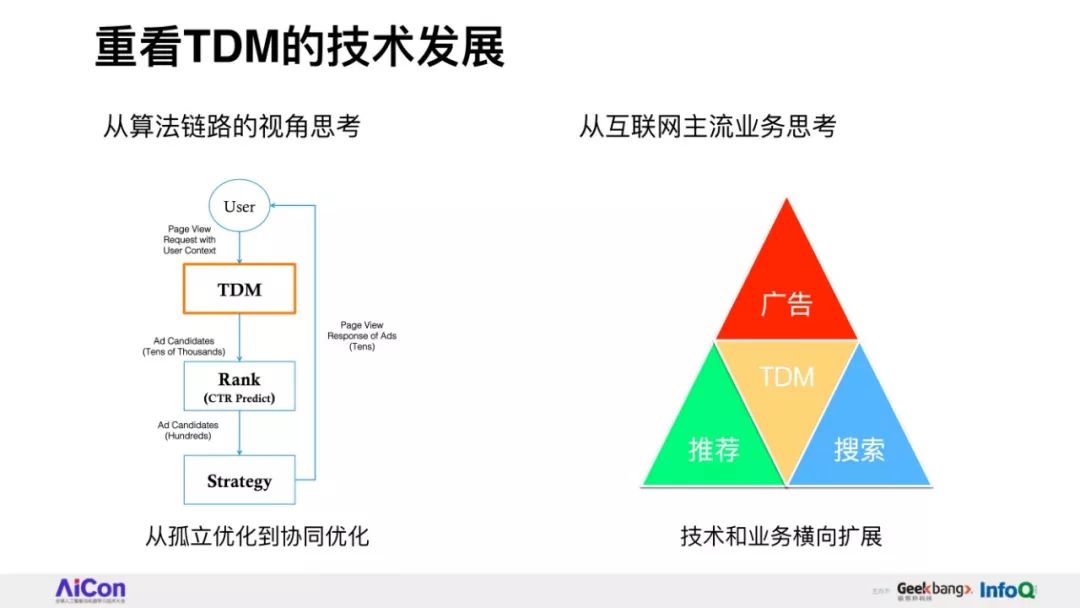
破局性提出并落地基于树结构检索的深度匹配算法框架,定义索引结构+检索模式+模型能力联合端到端学习新范式。
兼任云营销数据算法团队负责人,作为数据和算法技术负责人协同运营、产品、商务团队推动阿里全域营销战略落地。
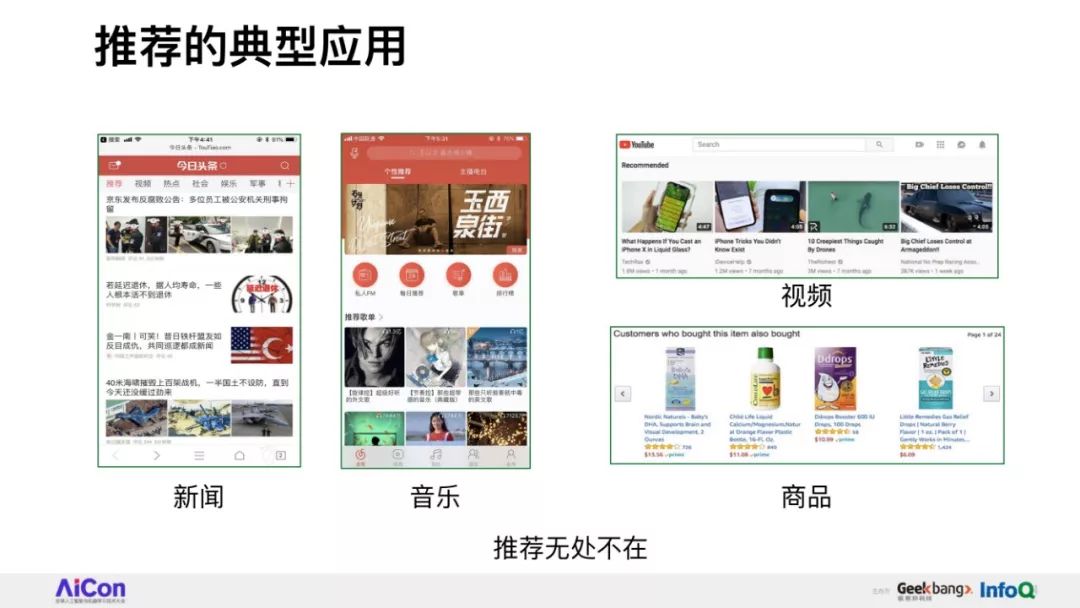
推荐业务是互联网内容提供商进行流量分配的核心业务,也是大数据和机器学习技术的典型应用场景。
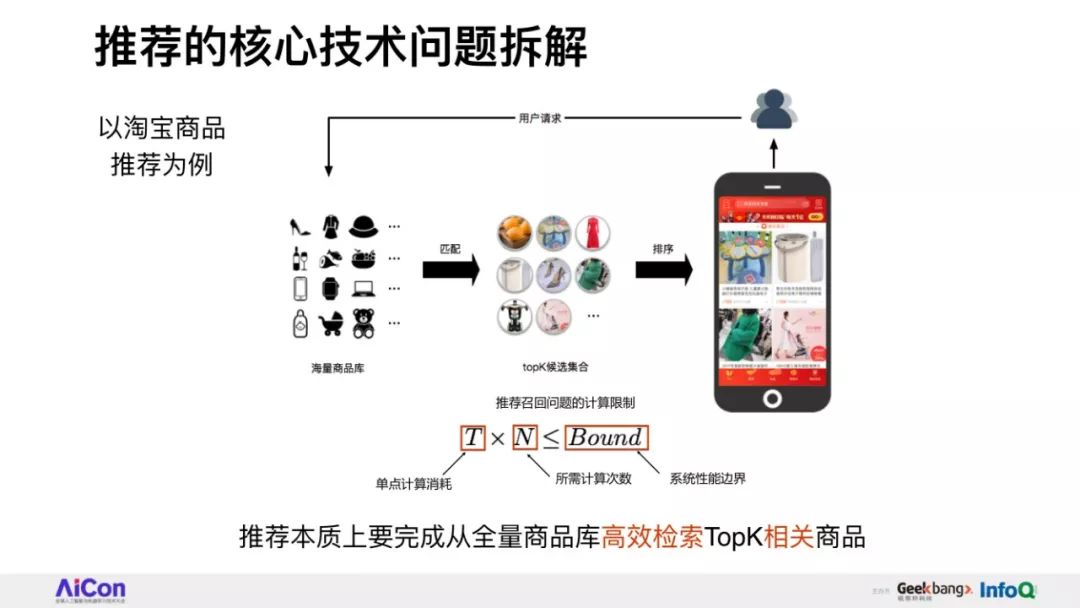
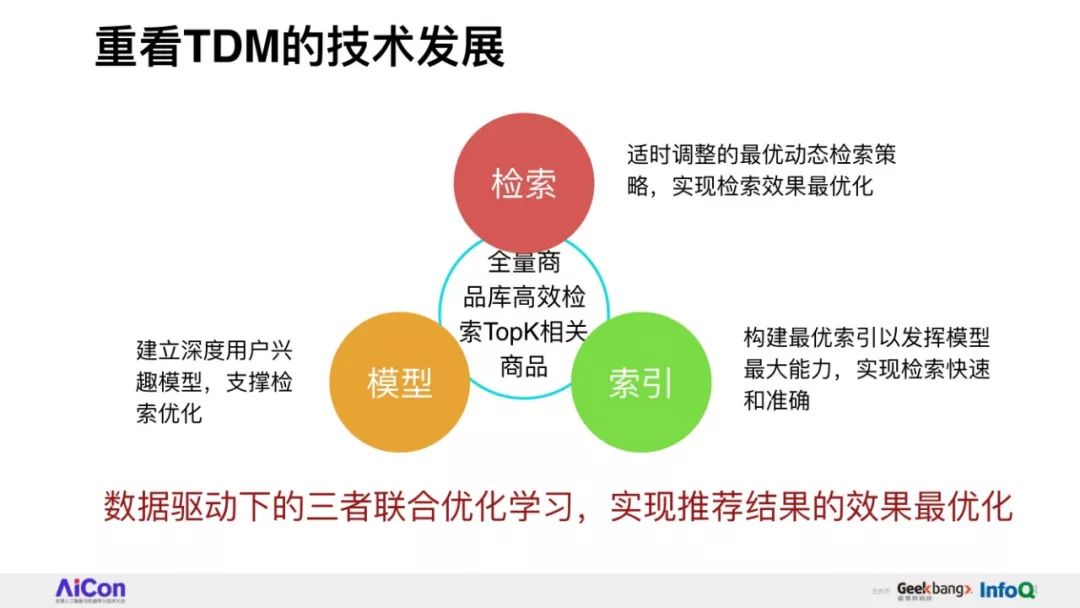
以电商环境为例,推荐技术的核心任务是要完成从全部海量商品库高效检索TopK相关商品给用户。
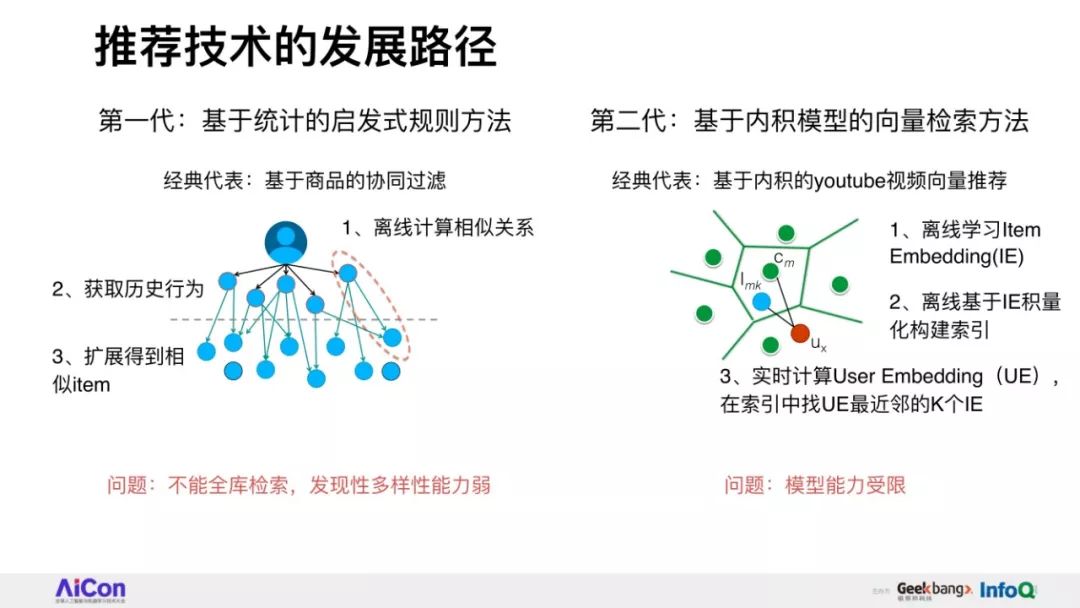
为实现这一目标,推荐技术经历了以Item-CF为代表的基于统计启发式规则,到以内积模型为代表的向量检索技术的演进和发展。
但当前基于内积检索的推荐技术虽然突破了全量候选集召回的天花板,一定程度引入深度模型优化推荐效率,但内积结构模型表达能力存在局限,无法利用更先进模型进一步提升推荐效果。
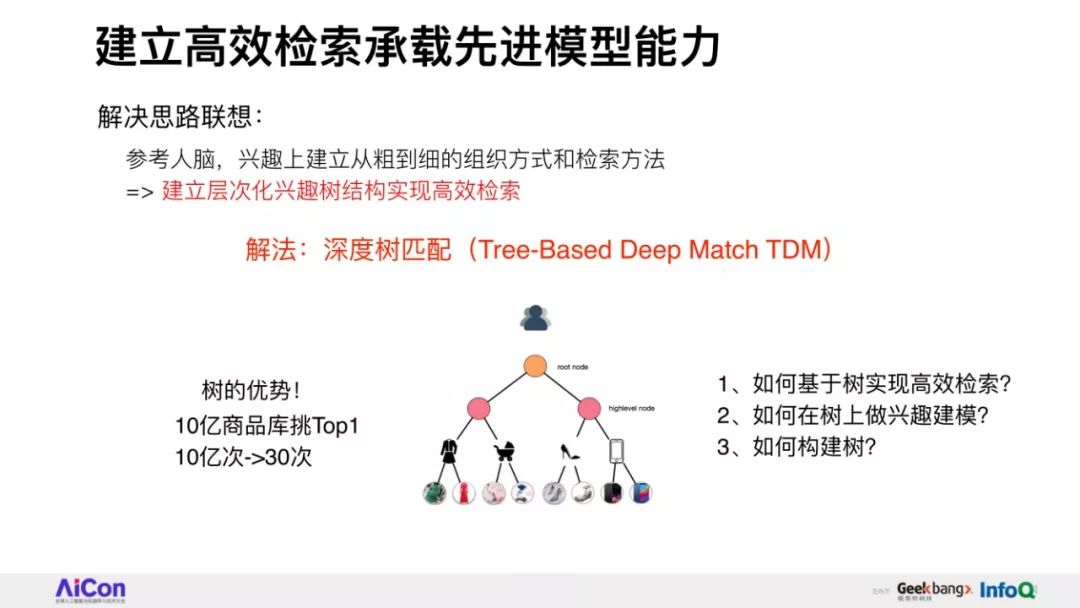
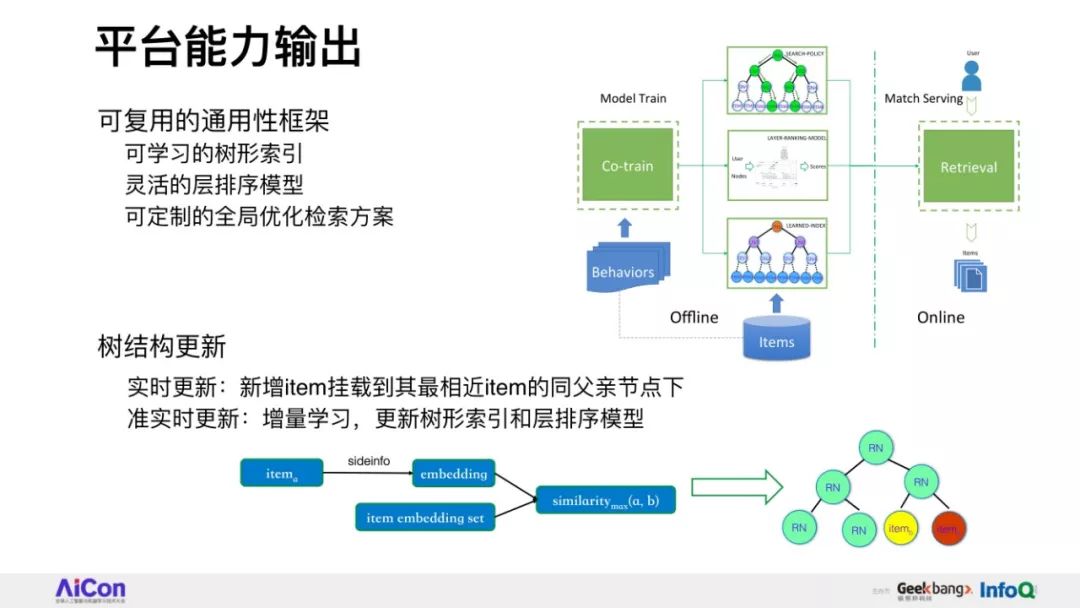
如何在全库检索的基础上突破模型能力天花板,是下一代工业级推荐技术的可行性发展方向。
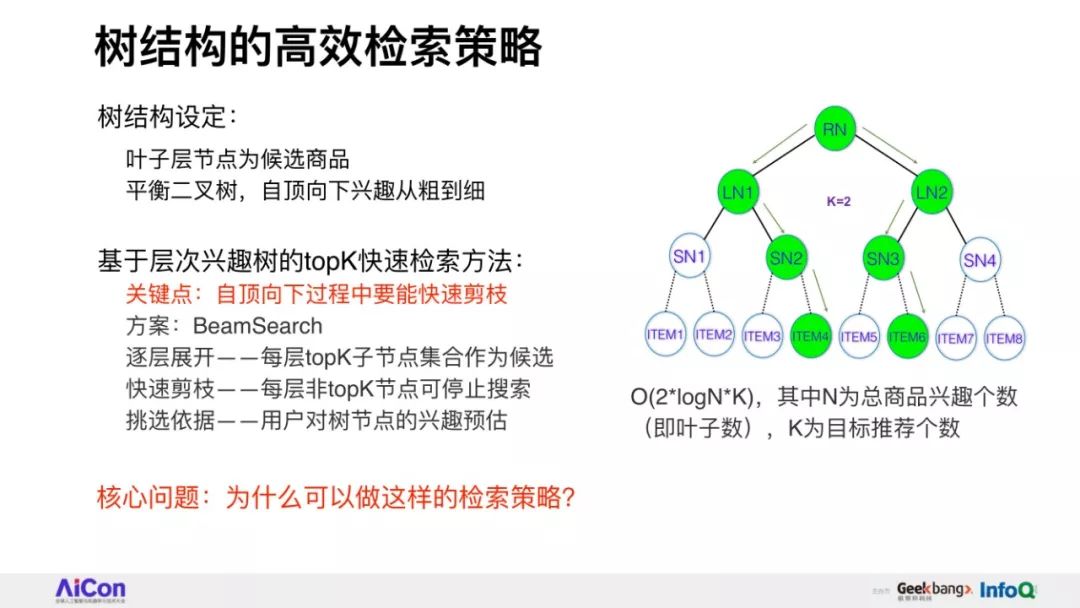
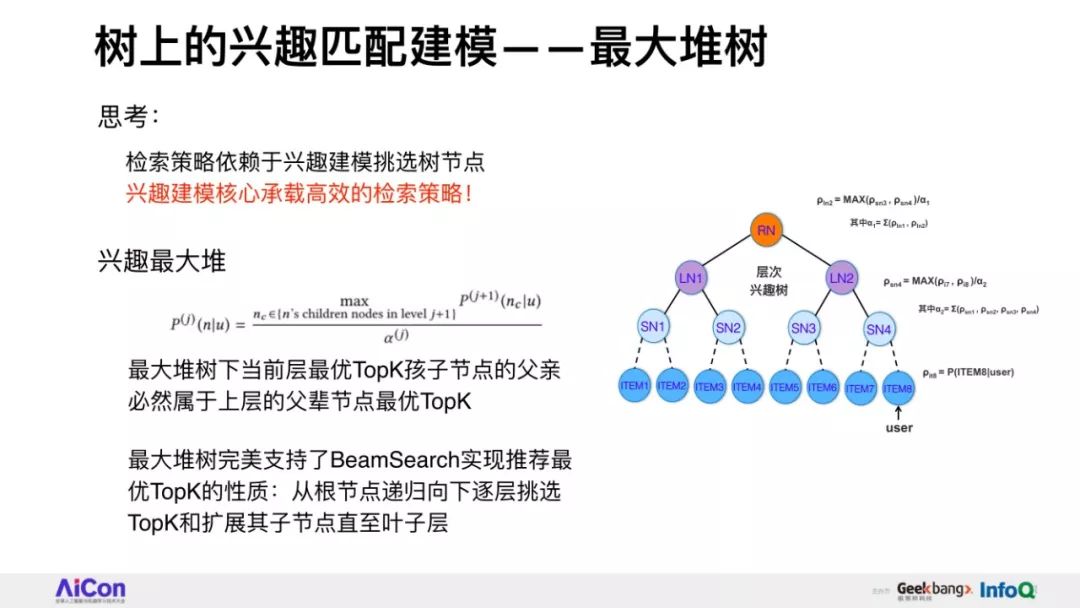
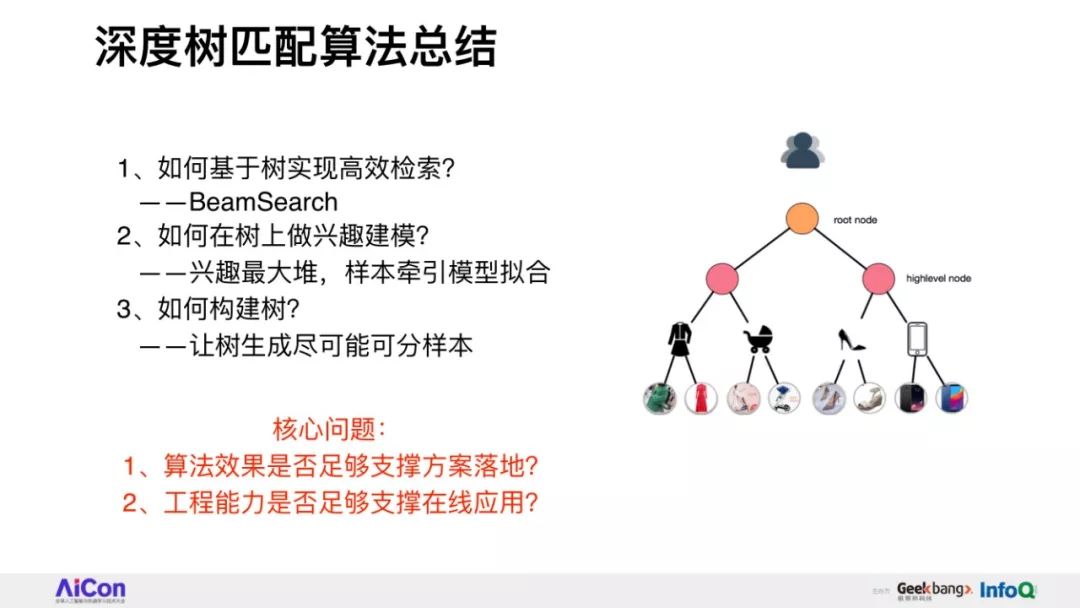
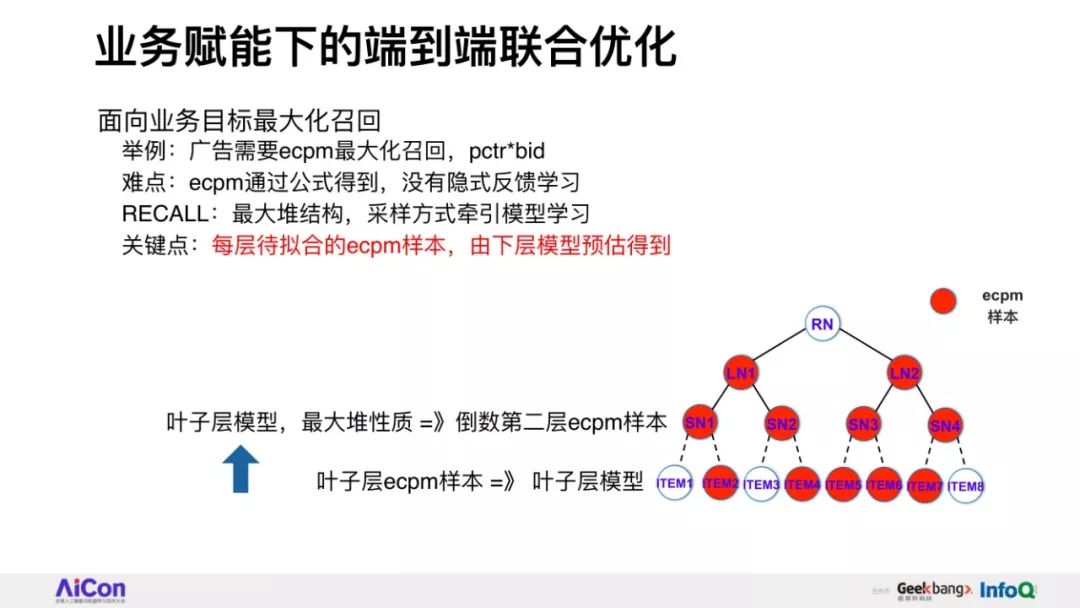
分享将会介绍阿里妈妈精准算法团队围绕全库检索+先进模型这一目标,自主提出的深度树匹配技术Tree-based Deep Match(TDM)这一全新的推荐算法框架。
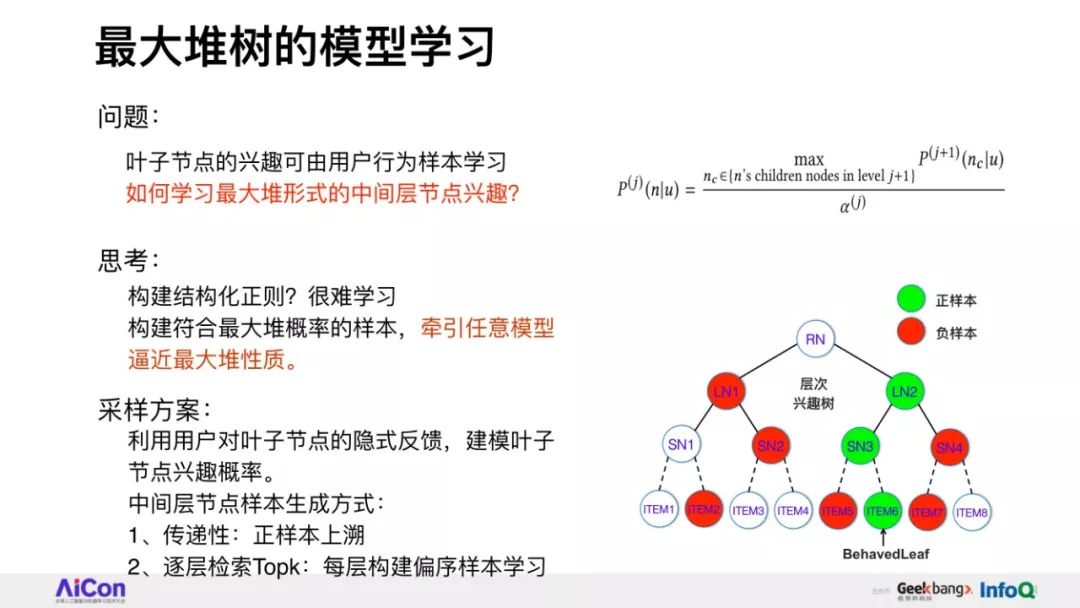
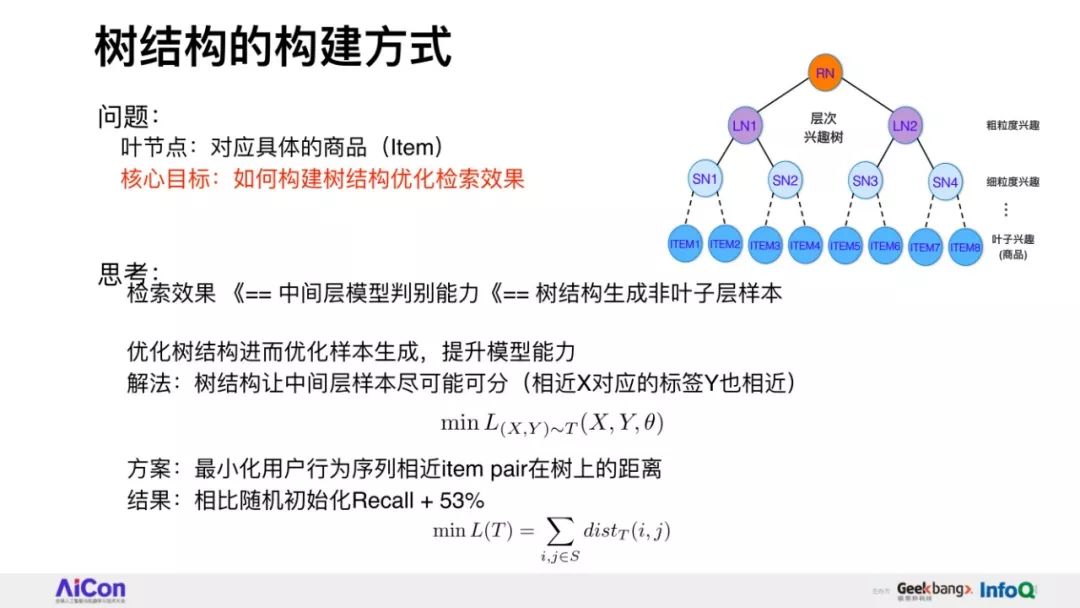
我们将会详细讲述,在具体实现层面如何根据树结构提出兴趣概率最大堆模型,并由此推演出一整套采样、检索、建模的方法。
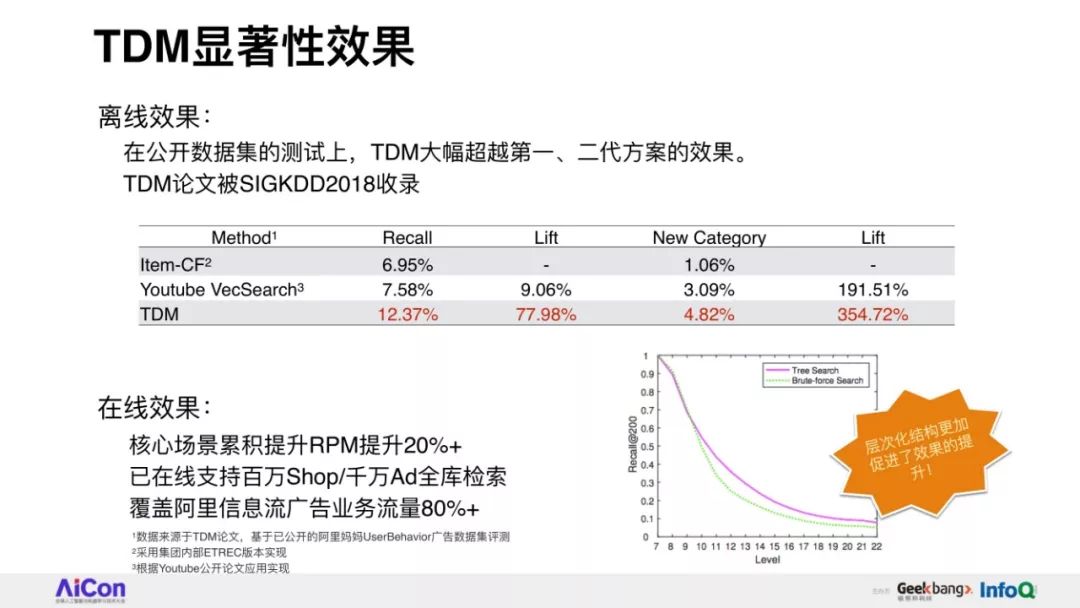
此外我们会详细介绍深度树匹配技术一方面在广告业务上的应用成果和学术创新性探索,该工作也被收录到KDD2018。
与此同时,我们还将从下一代工业级推荐技术持续发展的视角,讲述围绕深度树匹配技术进一步发展的探索和思考。
概要:
1. 什么是推荐问题和推荐技术
2. 深度树匹配——下一代推荐技术的探索
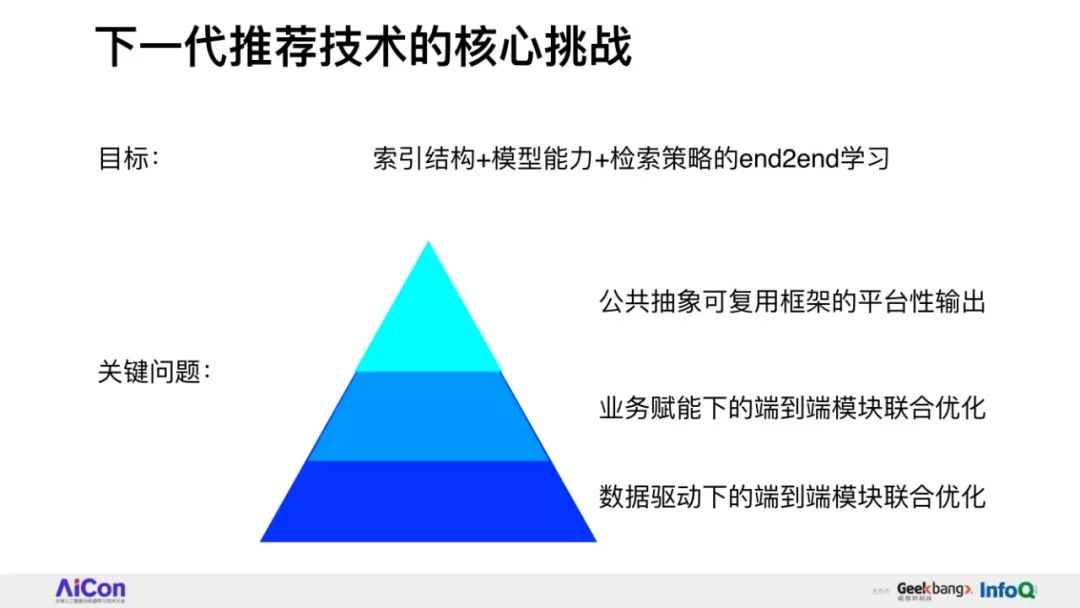
3. 成为下一代推荐技术的核心挑战
4. 深度树匹配——下一代推荐技术探索的再思考
收益:
1. 了解推荐技术的演进历程
2. 了解推荐技术最前沿的实践探索
3. 了解推荐技术持续发展的方向和原动力











延展阅读:
未知的瞬间
孙付伟,毕业于中国科学院软件研究所,现任知乎推荐技术团队负责人,为知乎很多业务提供推荐服务的技术和业务支持,比如支持社区各个推荐场景、知乎大学的推荐和搜索及其他多个新业务的接入等等。
在加入知乎之前,在百度工作多年,一直从事于机器学习和搜索引擎策略的研发工作。
知乎现在拥有接近 2 亿的注册用户规模,并已经产生超过1.1亿条的回答。
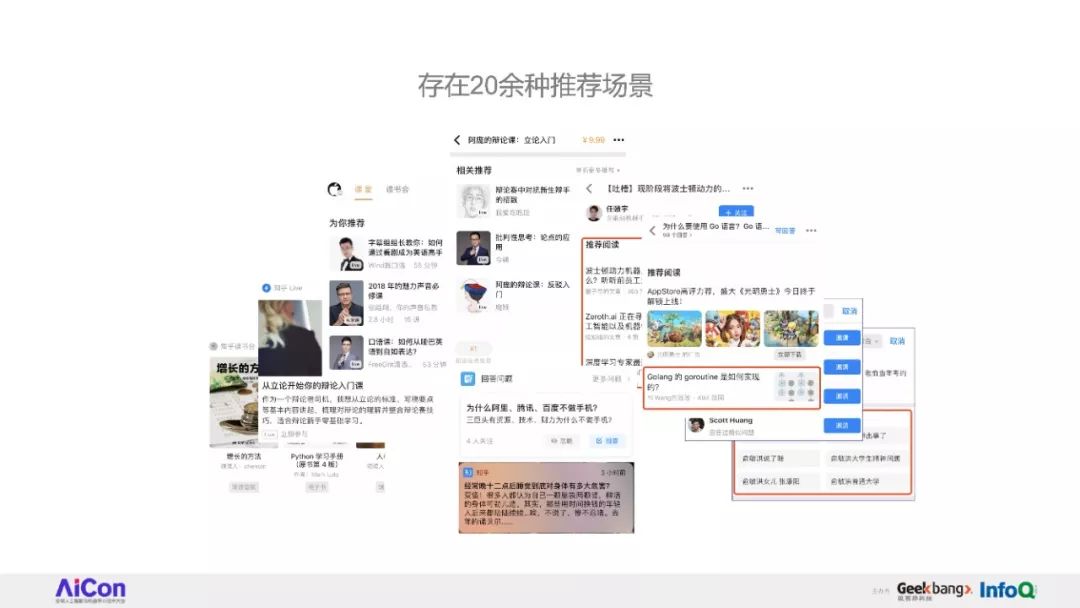
在链接人和知识的路径中,知乎拥有大量的推荐场景,需要一个通用的、并且支持快速业务接入的推荐系统框架。
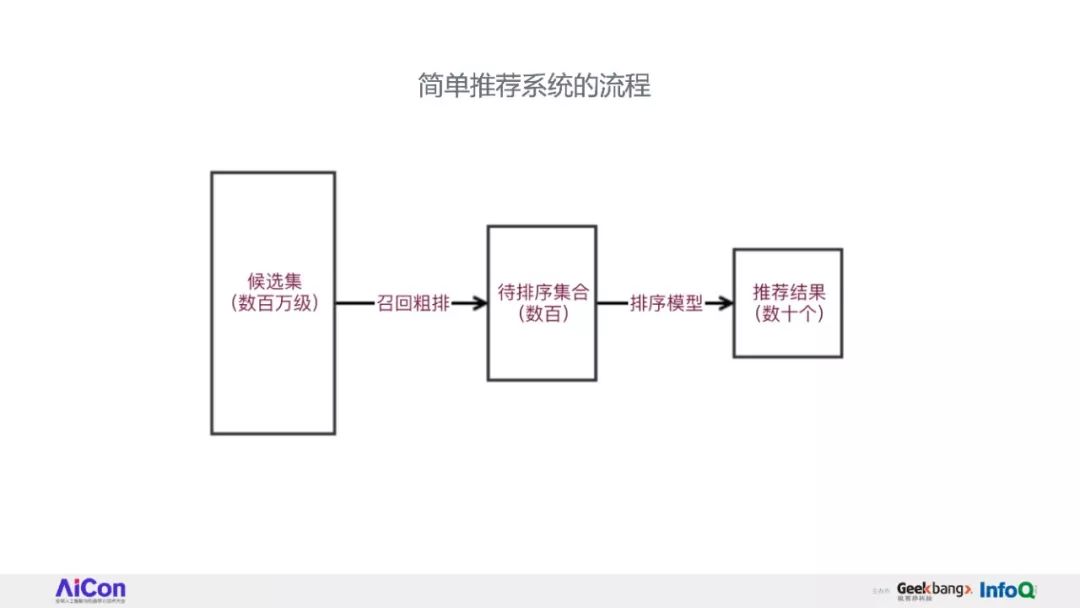
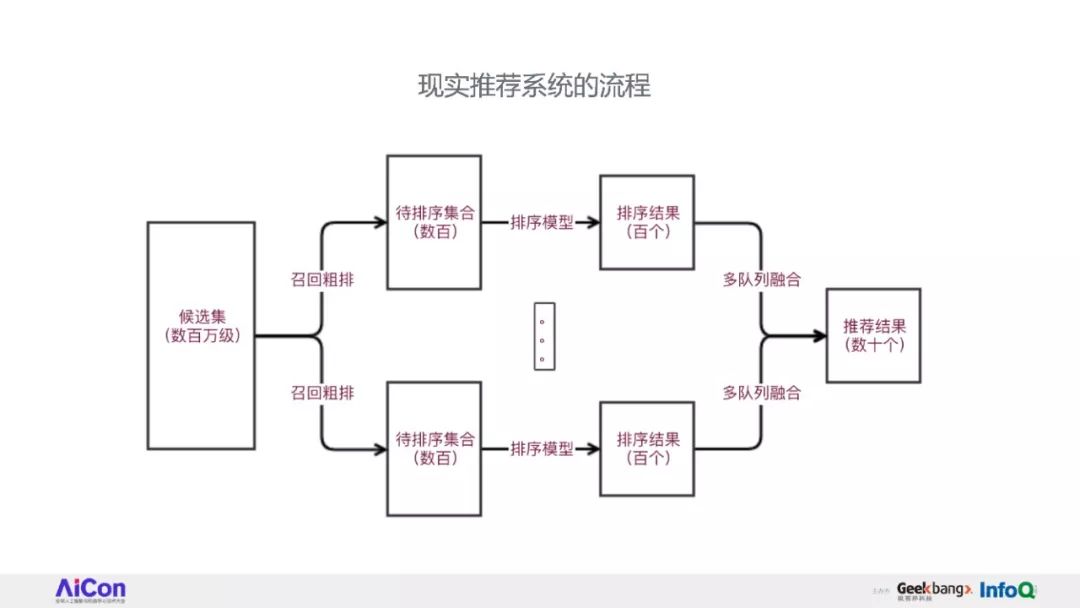
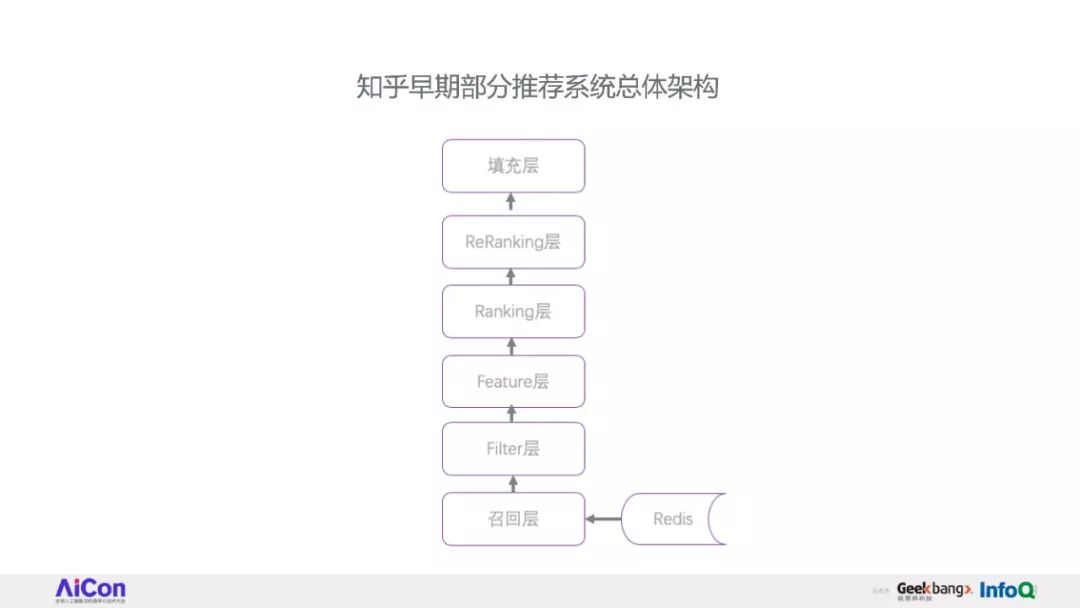
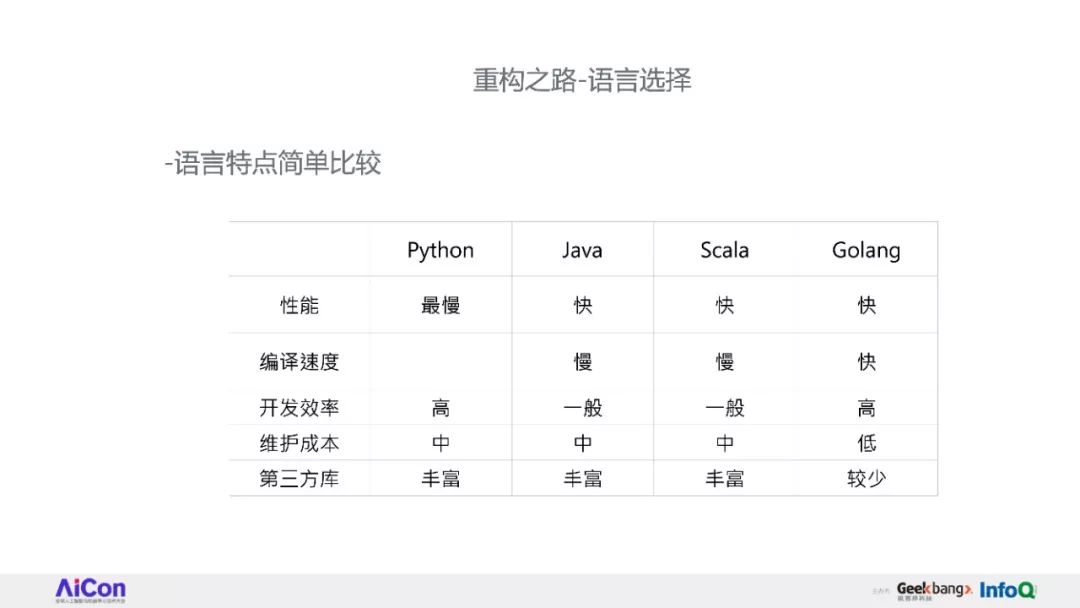
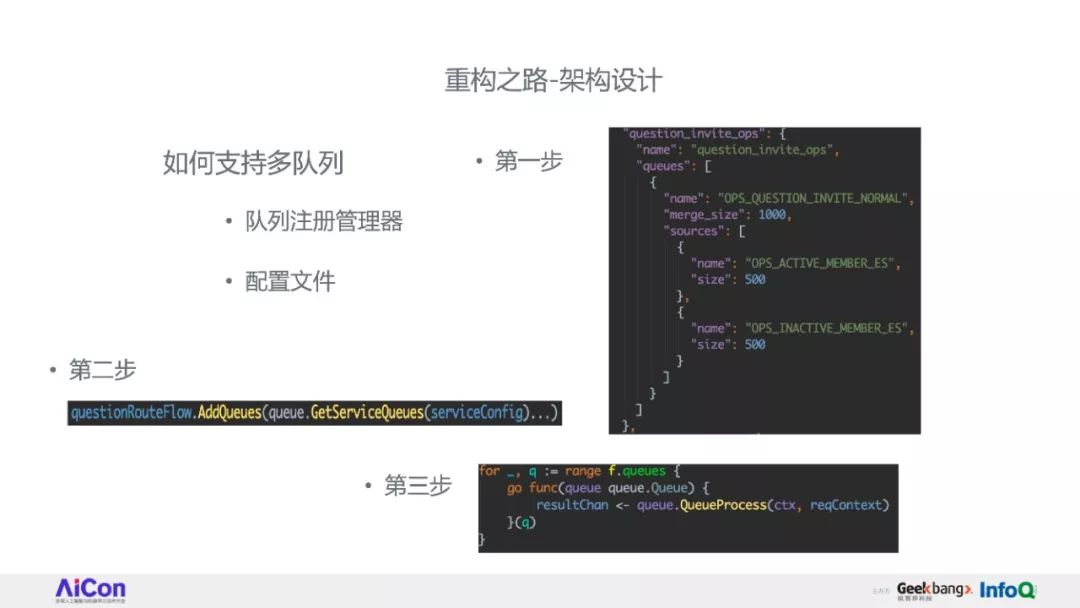
因此,我们花了比较久的时间重构了知乎的推荐系统框架。
将完整讲述知乎推荐系统的重构过程中的经验和心得,接着介绍一些与业务结合中遇到的问题和解决思路。
在推荐之路上,知乎是其中一家的践行者,听众将从本次演讲中对工业界的推荐系统有一个全局的了解,对实际工作遇到个各种推荐问题有更深的认识,并会了解到知乎解决这些问题的思路和方法。