印度理工学院 Akshay Kumar Gupta 近日发布了一篇论文,对视觉问答方面的数据集和技术进行了盘点和比较。机器之心对本文内容进行了摘要式的编译介绍,论文原文请访问:https://arxiv.org/abs/1705.03865

视觉问答(visual question answering/ VQA)是结合自然语言处理和计算机视觉技术的一种新兴任务。本文是一份视觉问答技术研究情况的调查,我们在文中列举了一些用于解决这个任务的数据集和模型。调查的第一部分详细介绍了用于 VQA 的不同数据集,并比较了各数据集的特点。调查的第二部分详细介绍了 VQA 的不同模型,分为四个类型:非深度学习模型、无注意机制(without attention)的深度学习模型、有注意机制(with attention)的深度学习模型以及其它模型。最后,我们比较这些模型的性能,并为今后的工作提供一些方向。
1 引言
视觉问答是最近几年出现的一个新任务,并引起了机器学习社区的关注(Antol 等,2015)(Wu 等,2016a)。该任务通常分为向计算机展示图像和向计算机询问有关图像的问题两个步骤。答案可以是以下任何形式:单词、短语、是/否回答、从几个可能的答案中选择或在空白处填写答案。
视觉问答任务具有重要性和吸引力,因为它结合了计算机视觉和自然语言处理领域。计算机视觉技术用来理解图像,NLP 技术用来理解问题。此外,两者必须结合起来才能有效地回答图像情境中的问题。这相当具有挑战性,因为传统上这两个领域使用不同的方法和模型来解决各自的任务。
本调查详细介绍了用于解决视觉问答任务的数据集和模型,并对这些模型在各数据集上运行的效果进行了比较。本文分为 4 个部分:第 2 部分介绍 VQA 数据集,第 3 部分介绍模型,第 4 部分讨论结果并提供一些未来的可能方向。
2 数据集
在过去 2-3 年中,出现了几个大型的面向 VQA 任务的数据集。表 1 是这些数据集的情况摘要。
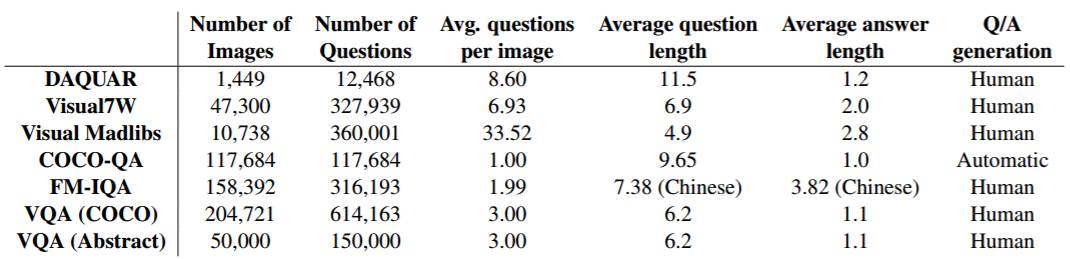
表 1:VQA 数据集
3 模型
随着深度学习技术的广泛普及,VQA 任务被提出时,深度学习领域各种计算机视觉和 NLP 技术已经有了很大发展。因此,文献中几乎所有关于 VQA 的工作都涉及深度学习方法,而不是采用更经典的方法,如图模型(graphical model)。在本部分第 1 小节中,作者详细介绍了几个没有用神经网络方法的模型,以及作者在这些模型中使用的几个简单基线(baseline)算法。第 2 小节介绍了无注意机制的深度学习模型。第 3 小节详细介绍了用于 VQA 的有注意机制的深度学习模型。所有模型的结果总结在表 2 和表 3 中。
(Kafle 和 Kanan,2016)提出了一个用于 VQA 的贝叶斯框架,他们用模型预测一个问题的答案类型,并用它来产生答案。可能的答案类型随着数据集的不同而有所不同。例如,对于 COCO-QA,他们考虑四种答案类型:对象、颜色、计数和位置。
给定图像 x 和问题 q,模型计算答案 a 和答案类型 t 的概率:
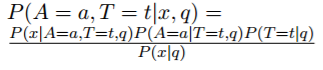
遵循贝叶斯定理。然后,计算所有答案类型边际分布概率得到 P(A=a|x,q)。对于给定的问题和答案,分母是常数可以忽略。
他们用三个独立的模型对分子中的 3 个概率进行建模。第 2 和第 3 个概率都使用 logistic 回归进行建模。问题的特征采用跳跃思维向量表征(skip-thought vector representation)(Kiros 等人,2015)(他们使用预训练的跳跃思维模型)。第 1 个概率为条件多元高斯模型,原理上与二次判别分析(Quadratic Discriminant Analysis)相似。此模型采用了原始图像特征。
作者还介绍了一些简单的基线算法,如仅将图像特征或仅将问题特征馈送到 logistic 回归,将图像和问题特征同时馈送到逻辑回归,以及将相同的特征馈送到多层感知器。他们在 DAQUAR、COCO-QA、Visual7W 和 VQA 数据集上进行了评估。
(Malinowski 和 Fritz,2014)这篇论文将基于问题和图像的答案概率建模为
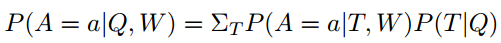 。这里 T 为隐藏变量,它对应于从问题语义分析器(semantic parser)得到的语义树(semantic tree)。W 是世界,代表图像。它可以是原始图像或从分割块获得的附加特征。使用确定性评价(deterministic evaluation)函数来评估 P(A|T,W)。使用简单的对数线性模型得到 P(T|Q)。这个模型被称为 SWQA。
。这里 T 为隐藏变量,它对应于从问题语义分析器(semantic parser)得到的语义树(semantic tree)。W 是世界,代表图像。它可以是原始图像或从分割块获得的附加特征。使用确定性评价(deterministic evaluation)函数来评估 P(A|T,W)。使用简单的对数线性模型得到 P(T|Q)。这个模型被称为 SWQA。
作者进一步将其扩展到多元世界的场景,用来模拟分割和分类标签的不确定性。不同的标签代表不同的 W,所以概率模型为
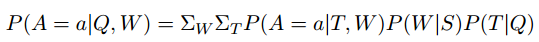
。
这里,S 是带有类标签分布的一组分割图像集。因此,从分布中抽样分割图像时将得到其对应的一个可能的 W。由于上述方程很复杂,作者仅从 S 中抽样固定数量的 W。
这个模型称为 MWQA。这些模型在 DAQUAR 数据集上进行评估。
VQA 的深度学习模型通常使用卷积神经网络(CNN)来嵌入图像与循环神经网络(RNN)的词嵌入(word embedding)来嵌入问题。这些嵌入以各种方式组合和处理以获得答案。以下模型描述假设读者熟悉 CNN(Krizhevsky 等人,2012)以及 RNN 变体,如长短时记忆(LSTM)单元(Hochreiter 和 Schmidhuber,1997)和门控循环单位(Gated Recurrent Unit/GRU)(Cho 等人,2014)。
一些方法不涉及使用 RNN。我们在开头已经讨论过这些模型。
(Zhou 等人,2015)提出了一种叫做 iBOWING 的基线模型。他们使用预训练的 GoogLeNet 图像分类模型的层输出来提取图像特征。问题中每个词的词嵌入都被视为文本特征,因此文本特征是简单的词袋(bag-of-word)。连接图像和文本的特征,同时对答案分类使用 softmax 回归。结果表明,该模型在 VQA 数据集上表现的性能与几种 RNN 方法相当。
(Ma 等人,2015)提出了一种仅用 CNN 的模型,称为 Full-CNN。模型使用三种不同的 CNN:一种用于编码图像,一种用于编码问题,一种用于将图像和问题的编码结合在一起并产生联合表征。
图像 CNN 使用与 VGG 网络相同的架构,并从该网络的第二层获取长度为 4096 的向量。这通过另一个完全连接的层,以获得大小为 400 的图像表征向量。句子 CNN 涉及 3 层卷积和最大池化(max pooling)。卷积感受野(receptive field)的大小设置为 3。换句话说,核函数(kernel)会计算该词及其相邻的邻居。联合 CNN 称为多元模态 CNN(multi-modal CNN),在问题表征上的卷积感受野大小为 2。每个卷积运算都在完整的图像上进行。将多元模态 CNN 的最终表征结果传入 softmax 层以预测答案。该模型在 DAQUAR 和 COCO-QA 数据集上进行评估。
以下模型同时使用了 CNN 和 RNN 算法。
该模型使用 CNN 对图像 x 进行编码并获得图像的连续向量表征。问题 q 使用 LSTM 或 GRU 网络进行编码,其中在时间 t 步骤的输入是问题的第 t 个词 q_t 的词嵌入与图像向量编码。问题编码是最终时间步骤获得的隐藏向量。作者使用的一个简单的词袋基线是将问题的所有词嵌入的总和作为编码。
解码答案可以用两种不同的方式,一种是对不同答案的分类,另一种是答案的生成。分类由完全连接层生成输出并传入覆盖所有可能答案的 softmax 函数。另一方面,生成由解码器 LSTM 执行。在每个时间点的 LSTM 将前面生成的词以及问题和图像编码作为输入。下一个词使用覆盖词汇表的 softmax 函数来预测。需要注意的一点是,该模型在编码器和解码器 LSTM 之间共享一些权重。该模型在 DAQUAR 数据集上进行评估。
该模型与 AYN 模型非常相似。该模型使用 VGG 网络的最终层来获得图像编码使用 LSTM 对问题进行编码。与之前的模型相反,在编码问题之前,它们将图像编码作为第一个「词」传入 LSTM 网络。该 LSTM 的输出先通过完全连接层,然后通过 softmax 层。





