最近有一个OLTP应用使用的Oracle数据库突然出现性能问题,DBA发现有一些delete语句执行时间骤长,消耗大量系统资源,导致应用响应时间变长积Q。
辅助信息:
-
应用已经很久未做过更新上线了。
-
据开发人员反馈,从之前的应用日志看,未出现处理时间逐步变长的现象。
-
这是一套RAC+DG的环境,11g的版本。
-
这次突然出现大量执行时间超长的SQL语句,是一条删除语句,delete from table where key1=:1 and key2=:2 and ...(省略此案例不会用到的其他条件),应用正常的处理逻辑中都会使用这条语句,因此并发较高,使用了绑定变量,key1和key2字段不是主键,但有索引,存在直方图。
接下来会通过理论和实验相结合的方式,了解这个问题所需要涉及的一些Oracle基础知识,最后再来分析这个案例。
本文目录:
一、基础知识介绍
-
可能造成SQL执行计划发生改变的一个示例
-
绑定变量窥探
-
查看绑定变量值的几种方法
-
rolling invalidation
-
聚簇因子(Clustering Factor)
-
查询执行计划的几种方法
-
AWR
-
ASH
-
SQL AWR
-
直方图
-
SQL Profile
二、案例分析
1、可能造成SQL执行计划发生改变的一个示例
什么情况下可能造成SQL执行计划发生改变?有很多种情况,这里抛砖引玉举一个例子。
实验: 创建测试表t1,其中name字段设置索引,取值为10000个A和1个B。
我们看下用查询条件name=’A’的SQL使用了什么执行计划。

再看下使用查询条件name=’B’的SQL用了什么执行计划。

显而易见,因为取值为A的记录占据了10000/10001接近100%的比重,即这查询条件返回了几乎表的所有数据,使用全表扫描的成本一般会小于使用索引的成本,由于TABLE ACCESS FULL会扫描表高水位线以下的数据块,且为多块读,即一次IO会读取多个数据块,具体数据块数量取决于参数db_file_multiblock_read_count,而INDEX RANGE SCAN则是单块读,同时若select字段不是索引字段的话,还需要回表,累积起来,IO次数就会可能很大,因此相比起来,全表扫描的IO可能会远小于索引扫描。
取值为B的记录占据了1/10001很小的比重,因此使用索引扫描,直接访问B*Tree二叉树,定位到这一条数据的rowid再回表查询所有select字段的成本要远小于扫描整张表数据的成本。
为了证明,可以查看这两条SQL对应的10053事件,如下是name=’A’的trace,可以看出全表扫描的成本值是49.63,索引扫描的成本值是351.26,全表扫描的成本更低一些。

如下是name=’B’的trace,可以看出全表扫描的成本值是49.40,索引扫描的成本值是2.00,索引扫描的成本值更低一些。

这个场景可以看出,Oracle的CBO模式会根据字段的取值比重调整对应的执行计划,无论如何,都会选择成本值最低的一个执行计划,这也是CBO优于以前RBO的地方,这里仅用于实验,因为一般OLTP的应用会使用绑定变量的写法,不会像上面这种使用常量值的写法,11g之前,可能带来的一些负面影响就是绑定变量窥探的作用,即对于使用绑定变量窥探的SQL语句,Oracle会根据第一次执行使用的绑定变量值来用于以后的执行,即第一次做硬解析的时候,窥探了变量值,之后的软解析,不再窥视,换句话说,如果上面实验的SQL语句使用了绑定变量,第一次执行时name=’A’,则接下来即使使用name=’B’的SQL语句仍会使用全表扫描,不会选择索引扫描,vice versa。相关的实验dbsnake的书中会有很详细的说明,可以参考。11g之后,有了ACS自适应游标的新特性,会根据绑定变量值的情况可以重新生成执行计划,因此这种问题得到了缓解,当然这些都是有代价的,缓解了绑定变量窥探的副作用,相应地可能会导致有很多子游标,具体的算法可以参考dbsanke的书,这儿我就不班门弄斧了。11g默认绑定变量窥探是开启的,由以下隐藏参数控制。

综上所述,针对这场景,如果值的选择性显著影响执行计划,则绑定变量的使用并不可靠,此时选择字面值的方式可能会更合适一些,如果值的选择性几乎相同,执行计划不会显著改变,此时使用绑定变量是最优的选择,当然前提是OLTP系统。
对于多次执行SQL语句,执行计划发生变化的情况可能还有很多,例如11g的新特性Cardinality Feedback带来的一些bug,包含直方图的字段作为查询条件但统计信息不准等。
2、绑定变量窥探
首先什么是绑定变量?
一条SQL语句在解析阶段,会根据SQL文本对应的哈希值在库缓存中查找是否有匹配的Parent Cursor,进而找出是否有可重用的解析树和执行计划,若没有则要重新生成一遍,OLTP系统中,高并发的SQL若每次均需要重复执行这些操作,即所谓的硬解析,消耗会比较大,进而影响系统性能,所以就需要使用绑定变量。绑定变量其实就是一些占位符,用于替换SQL文本中具体输入值,例如以下两条SQL:
select * from t1 where id = 1;
select * from t1 where id = 2;
在Oracle看来,是两条完全不同的SQL,即对应SQL文本哈希值不同,因为where条件中一个id是1,一个是2,1和2的ASCII是不同的,可实际上这两条SQL除了查询条件不同,其他的文本字符均一致,尽管如此,这种情况下,Oracle还是会重复执行解析的操作,生成各自的游标。

两条记录,说明Oracle认为这两条SQL是不同。
如果使用绑定变量:
select * from t1 where id = :1;
每次将不同的参数值带入:1中,语义和上面两条相同,但对应哈希值可是1个,换句话说,解析树和执行计划是可以重用的。
使用绑定变量除了以上可以避免硬解析的好处之外,还有其自身的缺陷,就是这种纯绑定变量的使用适合于绑定变量列值比较均匀分布的情况,如果绑定变量列值有一些非均匀分布的特殊值,就可能会造成非高效的执行计划被选择。
如下是测试表:

其中name列是非唯一索引,NAME是A的有100000条记录,NAME是B的有1条记录,值分布是不均匀的,上一篇文章中我们使用如下两条SQL做实验。
select * from t1 where name = 'A';
select * from t1 where name = 'B';
其中第一条使用的是全表扫描,第二条使用了索引范围扫描,过程和原因上篇文章中有叙述,此处就不再赘述。
如上SQL使用的是字面值或常量值作为检索条件,接下来我们使用绑定变量的方式来执行SQL,为了更好地说明,此处我们先关闭绑定变量窥探(默认情况下,是开启的状态),他是什么我们稍后再说。

首先A为条件。

显示使用了全表扫描。
再以B为条件。

发现仍旧是全表扫描,我们之前知道B值记录只有一条,应该使用索引范围扫描,而且这两个SQL执行计划中Rows、Bytes和Cost值完全一致。之所以是这样,是因为这儿用的未开启绑定变量窥探情况下的绑定变量,Oracle不知道绑定变量值是什么,只能采用常规的计算Cardinality方式,参考dbsnake的书,CBO用来估算Cardinality的公式如下:
Computed Cardinality = Original Cardinality * Selectivity
Selectivity = 1 / NUM_DISTINCT
收集统计信息后,计算如下:
Computed Cardinality = 100001 * 1 / 2
约等于50001。因此无论是A还是B值,CBO认为结果集都是50001,占据一半的表记录总量,自然会选择全表扫描,而不是索引扫描。
下面我们说说绑定变量窥探,是9i引入的一个新特性,其作用就是会查看SQL谓词的值,以便生成最佳的执行计划,其受隐藏参数控制,默认为开启。

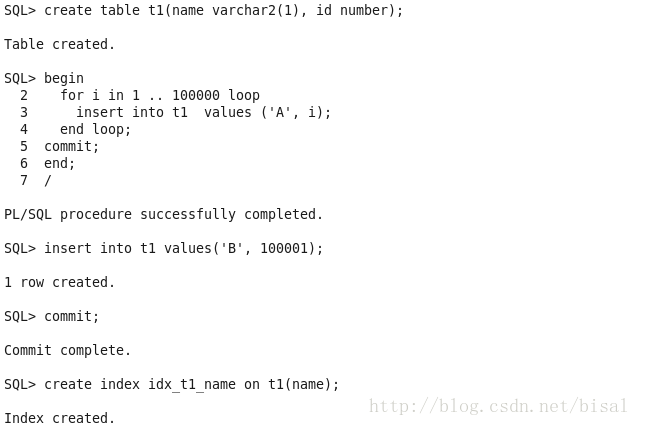
我们在绑定变量窥探开启的情况下,再次执行上述两条SQL(区别仅是不用explain plan,使用dbms_xplan.display_cursor可以得到更详细的信息),首先A为条件的SQL。
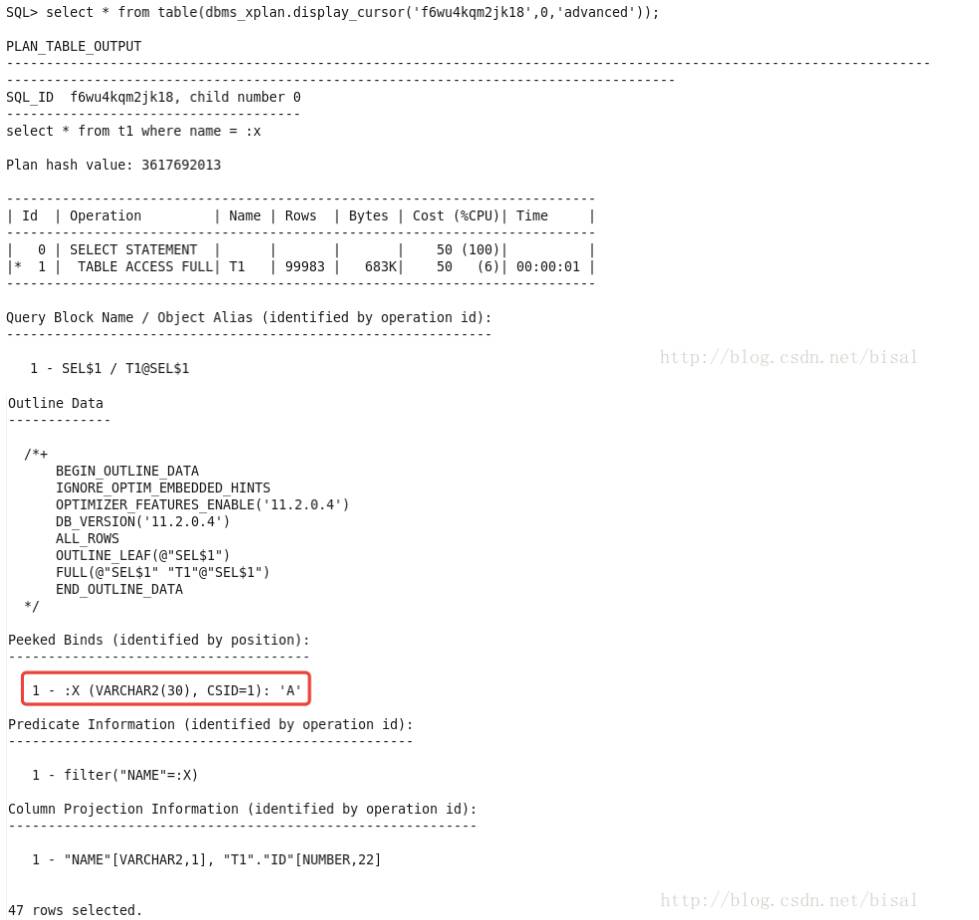
这次使用了全表扫描,窥探了绑定变量值是A。
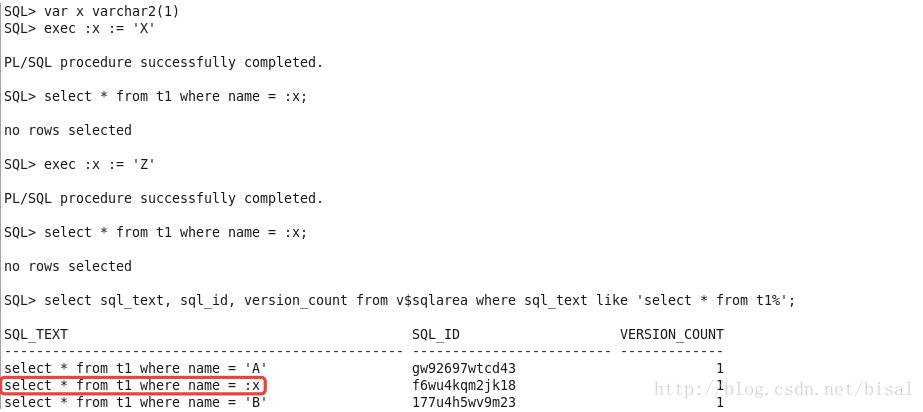
再使用以B为条件的SQL:
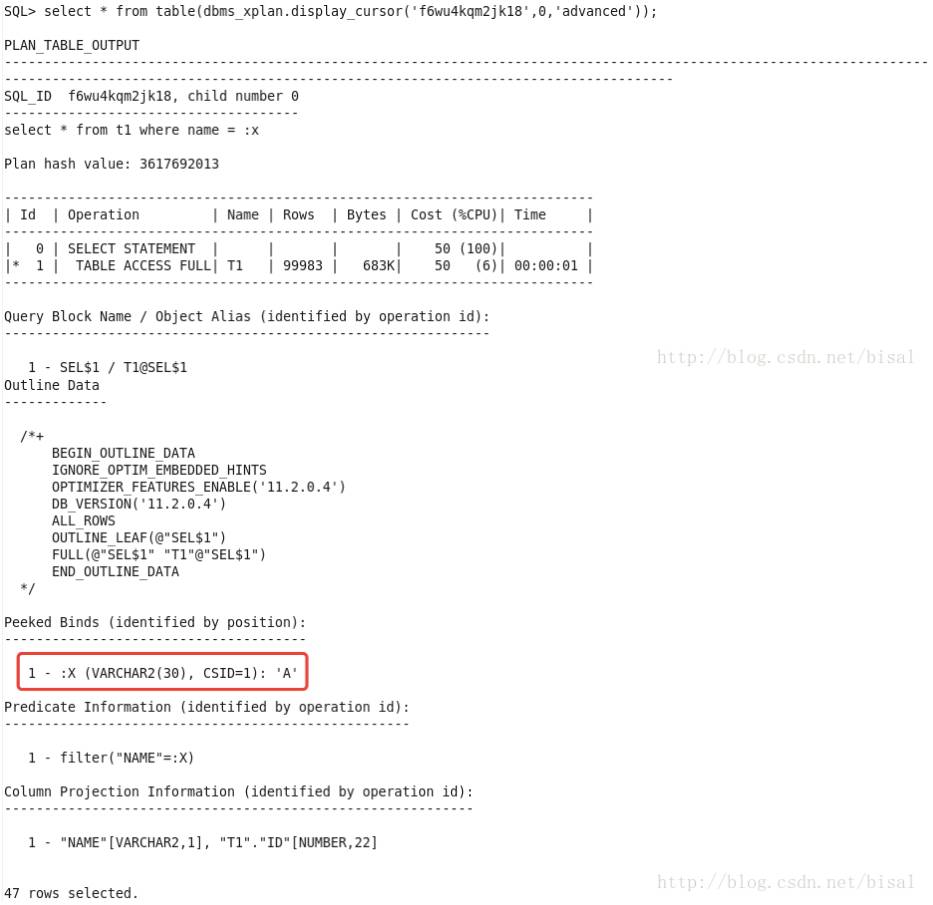
仍旧采用了全表扫描,绑定变量窥探值是A,因为只有第一次硬解析的时候才会窥探绑定变量值,接下来执行都会使用第一次窥探的绑定变量值。B的记录数只有1条,1/100001的选择率,显然索引范围扫描更合适。
为了让SQL重新窥探绑定变量值,我们刷新共享池:
alter system flush shared_pool;
此时清空了所有之前保存在共享池中的信息,包括执行计划,因此再次执行就会是硬解析,这次我们先使用B为条件。
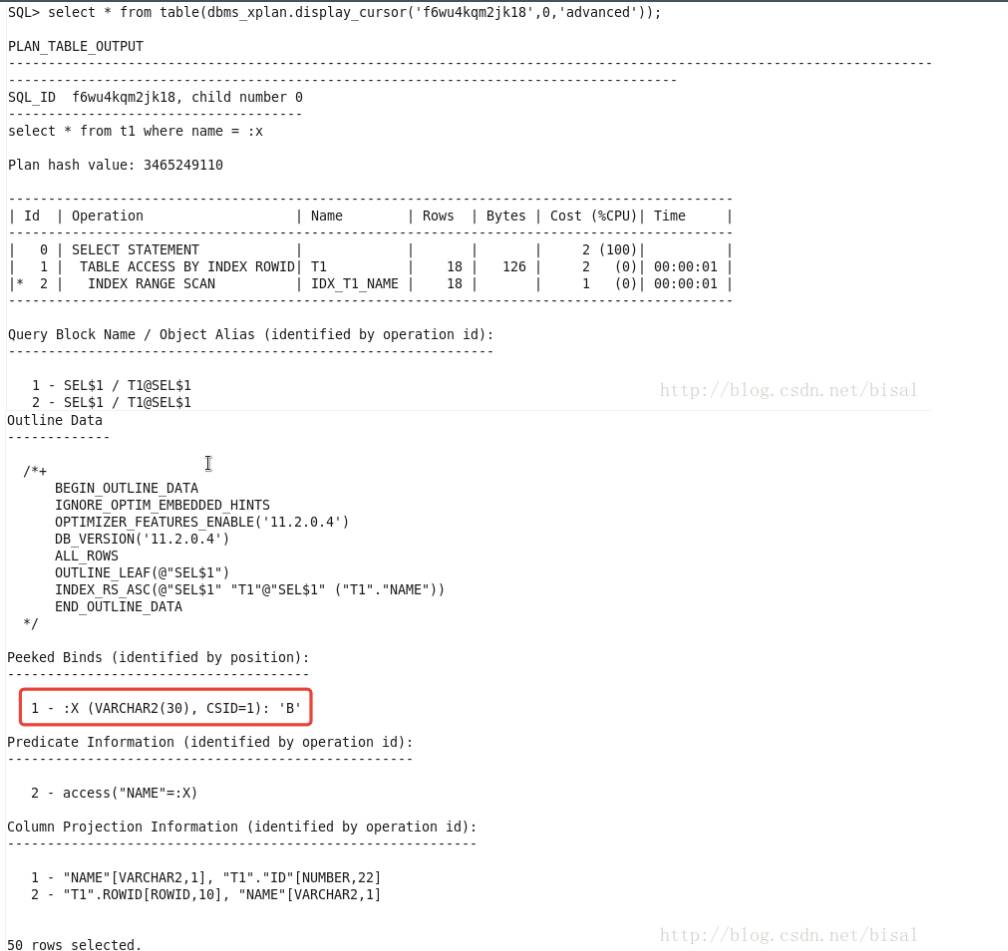
可见窥探了绑定变量值是B,因为可以知道这个绑定变量:x的具体值,根据其值分布特点,选择了索引范围扫描。
再用A为查询条件:

此时仍旧窥探绑定变量值为B,因此还会选择索引范围扫描,即使A值应该选择全表扫描更高效。
总结:
绑定变量窥探会于第一次硬解析的时候,“窥探“绑定变量的值,进而根据该值的信息,辅助选择更加准确的执行计划,就像上述示例中第一次执行A为条件的SQL,知道A值占比重接近全表数据量,因此选择了全表扫描。但若绑定变量列分布不均匀,则绑定变量窥探的副作用会很明显,第二次以后的每次执行,无论绑定变量列值是什么,都会仅使用第一次硬解析窥探的参数值,这就有可能选择错误的执行计划,就像上面这个实验中说明的,第二次使用B为条件的SQL,除非再次硬解析,否则这种情况不会改变。
简而言之,数据分布不均匀的列使用绑定变量,尤其在11g之前,受绑定变量窥探的影响,可能会造成一些特殊值作为检索条件选择错误的执行计划。11g的时候则推出了ACS(自适应游标),缓解了这个问题。
以上主要介绍了11g之前使用绑定变量和非绑定变量在解析效率方面的区别,以及绑定变量在绑定变量窥探开启的情况下副作用的效果。虽然OLTP系统,建议高并发的SQL使用绑定变量,避免硬解析,可不是使用绑定变量就一定都好,尤其是11g之前,要充分了解绑定变量窥探副作用的原因,根据绑定变量列值真实分布情况,才能综合判断绑定变量的使用正确。
3、查看绑定变量值的几种方法
上一章我们了解了,绑定变量实际是一些占位符,可以让仅查询条件不同的SQL语句可以重用解析树和执行计划,避免硬解析。绑定变量窥探则是第一次执行SQL硬解析时,会窥探使用的绑定变量值,根据该值的分布特征,选择更合适的执行计划,副作用就是如果绑定变量列值分布不均匀,由于只有第一次硬解析才会窥探,所以可能接下来的SQL执行会选择错误的执行计划。
有时可能我们需要查看某条SQL使用了什么绑定变量值,导致执行计划未用我们认为最佳的一种。以下就介绍一些常用的查看绑定变量值的方法。
使用level=4的10046事件,查看生成的trace文件。

可以看出绑定变量值是’Z’。
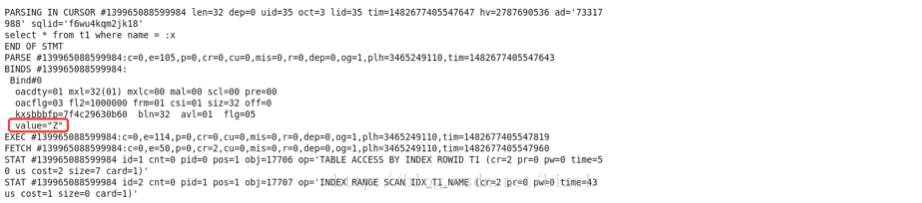
首先找出SQL对应的sql_id:
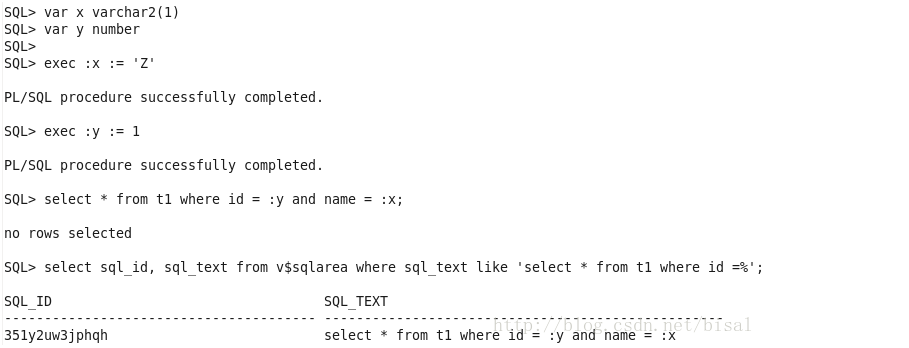
从v$sql_bind_capture可以看出两个绑定变量占位符以及对应的值。

这里有一点值得注意的就是,DATATYPE_STRING列的描述是“绑定变量数据类型的文本表示”,开始我认为就是绑定变量字段的数据类型,但实际看来不是,DATATYPE_STRING列只是来告诉你绑定变量列是字符型,还是数值型。

我们此时换一下绑定变量值,发现v$sql_bind_capture信息未变,dbsnake的书中曾说过当SQL执行硬解析时绑定变量值被捕获,并可从视图v$sql_bind_capture中查询。

对于执行软解析/软软解析的SQL,默认情况下间隔15分钟才能被捕获,为了避免频繁捕获绑定变量值带来的系统性能开销,而且从常理上认为,既然使用了绑定变量,最佳方式就是值分布均匀,只需要SQL执行第一次硬解析时窥探一下,后续执行的SQL执行计划应该比较稳定,因此只要能比较实时地查看第一次绑定变量值即可。间隔15分钟受隐藏参数_cursor_bind_capture_interval控制,默认值是900s,15分钟。

我们尝试将捕获绑定变量的间隔时间调短,该参数不支持session级别修改。

执行alter system级别操作。

等大约一分钟,此时可以从v$sql_bind_capture查询刚使用的绑定变量值。

(1) DBA_HIST_SQLBIND视图包含了v$sql_bind_capture的快照。

因此对应的SQL语句,和v$sql_bind_capture很像。
select name,datatype_string,value_string,datatype from DBA_HIST_SQLBIND where sql_id='...'
(2) 另一个视图,DBA_HIST_SQLSTAT记录了SQL统计信息的历史信息,他是基于一些标准,捕获来自于V$SQL的统计信息。可以使用如下SQL:
select
snap_id,
dbms_sqltune.extract_bind(bind_data,1).value_string bind1,
dbms_sqltune.extract_bind(bind_data,2).value_string bind2,
dbms_sqltune.extract_bind(bind_data,3).value_string bind3
from dba_hist_sqlstat
where sql_id = '...'
order by snap_id;
其中dbms_sqltune.extract_bind(bind_data,1).value_string取决于SQL中绑定变量的数量。
第一次执行这两条SQL时,并未有任何结果返回,我猜测可能是这条SQL不符合AWR采集的标准。从MOS中查到这篇文章:《How to Control the Set of Top SQLs Captured During AWR Snapshot Generation (文档 ID 554831.1)》,用其中的方法修改下AWR采集topnsql参数。

默认值是
含义是

此时重新执行SQL,默认AWR会一小时采集一次,此时可以手工采集AWR快照。

此时再次查询DBA_HIST_SQLBIND

再次查询DBA_HIST_SQLSTAT

绑定变量值可以使用很多方法获取,这里只是列举了三种最常见的方法,我从网上看到有朋友还有用wrh$_sqlstat、v$sql等视图查询的例子,没有深究,我觉得碰见问题时,可以快速使用一些常用的方法解决问题就可以了,当然时间充裕的话,建议还是多从原理层了解一些,做到触类旁通则最好。
4、rolling invalidation
有一条SQL,使用了绑定变量,查看V$SQLAREA发现version_count是2

查看V$SQL,发现有两条记录,分别对应了0和1两个child cursor:

再查看这两个child cursor对应的执行计划:
child cursor:0
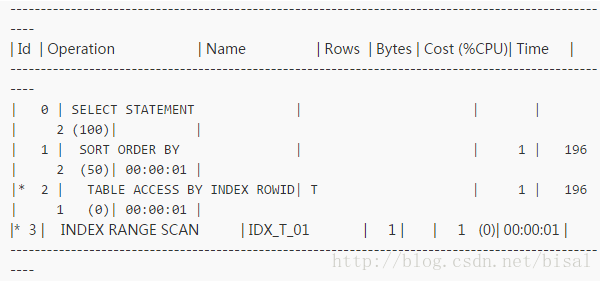
child cursor:1
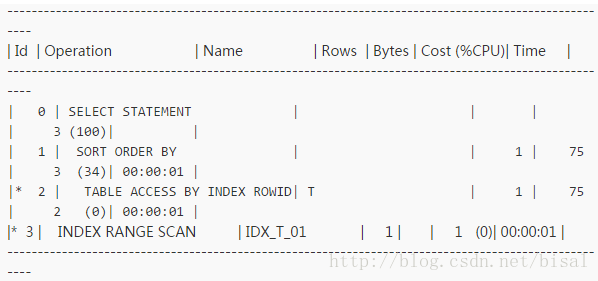
发现除了成本代价略有不同,其他访问路径完全一致。应用保证使用的相同用户执行这条SQL语句,绑定变量窥探关闭。问题就来了,为何同一条SQL有两个child cursor,且执行计划一致?
再抛一下,通过V$SQL_SHARED_CURSOR视图可以查看游标失效的原因,对比这两个cursor,不同之一就是这个ROLL_INVALID_MISMATCH字段的值,0号cursor值为N,1号cursor值为Y。

另外,REASON字段,0号cursor显示了内容,1号cursor该字段值为空。
Rolling Invalidate Window Exceeded(3)
这个问题通过Rolling Cursor Invalidations with DBMS_STATS.AUTO_INVALIDATE (文档 ID 557661.1)这篇文章能够很好地解释。
大体意思是在10g之前,使用dbms_stats采集对象统计信息,除非no_invalidate设为TRUE,否则所有缓存在Library Cache中的游标都会失效,下次执行时需要做硬解析。隐患就是对于一个OLTP系统,会产生一次硬解析风暴,消耗大量的CPU、库缓存以及共享池latch的争用,进而影响应用系统的响应时间。如果设置no_invalidate为FALSE,则现有存储的游标不会使用更新的对象统计信息,仍使用旧有执行计划,直到下次硬解析,要么因为时间太久,导致cursor被刷出,要么手工执行flush刷新了共享池,这两种情况下会重新执行硬解析,根据更新的对象统计信息,生成更新的执行计划。这么做其实还是有可能出现硬解析风暴,特别是OLTP系统,高并发时候,有SQL语句频繁访问。
使用dbms_stats.gather_XXX_stats的时候,有个参数no_invalidate:

默认是AUTO_INVALIDATE,这表示是由Oracle来决定什么时候让依赖的游标失效。
10g之后,如果采集对象统计信息使用的no_invalidate参数是auto_invalidate,则Oracle会采用如下操作,来缓解可能的硬解析风暴。
-
执行dbms_stats,所有依赖于这个已分析对象的缓存cursor游标会被标记为rolling invalidation,并且记录此时刻是T0。
-
下次某个session需要解析这个标记为rolling invalidation的cursor游标时,会设置一个时间戳,其取值为_optimizer_invalidation_period定义的最大值范围内的一个随机数。之所以是随机数,就是为了分散这些 invalidation的游标,防止出现硬解析风暴。参数_optimizer_invalidation_period默认值是18000秒,5小时。记录这次解析时间为T1,时间戳值为Tmax。但此时,仍是重用了已有游标,不会做硬解析,不会使用更新的统计信息来生成一个新的执行计划。
-
接下来这个游标(标记了rolling invalidation和时间戳)的每次使用时,都会判断当前时刻T2是否超过了时间戳Tmax。如果未超过,则仍使用已存在的cursor。如果Tmax已经超过了,则会让此游标失效,创建一个新的版本(一个新的child cursor子游标),使用更新的执行计划,并且新的子游标会标记V$SQL_SHARED_CURSOR中ROLL_INVALID_MISMATCH的值。
这些和我上面碰见的情况基本一致。
MOS是附带了一个实验,可以根据实验来体会下这种情况。
1.为了容易观察,设置_optimizer_invalidation_period为1分钟。

2.创建测试表,并采集统计信息。

3.执行一次目标SQL,并查看V$SQL_SHARED_CURSOR信息。

此时查看这条SQL的解析和执行次数都是1。

4.再执行一次目标SQL,select count(*) from X;,查看这条SQL的解析和执行次数是2。

有人曾说过,11g中未必会按照_optimizer_invalidation_period参数定义的时间产生新的子游标,我上面用的环境是11g,确实如此,等了2分钟,执行目标SQL,仍只有一个子游标。这样的好处有人也说了,就是更加的随机,因为如果严格按照参数设置的时间失效,则有可能频繁使用的游标会在超时后某一时刻集中做硬解析,还是会有资源的影响,只是时间推迟了,因此如果是在超时值基础上又有随机分布,则可能会将硬解析的影响降到最低。
又等了一段时间,再查询V$SQL。

确实产生了两个子游标,这里需要注意FIRST_LOAD_TIME的时间是一样的,因为他是parent父游标的创建时间,显然这两个子游标肯定是对应同一个父游标,不同的就是LAST_LOAD_TIME,这是子游标的使用时间。

再看看V$SQL_SHARED_CURSOR。

两个子游标信息,只有一个R项值有差别,R是ROLL_INVALID_MISMATCH,0号子游标是N,1号子游标是Y,看看官方文档对这个字段的说明。

表示的就是标记为rolling invalidation的游标,已经是超过了时间窗口,此时0号子游标已经过期,1号子游标使用最新的统计信息,来生成最新的执行计划。
这就解释了为何同一条SQL,执行计划一致,但却有两个子游标的情况。
MOS中还描述了一些游标使用的场景:
-
如果一个游标被标记为rolling invalidation,但是再不会做解析,则这个游标不会失效,最终还是可能根据LRU被刷出共享池。
-
如果一个游标被标记为rolling invalidation,后面只会解析一次,那么这个游标依然不会失效(仅仅使用时间戳标记),最终还是可能根据LRU被刷出共享池。
-
频繁使用的游标,在超过时间戳Tmax值后,下次解析时就会被置为失效。
很明显,上面的这些方法是有效的,因为失效标记仅仅适用于这些频繁重用的游标,对于其他场景的游标可以忽略,未有影响。
5、聚簇因子(Clustering Factor)
聚簇因子,Clustering Factor,听着名字就很高大上,很学术。题外话,记得几年前的一次内部分享,dbsnake介绍一案例的时候,曾问过在场同事其中涉及的一个知识点是什么,如果知道就意味着你对索引的了解很深入,可惜当时没人反应,作为小白的我自然也不知道,当时的这个知识点就是聚簇因子,下来我仔细了解了下,确实这些东东,如果经常用到自然脱口而出,可惜这种机会只能靠自己。
我们先看下官方对CF介绍。

索引聚簇因子衡量的是索引字段存储顺序和表中数据存储顺序的符合程度。两者存储顺序越接近,聚簇因子值就越小。
聚簇因子的用处在于可以粗略估算根据索引回表需要的IO数量。
文中还举了一个例子,如下表EMPLOYEES中数据是按照last name的字母顺序存储的。

如果last name是索引字段,可以看出索引的存储顺序(blockXrowY可以抽象地看作rowid),即连续的几个索引键值指向的是同一个数据块。

如果此时id是索引字段,可以看出连续的几个索引键值对应的可能是不同的数据块,而且有可能几个顺序间隔不多的键值指向的是同一个数据块,如果这是一个庞大的索引和表,buffer cache再小一些,使用id字段作为检索条件的SQL并发再高一些,很可能之前刚从数据文件中加载至buffer cache,马上就会根据LRU算法age out,但一会又再次加载至buffer cache,反反复复,各种latch等的资源争用就会累积起来,进而可能对系统性能造成影响。

DBA/ALL/USER_INDEXES视图有一列CLUSTERING_FACTOR,表明该索引的聚簇因子值。

摘自dbsnake书中对于CF值计算算法的叙述:
-
CF初始值是1。
-
Oracle首先定为至目标索引最左边的叶子块。
-
从最左边的叶子块的第一个索引键值所在的索引行开始顺序扫描,Oracle比较当前索引行的roid和他之前相邻的索引行的rowid,若这两rowid并不是指向同一个表块,则将聚簇因子值递增1,如果指向同一个rowid,则不改变当前聚簇因子值。比对rowid的时候并不需要回表访问相应的表块。(注:原因就是根据rowid的值是可以计算出block信息)
直到顺序扫描完目标索引所有叶子块的所有索引行。
-
扫描操作完成后,聚簇因子当前值就是会被存储在数据字典中,就是上面视图中CLUSTERING FACTOR列。
-
说了这么多,CF有什么实际意义?个人理解,CBO模式的优化器会综合考虑各种因素来判断一条SQL不同执行计划对应的成本值,选择成本值最低的一个执行计划,CF实际影响的是根据索引回表需要的IO数量,自然也在其考虑的范围之内,因此CF值的高低有时会影响CBO对不同执行计划的选择。
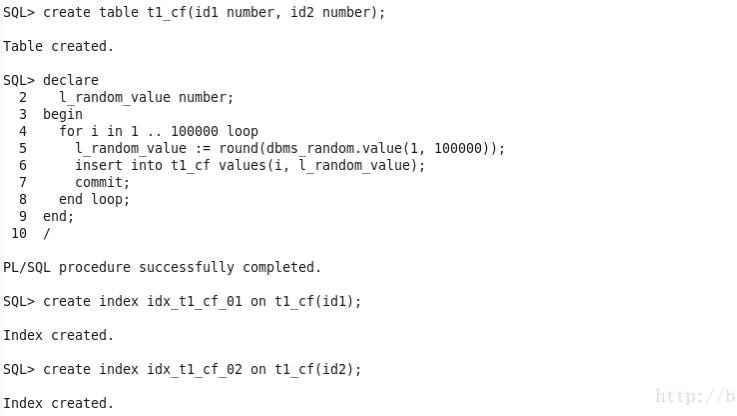
实验:
测试表有两列NUMBER类型的字段,其中id1是按照顺序存储,id2是无序存储,id1和id2各有一个非唯一索引。

DBA/ALL/USER_INDEXES中有一注释:
“Column names followed by an asterisk are populated only if you collect statistics on the index using the DBMS_STATS package.“
即使用DBMS_STATS包收集索引统计信息的时候,CLUSTERING_FACTOR才会有值。
从dba_indexes中可以看出id1对应的索引CF只有204,id2对应的索引CF有99481,表的数据量是100000,就是说这个id2中所有叶子块的索引行排列顺序几乎和表中数据存储的顺序完全不一致。

使用id1 between 1 and 1000作为检索条件,可以看出使用了id1索引范围扫描。

使用id2 between 1 and 1000作为检索条件,这次却选择了全表扫描,没有选择id2索引扫描。

如果我们强制使用id2索引,无论从Cost,还是consistent gets,都要高于全表扫描。

究其原因,还可以参考dbsnake书中对于索引范围扫描的算法。
IRS Cost = I/O Cost + CPU Cost
I/O Cost = Index Access Cost + Table Access I/O Cost
Index Access Cost = BLEVEL + CEIL(#LEAF_BLOCKS * IX_SEL)
Table Access I/O Cost = CEIL(CLUSTERING_FACTOR * IX_SEL_WITH_FILTERS)
我们可以检索视图发现,id1和id2的索引LEAF_BLOCKS等列值均相等,只有CLUSTERING_FACTOR不同,进而可以粗略认为索引范围扫描的成本和聚簇因子的大小成正比。
进而我们可以这么尝试,人为将id2的索引聚簇因子值改为200。

可以看出此时选择了id2的索引范围扫描。

但相应consistent gets值依旧很大,我猜原因就是计算执行计划成本值,CBO会根据相关统计信息值来计算,我们人为设置了索引的聚簇因子为一个很小的值,计算出来的成本值小于全表扫描,因此选择了使用索引的执行计划,但实际回表等操作需要消耗的资源其实并没有少。
如果要消除聚簇因子的影响,只能对表中数据按照目标索引键值的顺序重新存储,例如,create table t1_cf_0 as select * from t1_cf order by id2;
但这么做带来的问题就是,可能id2的聚簇因子下降了,相对id1的聚簇因子上升了,有些顾此失彼的意思。因此根据实际业务需求,选择正确的表数据组织形式,或者只能通过其他优化方式,来减小聚簇因子的影响。
之前曾发过一个如何让CF值小的讨论帖,有兴趣的朋友可以参考,
http://www.itpub.net/thread-1910003-1-1.html
总结:
-
聚簇因子表示索引键值的排列顺序和表中数据排列顺序的相似程度。
-
可以粗略认为索引范围扫描的成本,和聚簇因子的大小成正比,从索引范围扫描的计算方法可以推出这个结论。
-
是否需要重新组织表中数据存储顺序,以降低某一个索引的聚簇因子值,需要结合实际需求来判断,因为若表中存在多个索引,很可能造成顾此失彼的情况。
由于篇幅过长,今天先与大家分享到这里。下一篇将分享剩下的
几个知识点及案例分析,
敬请期待……





