不同的深度生成模型之间存在怎样的共性?近日,来自 CMU 和 Petuum 的四位研究者 Zhiting Hu、Zichao Yang、Ruslan Salakhutdinov 和邢波在 arXiv 上发表了一篇论文介绍了他们的研究成果,即构建了 GAN 和 VAE 深度生成建模方法之间的形式联系。机器之心对该研究论文进行了摘要介绍,更多详情请查阅原论文。
论文:关于统一深度生成模型(On Unifying Deep Generative Models)
论文地址:https://arxiv.org/abs/1706.00550

摘要
深度生成模型(deep generative model)近来年已经取得了令人瞩目的成功。其中,生成对抗网络(GAN)和变分自编码器(VAE)这两种强大的深度生成模型学习框架被普遍认为是两种不同的范式,并且分别都得到了广泛的独立研究。本论文通过对 GAN 和 VAE 的一种新的形式化(formulation)而构建了深度生成建模方法之间的形式联系(formal connections)。我们表明,GAN 和 VAE 本质上是分别在相反的方向上使用相反的隐含/可见处理(reversed latent/visible treatments)来最小化 KL 距离,从而延展典型的 wake-sleep 算法的两个学习阶段。这个统一的视角能提供一种强大的工具,可用于分析各种现有的模型变体,而且可以使得我们以一种基于原理的方式跨研究方向地交换思想。比如说,我们可以将 VAE 文献中的重要性加权(importance weighting)方法迁移用于提升 GAN 学习,也可使用对抗机制来增强 VAE。定量实验表明了这种导入的扩展(imported extensions)的通用性和有效性。
3 搭建不同方法之间的桥梁
在 GAN 中,生成模型的训练方式是通过将生成的样本传递到一个鉴别器,并最小化由该鉴别器所评估得到的误差。直观来看,学习上对于假样本的依赖类似于 wake-sleep 算法中的睡眠阶段(sleep phase)。相反,VAE 通过重构被观察的真实样本来训练其生成模型,这与清醒阶段(wake phase)相似。这一节对这些联系进行了形式化的探索。
为了便于本论文的呈现和构建符号标记方法,我们首先使用我们提出的形式化对对抗域适应(ADA/Adversarial Domain Adaptation)进行了新的解释。然后我们表明 GAN 是 ADA 的一种带有退化的源域(degenerated source domain)的特例,我们还通过对目标(objective)的 KL 距离解释而揭示了其与 VAE 和 wake-sleep 算法的紧密关系。表 1 列出了这些方法中每个组件的对应关系。

表 1:在我们提出的形式化方法中,不同方法之间的对应关系
-
3.1 对抗域适应(ADA)
-
3.2 生成对抗网络(GAN)
-
3.3 变分自编码器(VAE)
-
3.4 Wake-Sleep 算法(WS)
4 应用
我们通过我们提出的形式化而建立了 GAN 和 VAE 之间的紧密对应关系,这不仅能让我们更加深入地理解现有的方法,而且还能让我们从这两大类算法的交织中汲取灵感,从而开发出更强的变体。在这一节,我们通过直接从其它方法导入思想,给出了 GAN 和 VAE 各自的扩展示例。
5 实验

表 2:左:vanilla GAN 及其重要性加权的扩展的 Inception 分数。中:class-conditional GAN 及其 IW 扩展的生成的分类准确度。右:半监督 VAE 及其对手激活的变体在 MNIST 测试集上的分类准确度,使用了不同大小的真实标注的训练样本。
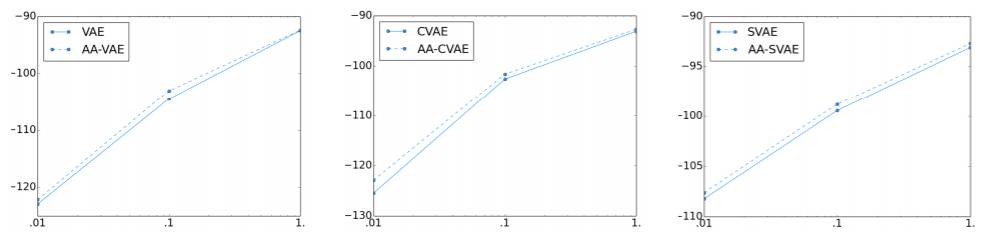
图 1:在 MNIST 测试集上的下限值。X 轴表示用于学习的训练数据的比例(0.01、0.1 和 1)。Y 轴表示下限值。实线表示基础模型;虚线表示对手激活的模型。左:VAE vs. AA-VAE;中:CVAE vs. AA-CVAE;右:SVAE vs. AA-SVAE,其中剩余的训练数据被用作无监督数据。

更多有关GMIS 2017大会的内容,请点击「阅读原文」查看机器之心官网 GMIS 专题↓↓↓






