提取基因对应的蛋白质官方名
最开始,是需要将基因跟其编码的蛋白质对应起来,找遍了各种数据库都没发现有相关的注释文件,Uniprot作为处理蛋白质的大佬,结果里都有,肯定有办法能够满足需求。
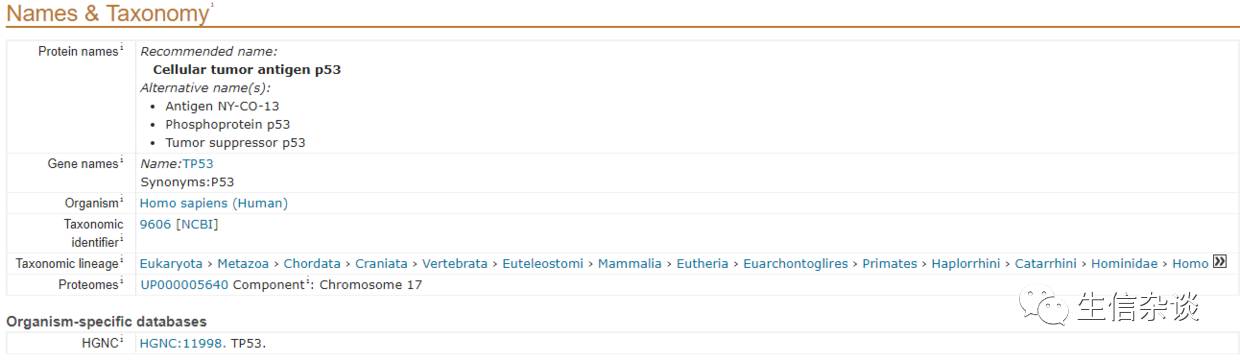
搜索TP53得到的结果页面,明显有各种p53的蛋白质名称
所幸的是,我完全没想用爬虫直接爬人家,而是戳了一下FAQ
发现人家有官方API,可以供我们胡作非为
Uniprot官方提供了各种API来满足各种稀奇古怪的需求
所有API:http://www.uniprot.org/help/api

各种功能的API介绍
Uniprot API的使用
ID信息转换
满足我需求的最重要的部分就是各种ID信息的转换和提取
ID转换相关:http://www.uniprot.org/help/api_idmapping
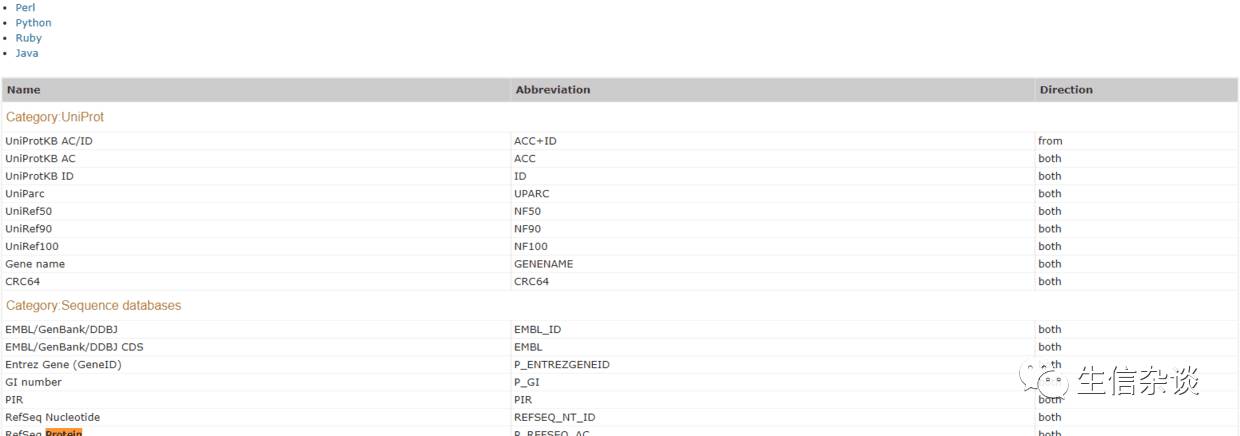
各种能够转换的ID,上边还有四种常用语言的示例
ID转换相关的页面里包含了所有的能够互相转换的各种ID
相应的,人家提供了多种不同代码的示例,以python为例:
python的示例基于python2
import urllib,urllib2url = 'http://www.uniprot.org/uploadlists/'params = {
'from':'ACC', 'to':'P_REFSEQ_AC',
'format':'tab',
'query':'P13368 P20806 Q9UM73 P97793 Q17192'}data = urllib.urlencode(params)request = urllib2.Request(url, data)contact = "" request.add_header('User-Agent', 'Python %s' % contact)response = urllib2.urlopen(request)page = response.read(200000)
由于我是python3的使用者,所以,没法拿来主义,经过简单修改就正常使用了
经过对众多ID的测试之后发现,其他ID转化成ACC的时候,包含的信息量格外的多,其中就有我急需的蛋白质名称,因此,通过将一个基因名转化成ACC来测试一下看看,能不能提取到该基因编码蛋白的所有名称
from urllib.parse import urlencodefrom urllib.request import urlopen, Requestdef test(query=['TP53']):
url = 'http://www.uniprot.org/uploadlists/'
params = {
'from': 'GENENAME',
'to': 'ACC', 'format': 'tab',
'query': ' '.join(query)
}
data = urlencode(params).encode()
request = Request(url, data)
contact = "[email protected]"
request.add_header('User-Agent', 'Python %s' % contact)
response = urlopen(request)
page = response.read(200000)
print(page.decode('utf-8'))
但是,解码出来的是一个以\n \t分隔的完整字符串,为了能够正常提取所需信息,需要对其进行分割
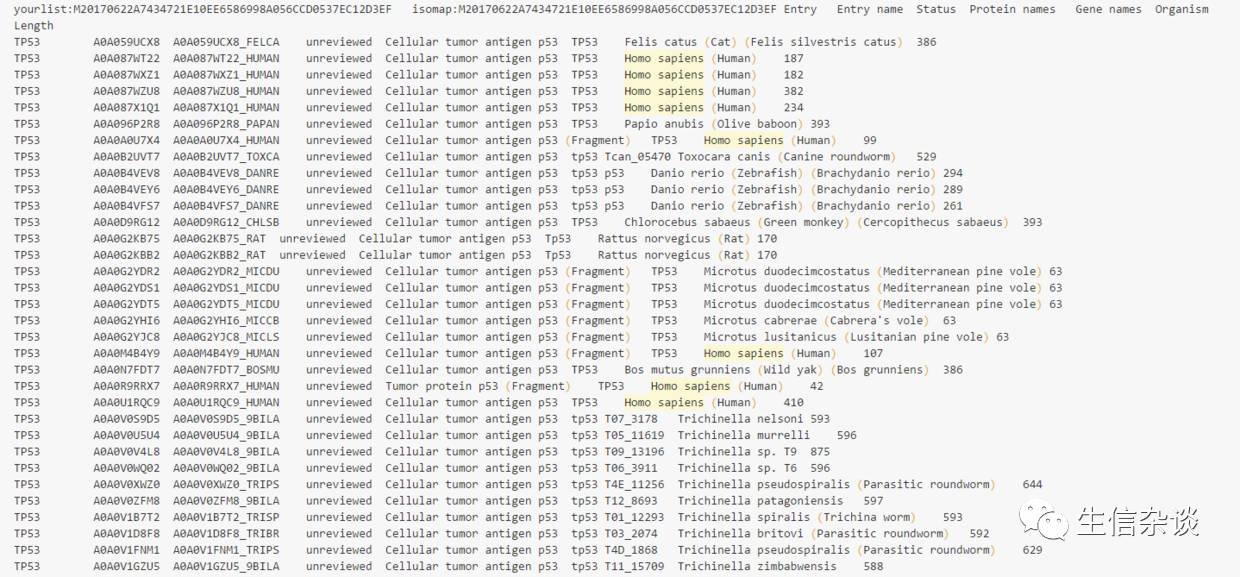
print出来当然就是一个文本文件的样子
split_(page.decode('utf-8')) def split_(data):
data = data.split('\n')
resutls = set() for line in data:
if 'Homo sapiens' in line:
protein_name = line.split('\t')[-4]
protein_name = protein_name.split(' (')[0]
results.add(protein_name) return resultsdef split_(data):
reutrn set(line.split('\t')[-4].split(' (')[0] for line in data if 'Homo sapiens' in line)

分割的成果
最终,我们就能获取到TP53基因对应的蛋白质名称了

TP53编码蛋白的所有名称
然后通过反复的爬取,将结果储存为json,或者直接存到数据库中,方便以后的取用都方便的很
如果要用模糊匹配来验证某些东西,推荐使用fuzzyfinder和fuzzywuzzy这两个python模块
其次,还有一个mygene的模块用来提取各种基因的信息也是极妙的,配合上这个API可以做很多幺蛾子。
特别需要注意的一点就是,如果要短时间内大批量的调用这个API,随机设一个sleep延迟吧,如果给对方造成太大的服务器压力,给人家惹麻烦,如果人家觉着需要维护,或者难以维持,直接暂停提供服务,,,

是的,我就是这么恶俗,就是这么喜欢这图









