来源:eff.org
原始作者:Peter Eckersley,Yomna Nasser
后期贡献:Gennie Gebhart,Owain Evans
译者:文强、刘小芹、胡祥杰
【新智元导读】
计算机在哪些领域已经超越了人类?准确地回答这个问题有助于我们更好地理解 AI 和自己。非盈利组织电子前哨基金会(EFF)的几位研究员整理了一份可能是目前最完善的资料,梳理了计算机已经超越人类水平的任务列表。一项项看过去,不啻纵览人工智能的发展,同时也能帮助我们将目光放到接下来要解决的问题上。列表持续更新,欢迎大家补充。

这是一个试验项目,旨在从AI研究的文献收集问题和指标/数据集,跟踪人工智能的进展情况。在这个项目页面你可以查看特定子领域,或查看AI/ML的整体进展现状。你可以把它作为报告你的新成果的地方,或作为寻找可以受益于新的数据集/指标的问题的地方,或作为一个数据科学项目的来源。
EFF 的研究人员 Peter Eckersley 和 Yomna Nasser 想要知道 AI 的发展进程,从而对其潜在应用得出更好的理解。在 EEF 的另外两名研究人员 Gennie Gebhart 和 Owain Evans 的辅助下,他们汇集了大量的资料——为了理解问题,先从收集资料开始。
除了零散的论文和文献,他们还参考了以下资料:
-
Rodrigo Benenson 的 "Who is the Best at X / Are we there yet?"
-
Jack Clark & Miles Brundage 的《AI 进步衡量指标》
-
Sarah Constantin 的《Performance Trends in AI》
-
Katja Grace《Algorithmic Progress in Six Domains》
-
瑞士计算机国际象棋协会《History of Computer Chess performance》
-
Qi Wu 等人《Visual Question Answering: A survey of Methods and Datasets》
-
Eric Yuan的《Comparison of Machine Reading Comprehension Datasets》
最终,
Peter Eckersley 等人整理出一份海量的资料,可以用以下目录归纳:
1. 分类方法
2. 定义和导入数据的源代码
3. 问题,指标和数据集
A. 玩游戏
a. 抽象策略游戏
b. 实时视频游戏
B.视觉和图像建模
a. 图像识别
b. 视觉问题回答
c. 视频识别
d. 生成图像
C. 书面语言
a. 阅读理解
b. 语言建模
c. 会话
d. 翻译
D. 口语
a. 语音识别
E. 科学和技术的能力
a. 解决有限的,明确的技术问题
b. 阅读技术论文
c. 解决现实世界中的技术问题
e. 从规范生成计算机程序
F. 学会更好地学习
a. 概括
b. 迁移学习学习
c. One-shot学习
G. 安全与规范
a. “对抗实例”和对分类器的操控
b. 强化学习智能体的安全问题
c. 自动化黑客系统
d. 自动驾驶汽车的行人检测
H. 透明度和可解释性
I. 公平和偏见
J. 隐私问题
4. 到目前为止的分类标准和记录进度
A. 按类型/类别划分的问题和衡量标准
5. 如何为这个项目贡献
A. 导入数据的注意事项
分类方法如下图所示:
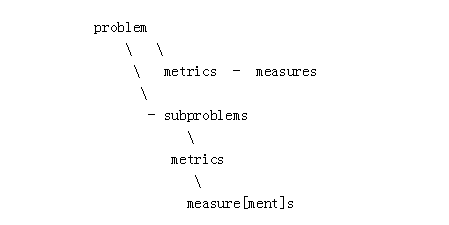
问题(problem)描述了学习一类重要任务的能力。
指标(metrics)应该以“给定Y类训练数据,软件能够学习做X任务”的理想形式制定。
衡量(measurement)是一个特定算法(algorithm)在一个特定实例(instance)上以特定的指标(metric)能够得到的分数。
问题被标记了属性,例如:视觉,抽象游戏,语言,现实世界建模,安全,等。其中一些问题与人类表现有关(当然这是非常任意的标准,但我们熟悉这样的标准):
-
agi:大部分正常人都可以做到的,AGI能够做到。
-
Super:人类能做到的最高水平,或人类组织能够做到的。
-
Verysuper:人类和人类组织目前都无法做到的。
一个问题可能有“子问题”,包含简单的案例和普遍性地解决问题的先决条件。
“指标”(metric)是衡量问题进展的一种方式,通常与测试数据集有关。给定的一个问题同参更会有几个metric,但有时是从0开始,并需要提出一些metric…
measure[ment]是在给定metric上,特定时间,特定代码库/团队/项目的得分。
1. 图像分类
视觉领域中,最简单的子问题可能是图像分类,也即让计算机识别图像中存在什么物体。从 2010 年到 2017 年,ImageNet 竞赛一直是业界密切关注的热点。

ImageNet 数据集示例
图像分类不仅包括识别图像中的单个物体,还包括对它们进行定位,并且确定哪些像素属于哪个物体。MSRC-21 指标是专门为此任务而建的:
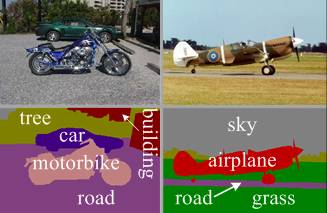
MSRC-21 示例
2. 看图回答问题(Visual Question Answering)
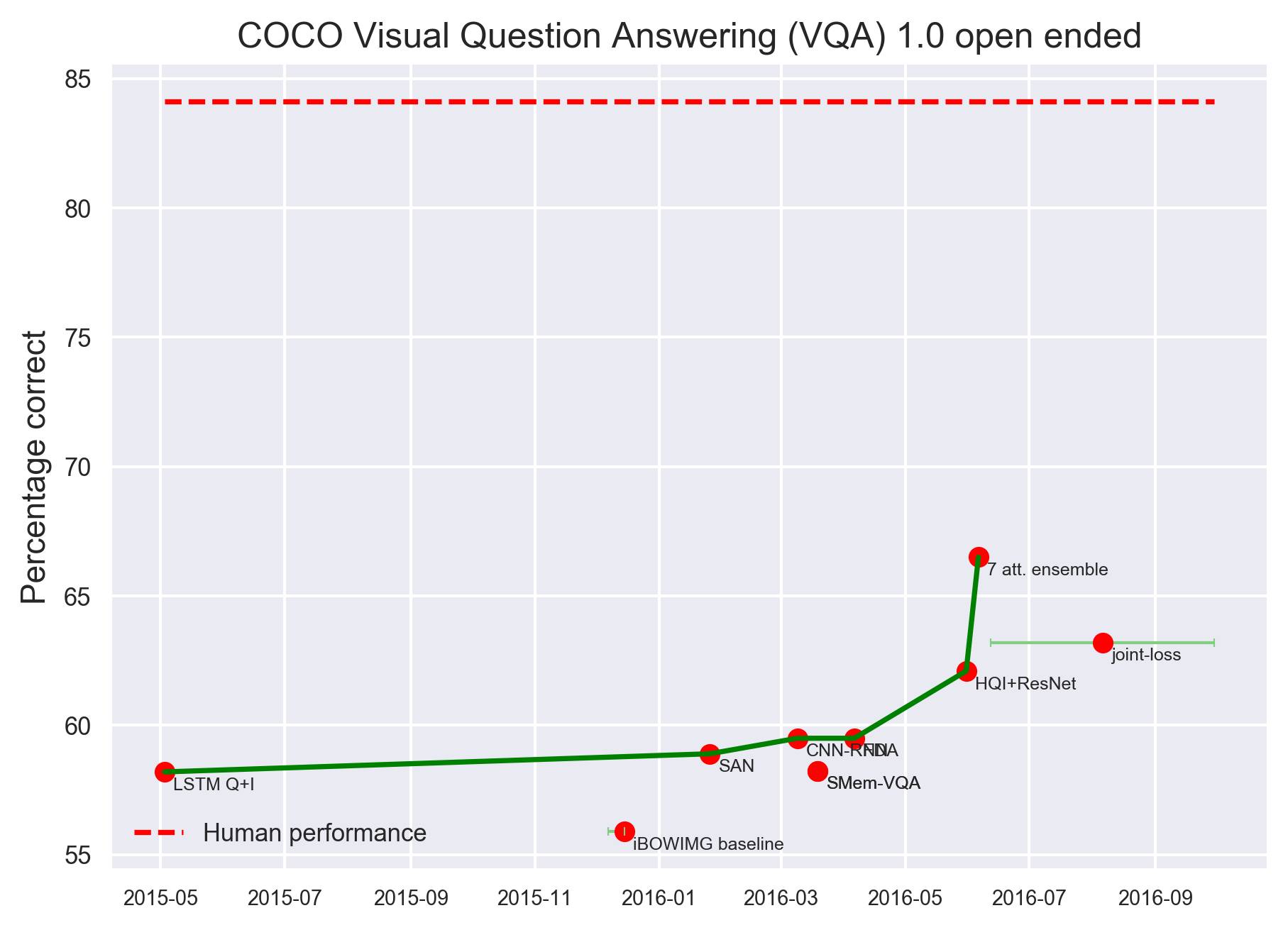
理解图像涉及的不仅仅是识别其中的物体或实体,也包括从图像中识别事件、关系和场景。理解图像不仅需要进行图像识别,还要掌握语言、世界建模和“图像理解”(image comprehension)。目前在这方面有几个数据集。下图来自 VQA,其中图像来自 Microsoft COCO 图像集,问题和问答都是由 Amazon Mechanical Turk 工作人员提出的。

VQA 数据集示例
那么,在视觉领域,计算机都在什么时间、以什么方式超越人类了呢?
最具代表性的是,在图像识别任务上,2016 年,微软亚洲研究院(MSRA)首先超越人类水平(红色虚线,下同)。
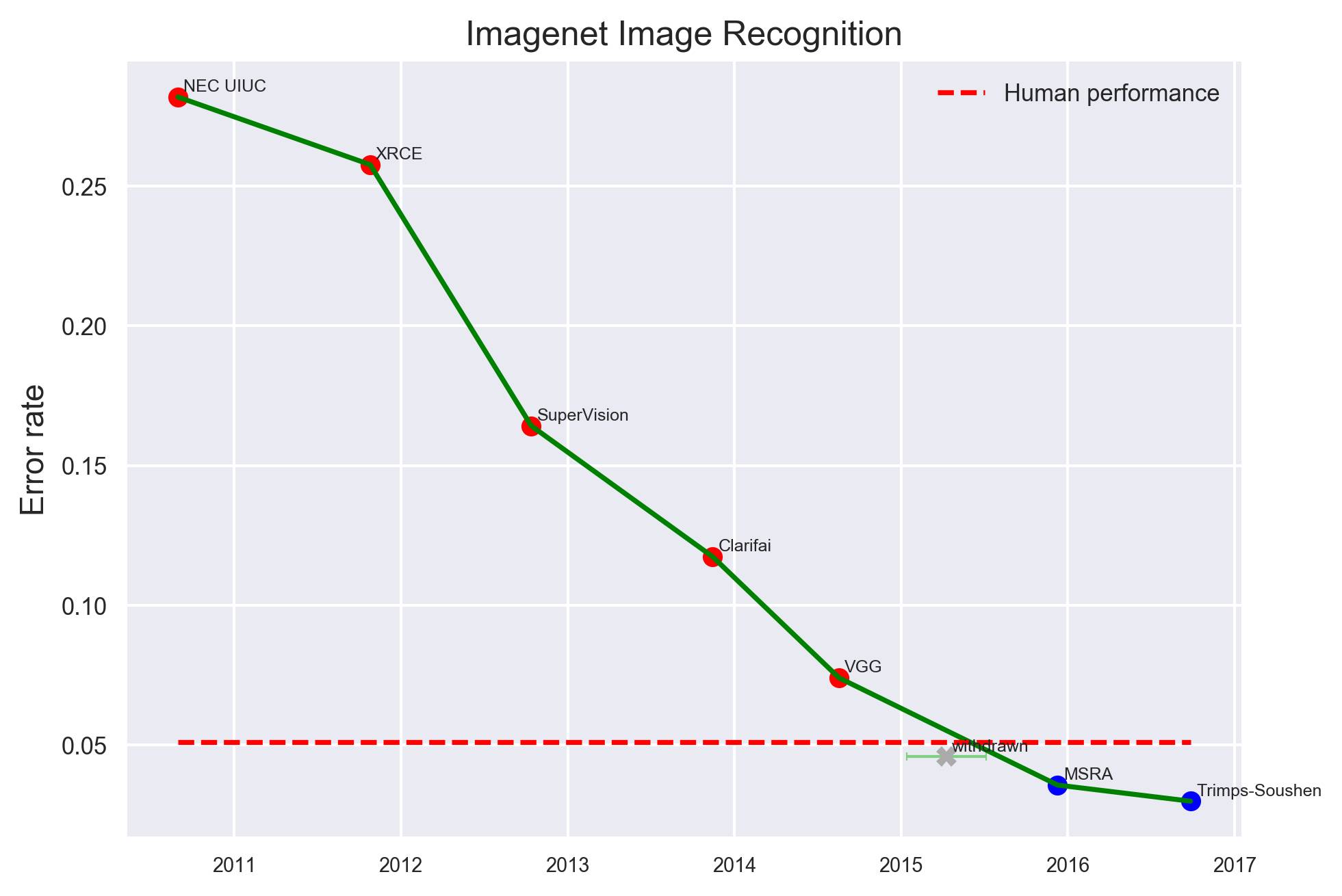
其他,在较小的数据集任务中,比如 CIFAR-10 数据集图像识别任务,2015 年 ICML 论文“Striving for Simplicity:The All Convolutional Net”率先突破人类水平。

更早一些,在街景房屋编号数据集(SVHN)上,2013 年纽约大学,包括 Yann LeCun 在内的学者提出“Regularization of Neural Networks using DropConnect”,率先超越了人类水平。

不过,在看图问答问题方面,计算机距离人类水平还有一定距离。下图是 COCO VAQ 1.0 开放问答任务,根据目前统计结果,计算机距离人类水平还有十几个百分点。
总体上,游戏是一个高效的开放式研究框架, 所有的智能都能在游戏中捕捉到。但是,抽象的游戏,比如象棋、围棋和跳棋等,可以在不需要人类世界或者物理世界知识的前提下玩。
虽然,这一领域大部分的游戏已经被计算机攻克,达到了超越人类的水平,但是现在仍然有一些游戏需要解决,特别是,考虑到不同的起点,一些游戏需要智能体从任意的抽象游戏中有效地学习规则(例如,对规则的文本描述或者是正确玩法的例子)。
1. 抽象的策略游戏
复杂的抽象策略游戏中,机器系统已经达到了超越人类的水平。其中一些是规则启发的和启发式的(heuristics),在一些例子中,则结合了机器学习的技术。
抽象策略游戏的代表之一是国际象棋,我们都记得 1997 年 5 月 11 日,IBM 的 Deep Blue 对战国际象棋大师卡斯帕洛夫并取得胜利。不过,Deep Blue 在这份统计中,并不算作计算机玩国际象棋超越人类(见图中 Deep Blue 红色拐点)。
根据这份统计,2006 年 5 月 27 日,英国计算机国际象棋程序 Rybka 1.164 bit 取胜才算开了先河。这之后,计算机国际象棋程序表现越来越好,公认超越人类水平。

2. 实时视频游戏
计算机视频游戏是一个非常开放的领域,很可能,现在或者未来的一些游戏过于复杂,进而成为“AI专属”的。同时,在一些进阶的游戏中,随着复杂度的不断增加,我们可能会看到很多有趣的进步。
-
Atari 2600 Alien:人类的平均水平在6800分左右。2015年3月,DQN模型的得分是在3000分左右。2015年11月底,DDQN得分逼近4000,Duel得分超过4500,但是距离人类水平都还有一定的差距。
-
Atari Amidar:人类的平均水平在1700分左右,2015年3月,DQN的得分只有700左右,2015年11月底,DDQN和Duel都超越了人类水平,得分分别为1700和2300左右。
-
Atari2600 Assault:人类的平均水平是1500分。DQN、DDQN和Duel都已经全面超越人类。
-
Atari 2600 Asterix:人类的平均水平是8000分。2015年3月,DQN的得分是6000分,2015年11月底,DDQN得分达到17000分,Duel得分近30000。
-
Atari 2600 Gravitar:人类的平均水平在2800分左右,DQN、DDQN和Duel的得分都在600以下。
注: DeepMind 首先在2015年初发布了 Nature文章,提出DQN。在2015年一年内提出了Double DQN,Dueling Network。后两者极大提升了DQN的性能,目前的改进型DQN算法在Atari游戏的平均得分是Nature版DQN的三倍之多。
语音识别
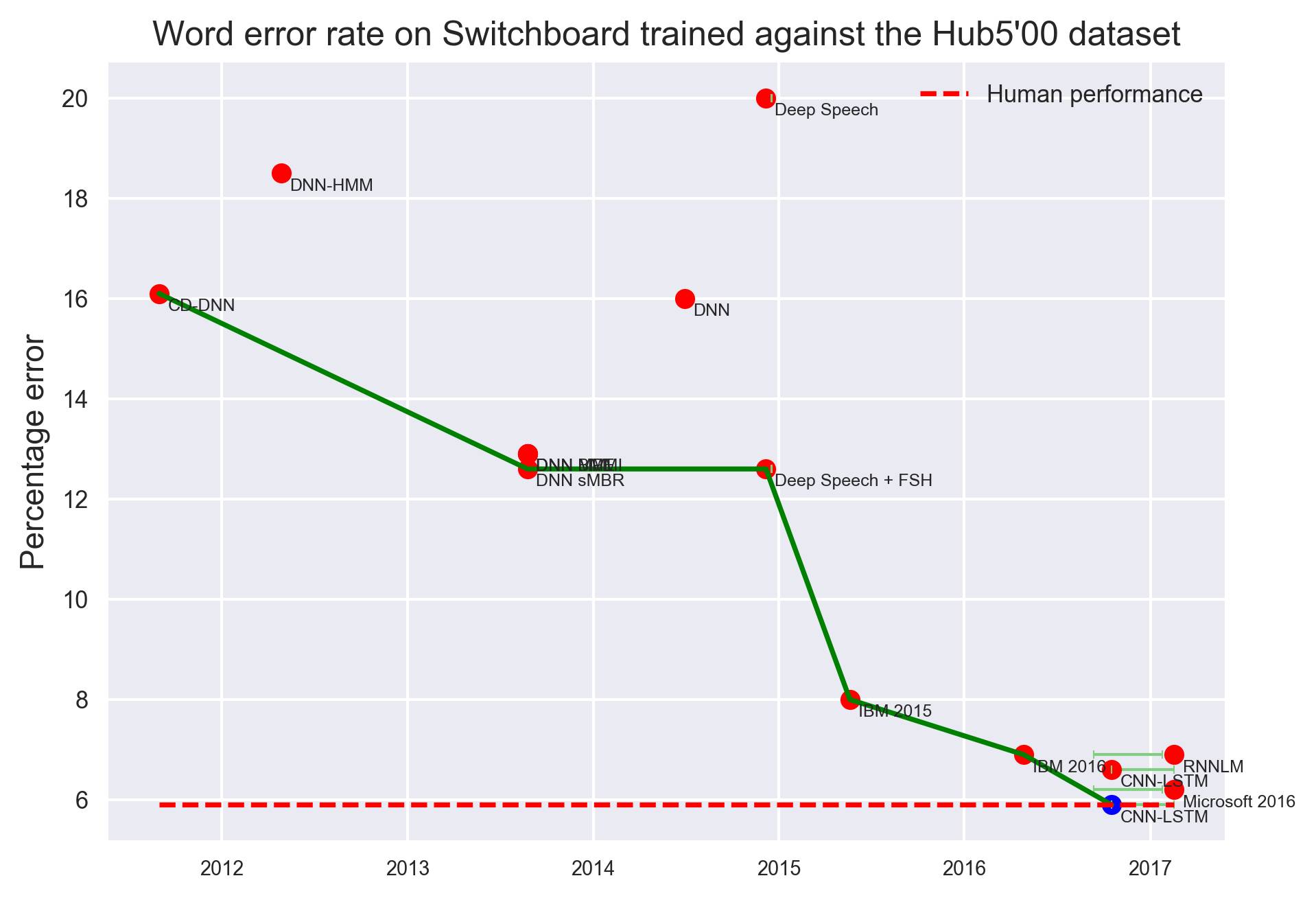
Switchboard上语音识别词错误率变化,衡量标准:Hub500
人类语音识别的词错率约为5.9%,放大上图可见,最右边的CNN-LSTM,Microsoft 2016等几个模型达到或接近人类水平。
图像生成
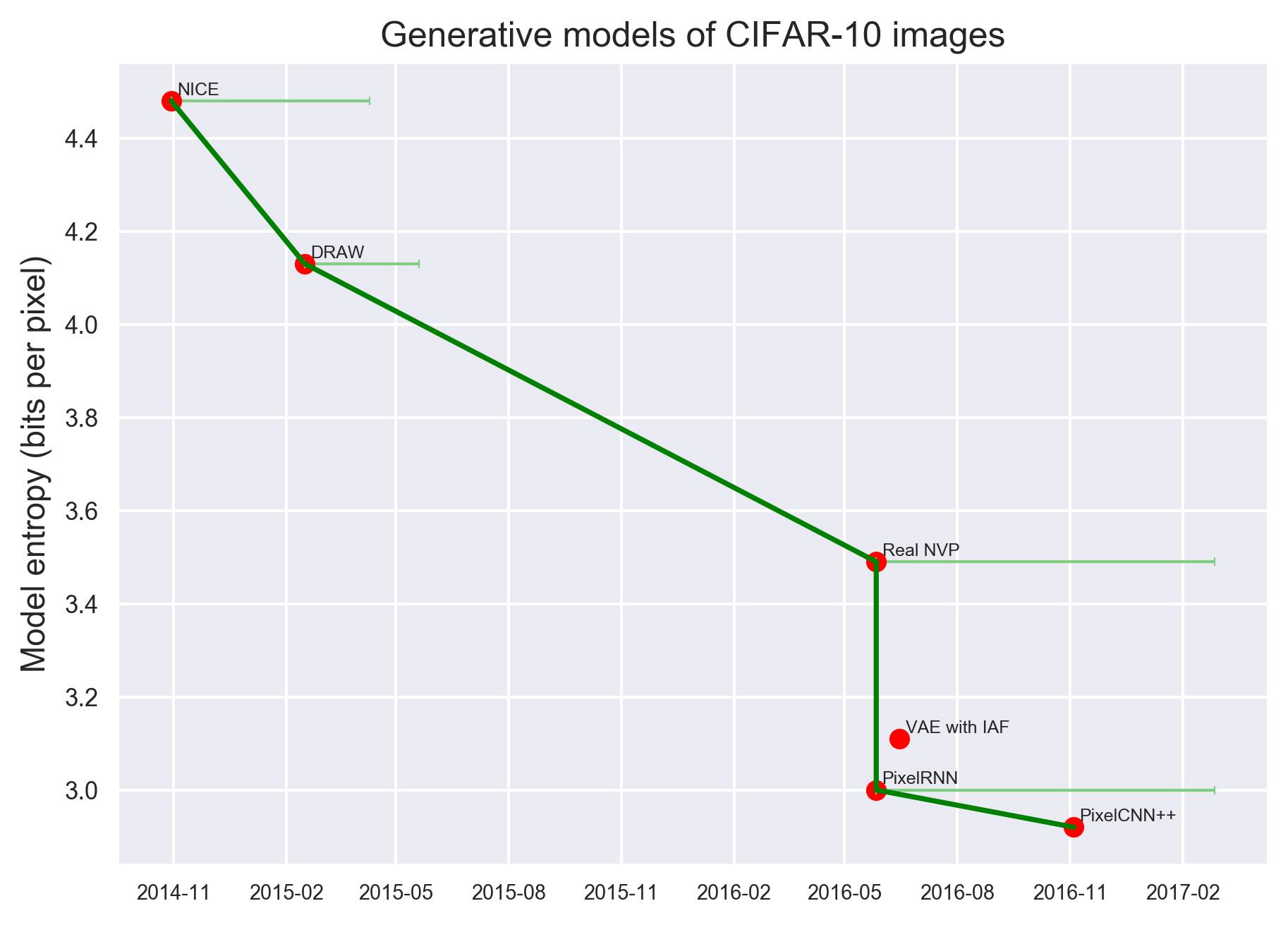
基于CIFAR-10数据集的图像生成模型,纵坐标表示图像熵(bits per pixel)。
2016年之后出现的PixelRNN和PixelCNN++生成模型实现了非常好的性能。
文本压缩(text compression)是衡量机器学习系统对人类语言建模的能力的一种方式。Shannon 1951年的经典论文(Prediction and Entropy ofPrinted English)提出英语字母的信息量在0.6~1.3比特之间:人类比传统的算法能更好地预测在一段文字中可能出现的下一个字符。更近一些的研究(Moradi 1998)提出与文本相关的信息量是每个字符1.3比特左右(不同的文本可能更高)。
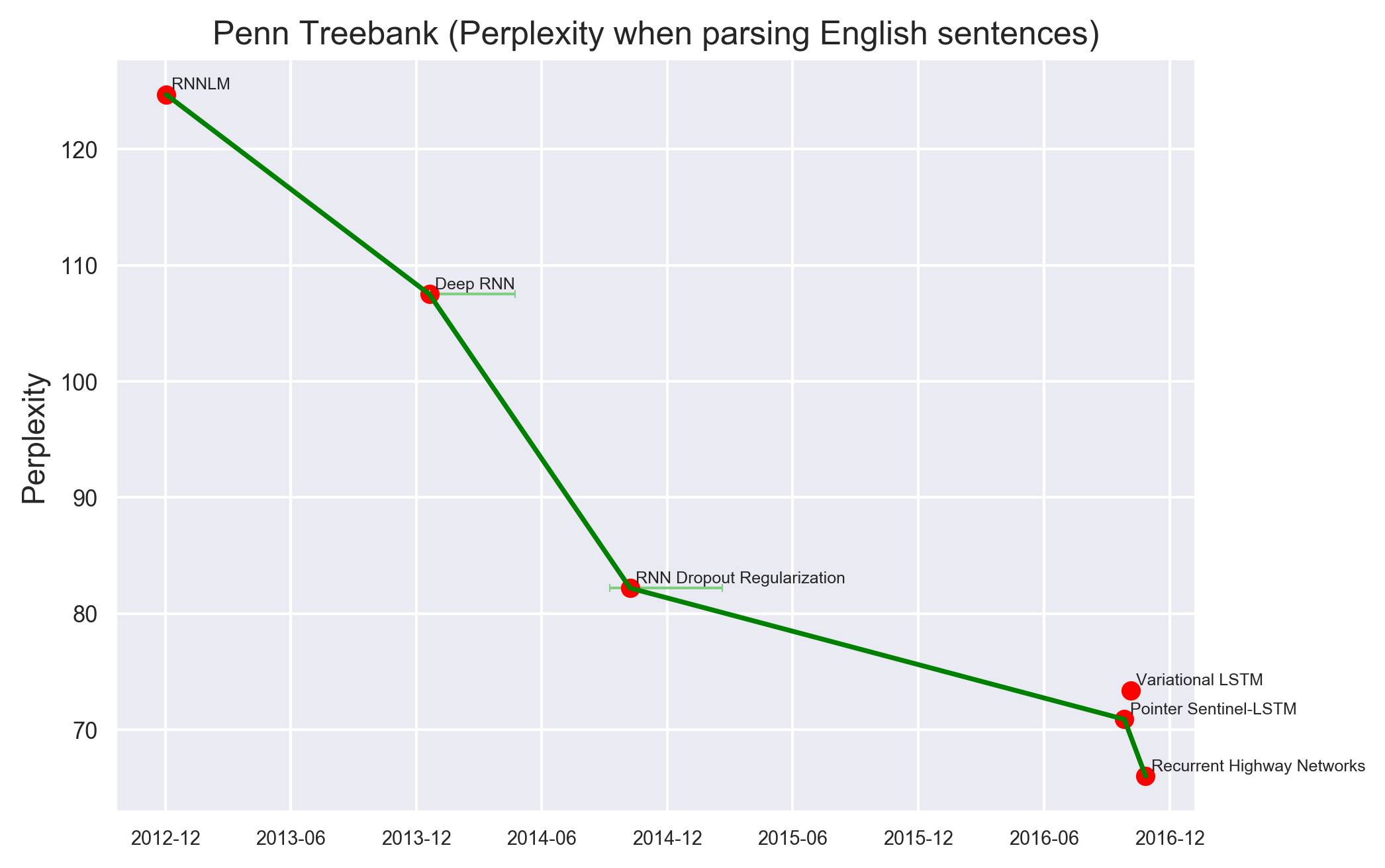
Penn Treebank (英语句子语法解析时的困惑度),纵坐标表示困惑度(perplexity)

Hutter Prize(编码英语文本时每个字符的信息量)
纵坐标表示信息熵,人类的表现是1.3比特左右。2016年之后的一些模型(Surprisal-Driven Zoneout,Recurrent Highway Networks等)达到了接近人类水平的表现。
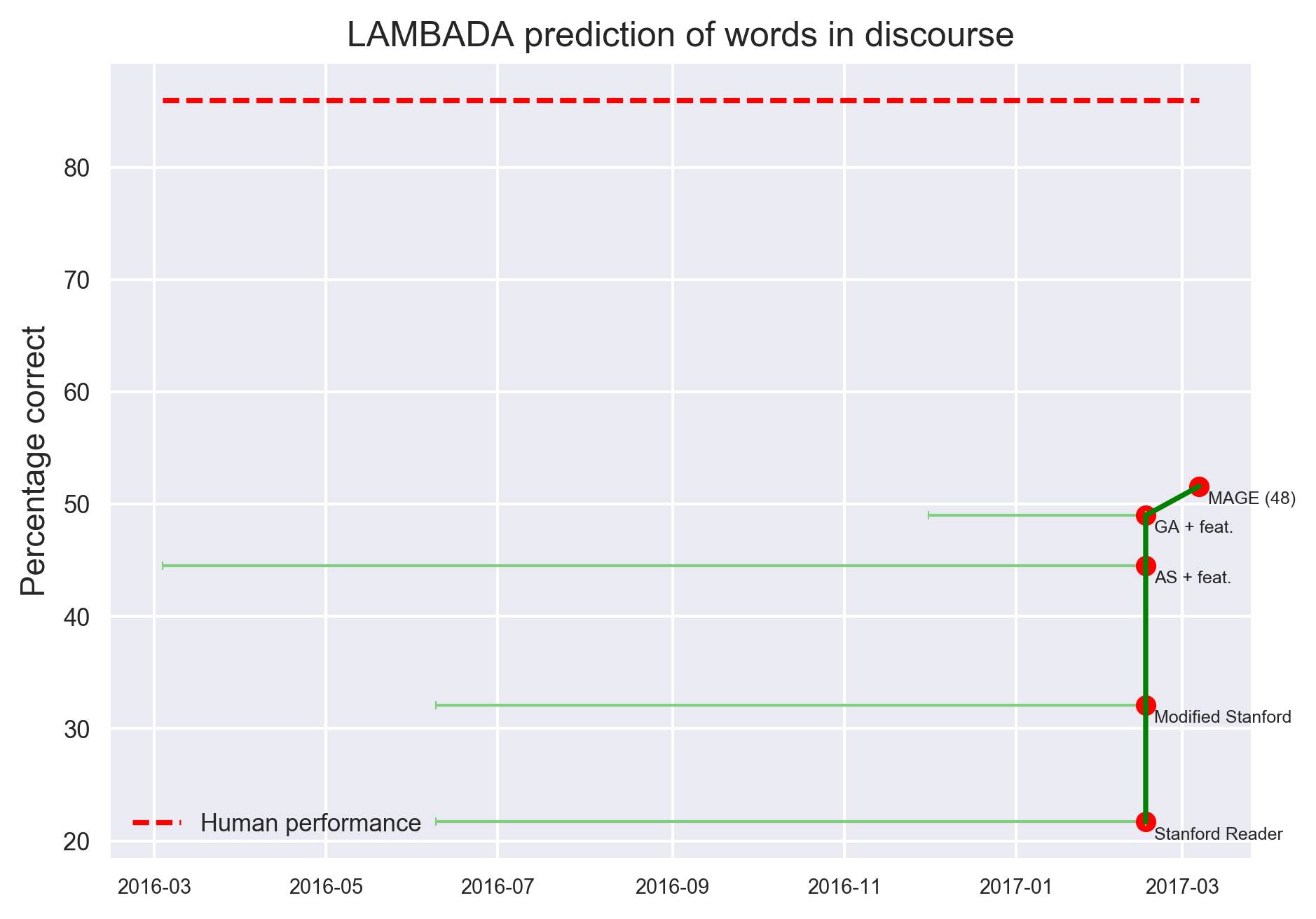
语篇中的LAMBADA 词汇预测
纵坐标表示预测准确率,人类表现超过80%。最新的一些模型,只有MAGE (48)的准确率达到51.6%,其余均低于50%。
翻译
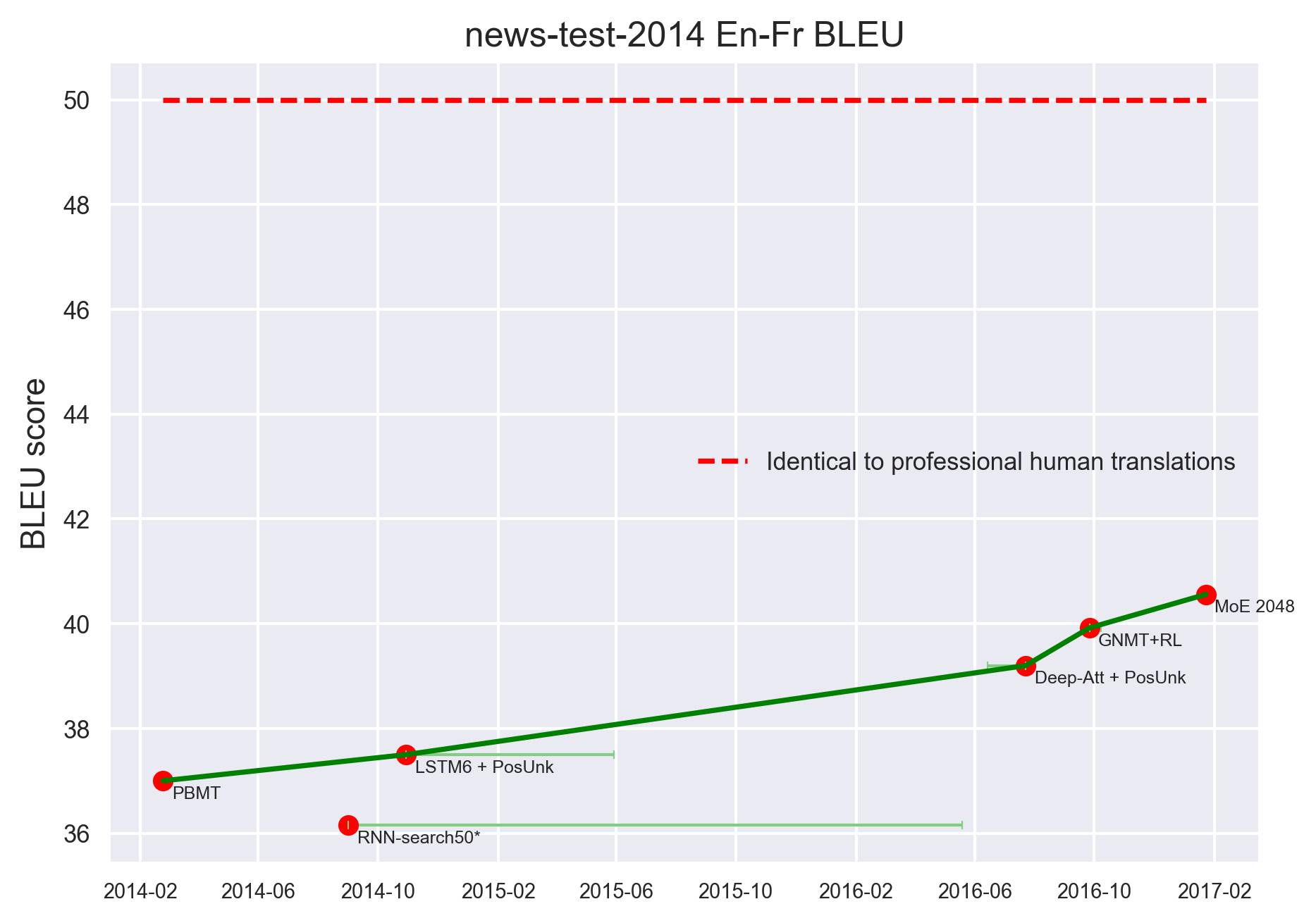
New-test-2014 En-Fr BLEU
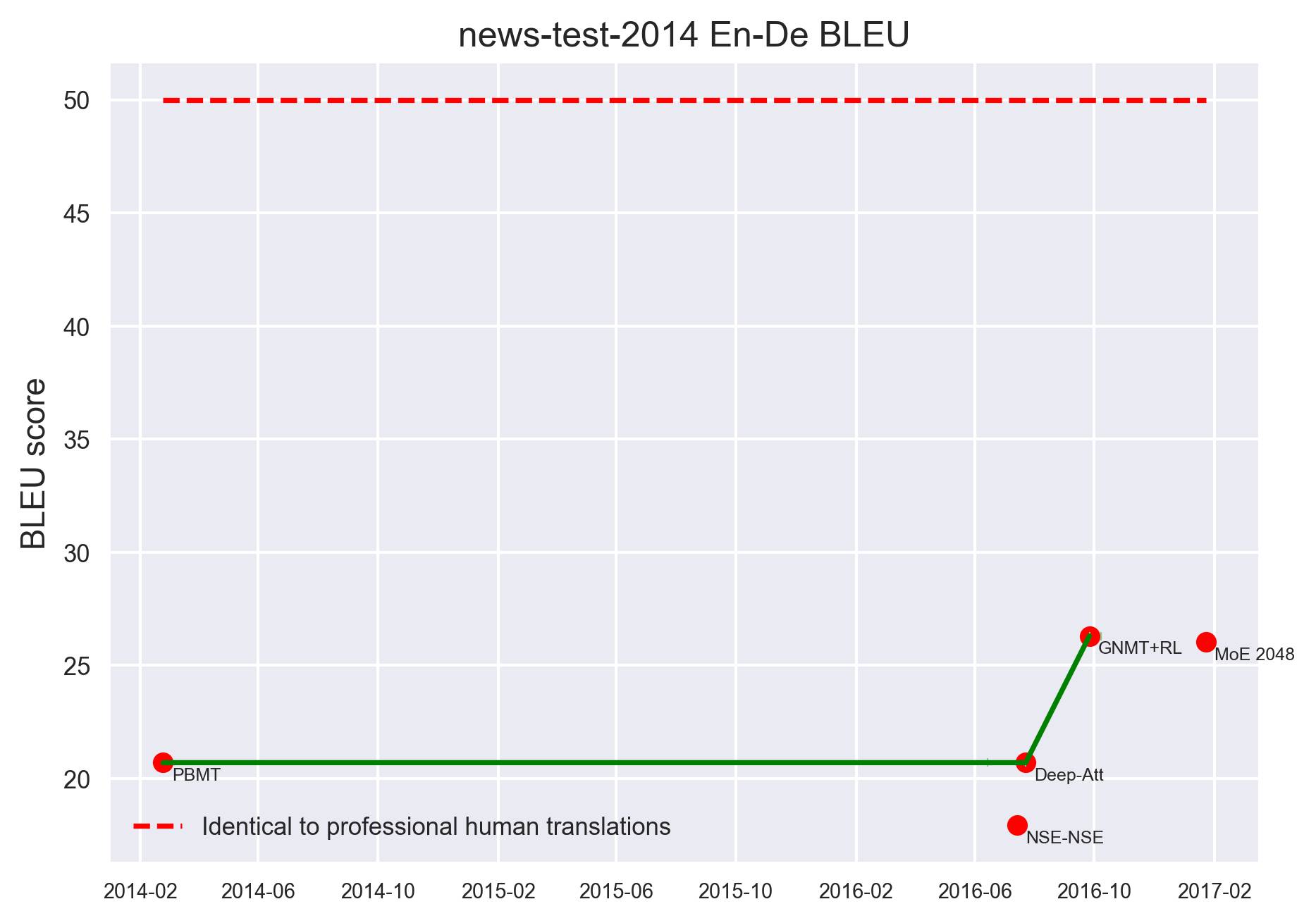
New-test-2014 En-De BLEU
上面两图是以BLEU得分为指标的翻译模型进展,红色虚线表示人类专业译员的水平。当前最好的一些模型(MoE 2048,GNMT+RL)的BLEU得分基本上远低于人类的表现。
对话:Chatbots 和对话智能体
对话是衡量AI进步的经典指标。图灵测试是让一个人类去判断与真实的人聊天和与计算机聊天的差异。图灵测试更简单的变体是,判断者处理的是更加随意、更少探查性的各种方式的对话。
Loebner奖(TheLoebner Prize)是一个年度的活动,运行的是图灵测试的一个版本。自2014年设立以来,这个活动向参赛者提供标准形式的测试,并对结果进行评分(每个问题都以可信/半合理/不合理进行评级)。这个指标不是固定的,因为每年测试的问题都会变,这个指标某种程度上可以代表AI对话领域的进步。下面是2016年的示例:









