大数据文摘作品,转载要求见文末
作者 | Adit Deshpande
编译 | 酒酒,朱璇,万如苑
徐凌霄,钱天培
自从2012年CNN首次登陆ImageNet挑战赛并一举夺取桂冠后,由CNN发展开来的深度学习一支在近5年间得到了飞速的发展。
今天,我们将带领大家一起阅读9篇为计算机视觉和卷积神经网络领域里带来重大发展的开山之作,为大家摘录每篇论文的主要思路、重点内容和贡献所在。
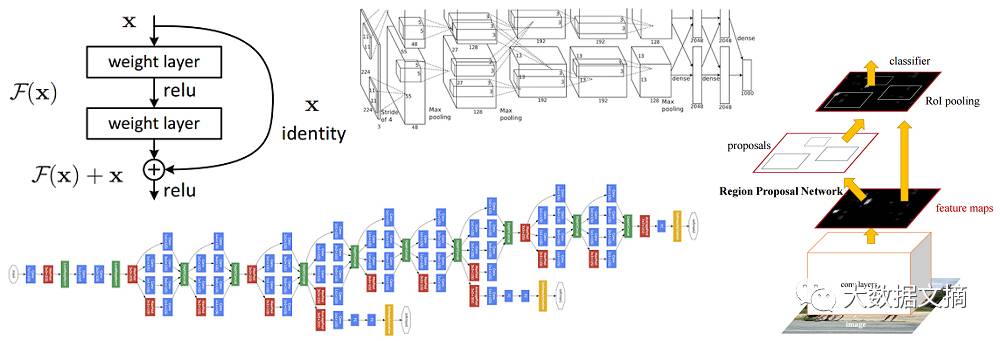
这篇论文可谓是CNN的开山鼻祖(当然,有些人也会说Yann LeCun 1998年发表的Gradient-Based Learning Applied to Document Recognition才是真正的开山之作)。该论文题为“ImageNet Classification with Deep Convolutional Networks”,目前已经被引用6184次,是该领域公认影响最为深远的论文之一。
在这篇论文中,Alex Krizhevsky, Ilya Sutskever, 和Geoffrey Hinton 共同创造了一个“大规模深度神经网络”,并用它赢得了2012 ImageNet挑战赛 (ImageNet Large-Scale Visual Recognition Challenge)的冠军。(注:ImageNet可被视作计算机视觉领域的奥林匹克大赛,每年,来自全世界的各个团队在这项竞赛中激烈竞争,不断发现用于分类、定位、探测等任务的最优计算机视觉模型。)
2012年,CNN首次登场便以15.4%的错误率拔得头筹,远远优于第二名的26.2%。CNN对计算机视觉领域的贡献可见一斑。自这场比赛后,CNN就变得家喻户晓了。
这篇论文里讨论了AlexNet神经网络的具体结构。相比现在流行的神经网络构架,它的结构其实非常简单:5个卷积层、最大池化层(max pooling layer),dropout层,和3个全连接层(fully connected layers)。但这个结构已经可以被用来分类1000种图片了。
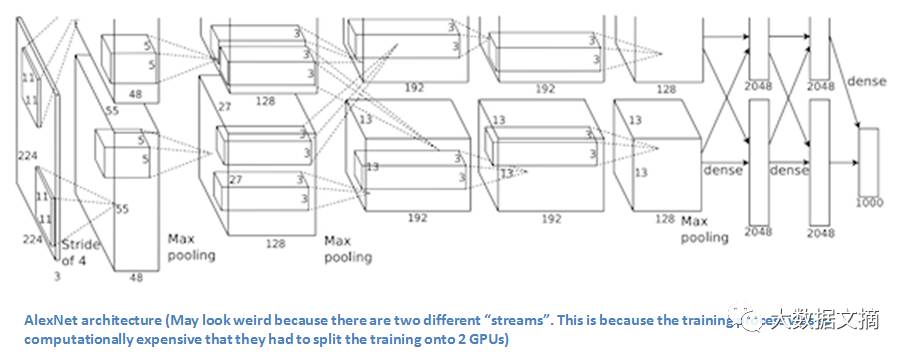
AlexNet的结构(可能你会注意到,图上出现了两个分支,这是因为训练计算量太大了,以至于他们不得不把训练过程分到两个GPU上)
训练集ImageNet data有超过1500万张标记图片,共22000个分类。
解非线性方程用的是ReLu算法(因为发现ReLu的训练时间相比卷积tanh函数要快上数倍)。
使用了包括图像平移(image translations),水平翻转(horizontal reflections),和图像块提取(patch extractions)等数据增强技术。
使用了dropout层来避免对训练数据的过度拟合。
使用了特定的动量(momentum)和权重衰减(weight decay)参数的批量随机梯度下降(batch stochastic gradient descent)算法来训练模型。
在两块GTX580GPU上训练了5到6天。
这个由Krizhevsky,Sutskever和Hinton在2012年共同提出的神经网络开始了CNN在计算机视觉领域的盛宴,因为这是有史以来第一个在ImageNet数据集上表现如此优异的模型。里面用到的一些技术,如数据增强和丢弃(data augmentation and dropout),至今仍然在被广泛使用。这篇论文详述了CNN的优势,而它在比赛上的惊艳表现也让它名留青史。
AlexNet在2012年大放异彩之后,2013年的ImageNet大赛上出现了大量的CNN模型,而桂冠则由纽约大学的Matthew Zeiler和Rob Fergus摘得,折桂模型就是ZF Net。这一模型达到了11.2%的错误率。它好比是之前AlexNet的更精确调试版本,但它提出了如何提高准确率的关键点。此外,它花了大量篇幅解释了ConvNets背后的原理,并且正确地可视化了神经网络的过滤器(filter)和权重(weights)。
作者Zeiler 和 Fergus在这篇题为“Visualizing and Understanding Convolutional Neural Networks”的论文开篇就点出了CNN能够再次兴起的原因:规模越来越大的图片训练集,和GPU带来的越来越高的计算能力。同时他们也点出,很多研究者其实对于这些CNN模型的内在原理认知并不深刻,使得“模型优化过程只不过是不断试错”,而这一现象在3年后的今天依旧广泛存在于研究者当中,尽管我们对CNN有了更加深入的理解!论文的主要贡献在于细述了对AlexNet的优化细节,及以用一种巧妙的方式可视化了特征图。
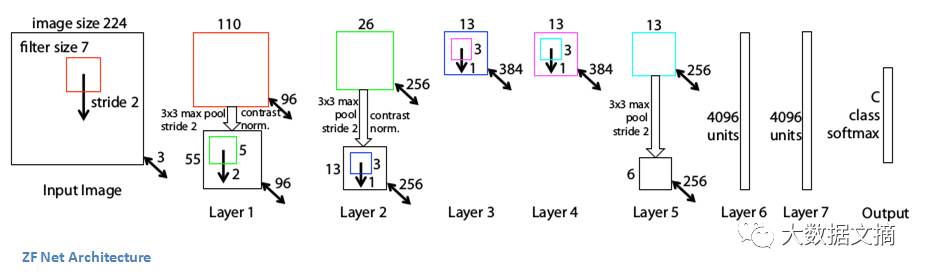
ZF Net 结构
除了一些细小的修改,ZF Net模型与AlexNet构架很相似。
AlexNet使用了1500万张图片做训练,ZF Net只用了130万张。
AlexNet在第一层用了11x11的过滤器,而ZF Net用了减小了步长(stride)的7x7过滤器,原因是第一层卷积层用小一点的过滤器可以保留更多原始数据的像素信息。用11x11的过滤器会跳过很多有用信息,尤其在第一个卷积层。
过滤器的数目随着神经网络的增长而增多。
激活函数用了ReLu,误差函数用了交叉熵损失(cross-entropy loss),训练使用批量随机梯度下降方法。
在一块GTX580 GPU上训练了12天。
开发了一种被称为Deconvolutional Network(解卷积网络)的可视化技术,能够检测不同特征激活与对应输入空间(input space)间的关系。之所以称之为“解卷积网”(deconvnet),是因为它能把特征映射回对应的像素点上(正好和卷积层做的事相反)。
这个网络结构背后的思路就是,在训练CNN的每一层都加上一个“deconvnet”,从而可以回溯到对应的像素点。一般的前向传播过程是给CNN输入一个图片,然后每一层计算出一个激活函数值。假设现在我们想检测第四层某一特征的激活,我们就把除了此特征之外的其他特征激活值设为0,再把此时的特征映射矩阵输入给deconvnet。Deconvnet与原始的CNN有相同的过滤器结构,再针对前三层网络进行一系列反池化过程(unpool,maxpooling的逆过程)、激活(rectify)和过滤操作,直到回到最初的输入空间。
这样做是为了找出图像中刺激生成某一特征的结构所在。我们来看看对第一层和第二层的可视化结果:

前两层的可视化结果:每一层演示了两个结果,第一个是过滤器的可视化,另外一个是图片中被过滤器激活最明显的部分。例如图上Layer2部分展示了16个过滤器
我们在CNN入门手册(上)里说过,ConvNet的第一层永远做的是一些最基础的特征检测,像是简单的边缘和这里的颜色特征。我们能看到,到了第二层,更多的环形结构特征就显示出来了。再看看第三、四、五层:

3,4,5层的可视化结果
这些层已经能显示出更高级特征,像是小狗和花朵。别忘了在第一层卷积之后,我们一般会有一个池化层减少图片的采样(例如从32x32x3减少到16x16x3)。这样做能让第二层对原始图片有一个更广阔的视角。如欲获取更多关于deconvnet和这篇论文的信息,可以看看Zeiler他本人这篇演讲(https://www.youtube.com/watch?v=ghEmQSxT6tw)。
ZF Net的意义不仅在于夺得了2013年比赛的第一名,更重要的是它直观展示了CNN如何工作,并且提出了更多提高CNN表现的方法。这些可视化技术不仅描述了CNN内部的工作原理,同时对神经网络结构的优化提供了深刻的见解。精妙的deconv可视化展示和里面提到的闭塞实验(occlusion experiments)都让其成为我最喜欢的论文之一。
简单、深度,就是这个2014年模型的理念。它由牛津大学的Karen Simonyan 和Andrew Zisserman提出,在ImageNet大赛中达到了7.3%的错误率(不过不是当年的第一)。它是一个19层的CNN模型,每一层都由步长和填充(pad)为1的3x3 过滤器,和步长为2的2x2 maxpooling层组成,是不是很简单呢?
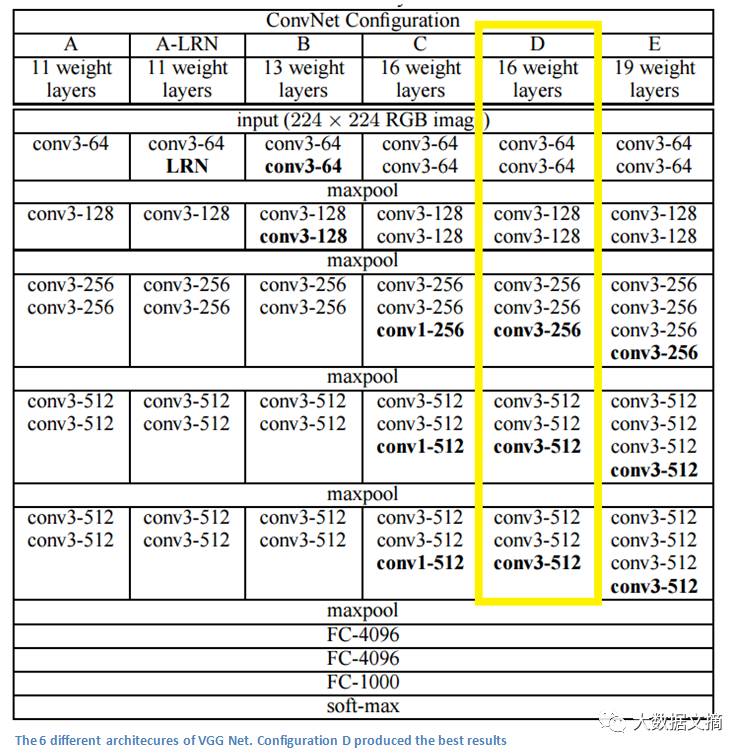
与AlexNet的11x11过滤器和ZF Net7x7的过滤器非常不同,作者解释了为什么选择用只有3x3的结构:两个3x3的卷积与一个5x5的卷积效果相同,这样我们可以用很小的过滤器模拟出较大的过滤器的效果。一个直接的好处就是减少了参数数量,同时用两个卷积层就能用到两次ReLu
3个卷积层与一个7x7的过滤器感受效果相同
输入空间随着层数增多而减少(因为卷积和池化),但随着卷积和过滤器的增多,卷积深度不断加深
值得注意的是每次maxpool之后过滤器的数量都翻倍了。这也再次实践了减少空间维度但加深网络深度的理念
在图像分类和定位上都表现很好,作者将定位用在了回归中(论文第10页)
使用Caffe建立模型
利用抖动(scale jittering)作为训练时数据增强的手段
每个卷积层后都有一个ReLu,用批量梯度下降来训练
在4个英伟达Titan Black GPU上训练了2到3周
我认为VGG Net算得上最具影响力的论作之一,因为它强调了卷积神经网络需要用到深度网络结构才能把图像数据的层次表达出来。
还记得我们刚刚谈到的网络架构简单化的想法吗?谷歌就把这个想法引入了他们的Inception模块。 GoogLeNet是一个22层CNN,它凭着6.7%的错误率杀入五强并成为2014年ImageNet大赛的优胜者。 据我所知,这是第一个真正不同于原有的简单叠加顺序卷基层和池化层的构建方法的CNN架构之一。 这篇文章的作者还强调这个新模式在内存和功耗方面进行了重要的改进。(这是一个重要注意事项:堆叠层次并添加大量的过滤器都将产生巨大的计算和内存开销,也更容易出现过度拟合。)
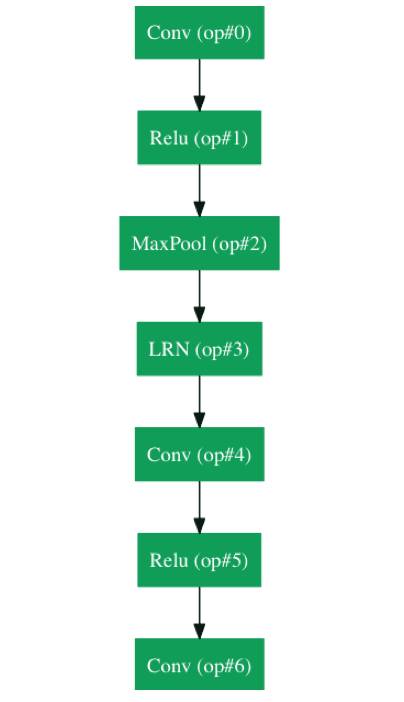
GoogLeNet架构示意图之一
(原图为动图,请戳原文链接浏览)
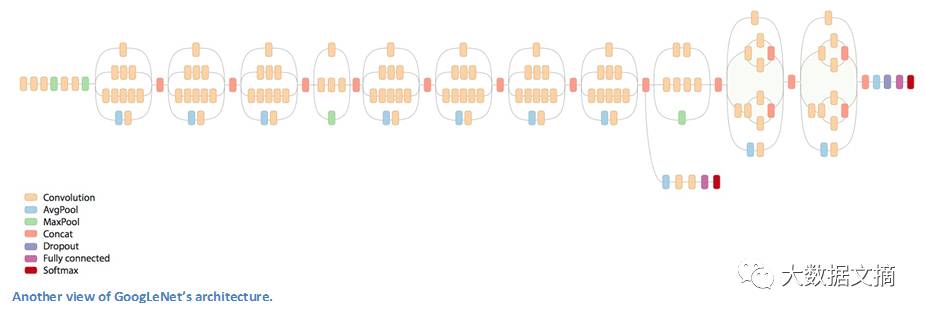
GoogLeNet架构示意图之二
让我们来看一下GoogLeNet的结构。我们首先要注意到一点:并不是所有的过程都按顺序发生。如上图所示,GoogLeNet里有并行进行的网络结构。
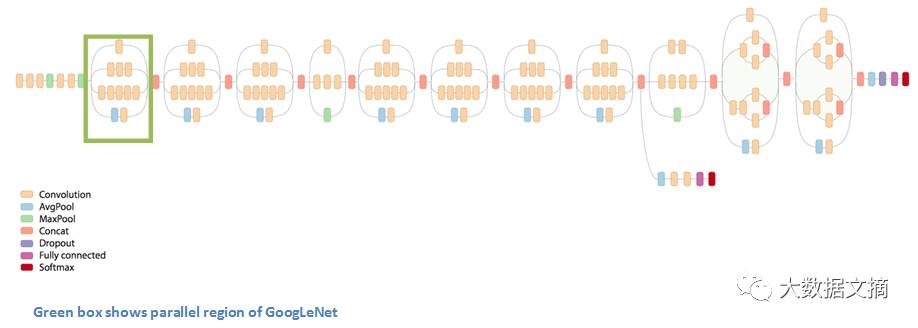
绿框内显示GoogLeNet的并行区
上图绿框里的结构叫做Inception模块。下面让我们来仔细看一下它的构成。
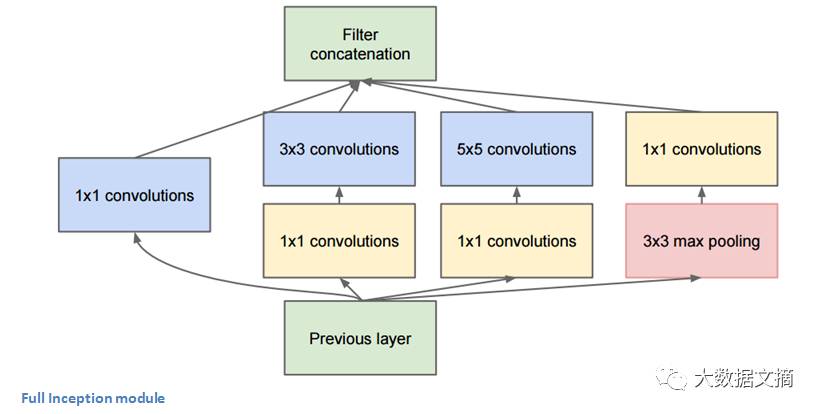
展开的Inception模块
上图中,底部的绿色框是我们的输入,而顶部的绿色框是模型的输出。(将这张图片右转90度, 与前一张GoogLeNet全景图联系起来一起看,可以看出完整网络的模型。 )基本上,在传统ConvNet的每一层里,你都必须选择是否进行池化操作或卷积操作,以及过滤器的尺寸。 一个Inception模块允许你并行执行所有这些操作。 事实上这正是作者最初提出的一个“天真”的想法。
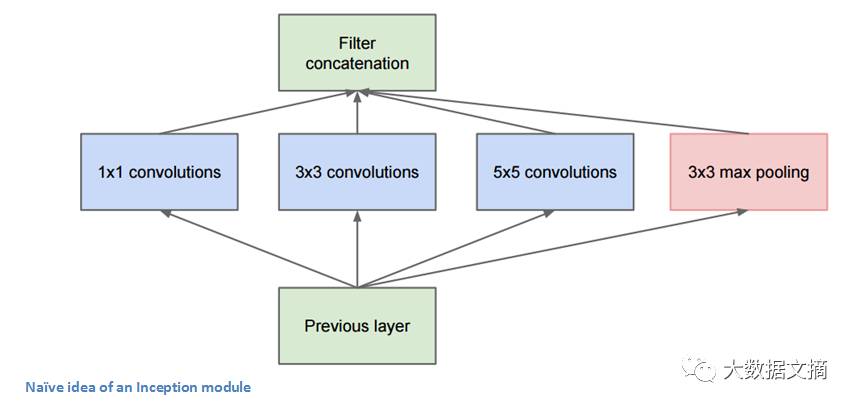
那么,为什么这样的设计并不可行?因为这将导致太多太多的输出,使得我们最终因大输出量而停留在一个非常深的信道(channel)。 为了解决这个问题,作者在3x3和5x5层之前添加1x1卷积操作。 1x1卷积,又叫作网络层中的网络,提供了一种降低维数的方法。 例如,假设您的输入量为100x100x60(不一定是图像的尺寸,只是网络中任意一层的输入尺寸), 应用1x1卷积的20个过滤器可以将输入降低到100x100x20,从而3x3和5x5卷积的处理量不会太大。 这可以被认为是一种“特征池化”(pooling of features),因为我们减小了输入量的深度,这类似于我们通过标准的max-pooling层降低高度和宽度的维度。 另一个值得注意的点是,这些1x1卷积层之后的ReLU单元 的功能, 不会因降维而受到的损害。(参见Aaditya Prakash的博客http://iamaaditya.github.io/2016/03/one-by-one-convolution/以了解更多1x1卷积的效果等信息。) 你可以在这个视频中看到最终过滤器级联的可视化https://www.youtube.com/watch?v=_XF7N6rp9Jw。 )
你可能有这样的疑问“这个架构为什么好用”?这个架构提供了一个模块,它包括一个网络层的网络、一个中等大小的卷积过滤器 、一个大型的卷积过滤器和一个池化操作。 网络层的网络的卷积能够提取关于输入的非常细节的信息,而5x5滤镜能够覆盖输入的较大接收场,因此也能够提取其信息。
你还可以用一个池化操作来减少占用空间大小,并防止过度拟合。 此外,每个卷积层之后都进行ReLUs,这有助于提高网络的非线性。大体来讲,这样的网络能够做到执行各类操作的同时仍保持计算性。 这篇论文还提出了一个高层次的推理,涉及稀疏性(sparsity)和密集连接(dense connections)等主题。(参见论文http://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Szegedy_Going_Deeper_With_2015_CVPR_paper.pdf的第3段和第4段。我并不很理解这方面的内容,但很乐意听到你们在评论中发表自己的见解。)
在整个架构中使用了9个inception模块,共有100多层。现在看来很有深度…
不使用完全连接的层 !他们使用平均池化代替,将7x7x1024的输入量转换为1x1x1024的输入量。 这节省了大量的参数。
使用比AlexNet少12倍的参数。
在测试期间,创建了同一图像的多个版本,输入到神经网络中,并且用softmax概率的平均值给出最终解决方案。
在检测模型中使用了R-CNN的概念(随后的一篇论文中将讨论) 。
Inception模块现在有多个更新版本(版本6和7)。
在一周内使用“几个高端GPU”训练模型。
GoogLeNet是率先引入“CNN层并不需要按顺序堆叠”这一概念的模型之一。随着 Inception模块的提出, 作者认为有创意的层次结构可以提高性能和计算效率。 这篇文章为接下来几年出现的一些惊人架构奠定了基础。

借用李奥纳多的一句台词“我们需要更深入。”
https://arxiv.org/pdf/1512.03385v1.pdf
让我们来想像一个深度CNN架构,对其层数加倍,然后再增加几层。但是这个CNN结构可能还是比不上微软亚洲研究院2015年底提出的ResNet体系结构那么深。ResNet是一个新的152层网络架构,它以一个令人难以置信的架构在分类、检测和定位等方面创造了新的记录。 除了层次上的新纪录之外,ResNet还以令人难以置信的3.6%的错误率赢得了2015年ImageNet大赛的桂冠。其他参赛者的错误率一般徘徊在5-10%左右。(参见Andrej Karpathy的博客http://karpathy.github.io/2014/09/02/what-i-learned-from-competing-against-a-convnet-on-imagenet/,这篇文章说明了其在ImageNet挑战赛与竞争对手ConvNets竞争的经历。)
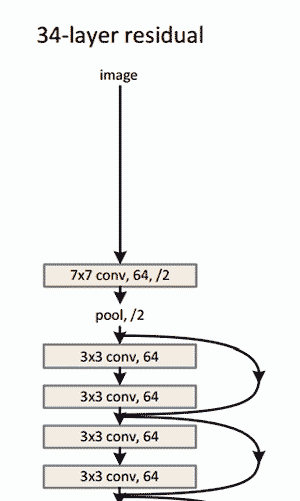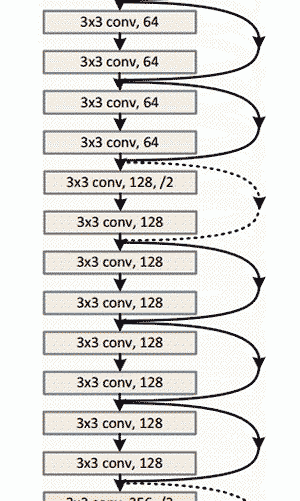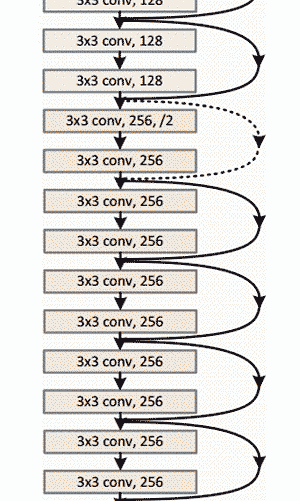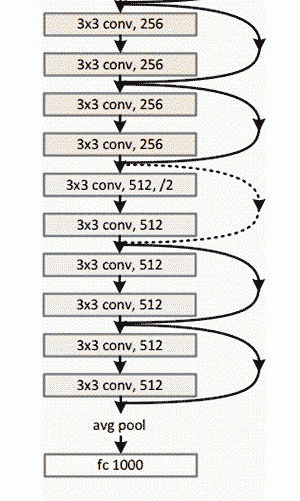
上图ResNet架构示意图
Residual Block背后的想法是把输入x通过conv-relu-conv序列输出。 这将先输出一些F(x),再把这些结果添加到原始输入x 即H(x)= F(x) + x。 而在传统的CNN中,H(x)直接等于F(x)。 所以,在ResNet中,我们不仅计算这个简单转换(从x到F(x)),还将F(x)加到输入x中。 在下图所示的迷你模块计算中,原输入x被做轻微变化,从而得到一个轻微改变的输出 。(当我们考虑传统CNN时,从x到F(x)是一个全新的表达,不保留关于原始x的任何信息。 作者认为“优化残差映射比优化原始映射更容易。”)
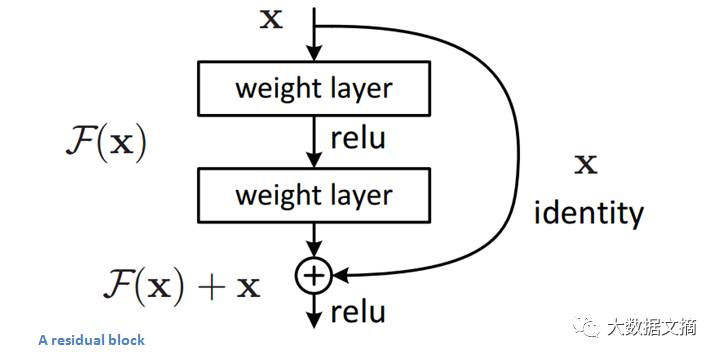
残差块的结构
Residual Block之所以有效的另一个原因是,在反向传播过程中,由于我们对加法运算分布了梯度,梯度能够很容易地流过图。
“超级深” - Yann LeCun。
152层…
有趣的是,在仅仅前两层之后,空间大小从224x224的输入量压缩到56x56。
作者声称,在普通网络中简单增加层次,将导致较高的训练和测试误差(论文里的图1)
该小组尝试了一个1202层网络,但可能由于过拟合而导致测试精度较低。
在8个GPU机器上训练了两到三周 。
3.6%的错误率就足以说服你。 ResNet模型是我们目前拥有的最好的CNN架构,是残差学习思想的一大创新。 自2012年以来,ResNet模型的错误率逐年下降。我相信我们已经到了“堆叠很多层的神经网络也不能带来性能提升”的阶段了 。接下来肯定会有创新的新架构,就像过去2年一些新尝试的出现。
ResNets内的ResNets http://arxiv.org/pdf/1608.02908.pdf。
R-CNN – 2013:https://translate.googleusercontent.com/translate_c?act=url&depth=1&hl=en&ie=UTF8&prev=_t&rurl=translate.google.com&sl=en&sp=nmt4&tl=zh-CN&u=https://arxiv.org/pdf/1311.2524v5.pdf&usg=ALkJrhgwBa8jBFOgSDEuZFOmg5CeahQVSw
Fast R-CNN – 2015:https://translate.googleusercontent.com/translate_c?act=url&depth=1&hl=en&ie=UTF8&prev=_t&rurl=translate.google.com&sl=en&sp=nmt4&tl=zh-CN&u=https://arxiv.org/pdf/1504.08083.pdf&usg=ALkJrhiMQQ68G9lTdUV9DYnKPAUOb6PDaA
Faster R-CNN – 2015:https://translate.googleusercontent.com/translate_c?act=url&depth=1&hl=en&ie=UTF8&prev=_t&rurl=translate.google.com&sl=en&sp=nmt4&tl=zh-CN&u=http://arxiv.org/pdf/1506.01497v3.pdf&usg=ALkJrhjfeXGyTfxi4AmeFDqjODJ4qoHN8w
有些人可能会认为,这篇首次描述R-CNN的论文比之前所有创新网络架构论文都更有影响力。 随着第一个R-CNN论文被引用超过1600次,Ross Girshick和他在加州大学伯克利分校领导的研究组,实现了计算机视觉领域中最有影响力的进步之一。 他们的标题清楚地表明:Fast R-CNN和Faster R-CNN能使模型更快和更适配的用于当前的目标检测任务。
R-CNN的目的是解决目标检测问题。 对给定图像,我们希望能为图像里的全部物体绘制边界框。 这个过程可以分为两个步骤:区域提取和分类。
作者指出,任何类别不可知的区域提取方法都能用于R-CNN。 其中选择性搜索(https://ivi.fnwi.uva.nl/isis/publications/2013/UijlingsIJCV2013/UijlingsIJCV2013.pdf)特别适用于R-CNN。选择性搜索先执行生成 2000个概率最高的含有物体的不同区域的函数。随后这些被建议的区域都被“扭曲”(warp)成为一个个合适尺寸大小的图像, 输入到一个训练好的CNN(文章里用的是AlexNet)。这个CNN将为每个区域提取出一个特征向量,然后这些向量被输入到一组针对每类物体分别进行训练的线性SVM,从而输出分类结果。 同时这些向量也被输入给训练好的边界框回归器,以获得最准确的坐标。
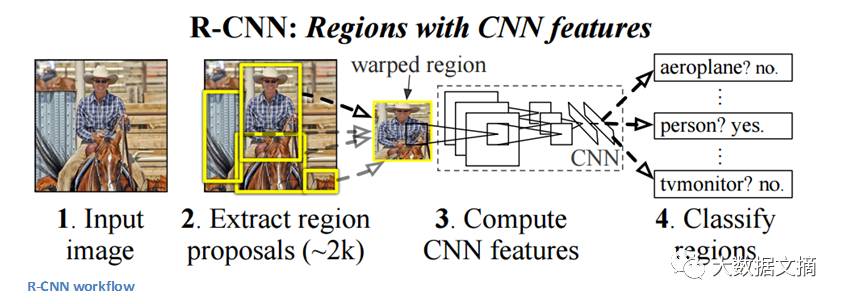
R-CNN流程图
接下来R-CNN使用非最大值抑制(Non-maxima suppression)来处理明显重叠的物体边界框。
针对三个主要问题,他们对原始模型进行了改进。 模型训练被分成几个阶段(ConvNets到SVM到边界框回归),计算量极其大, 而且非常慢(RCNN在每个图像上花费 53秒)。 Fast R-CNN基本上通过共享不同方案之间的转换层计算、交换生成区域提案的顺序、和运行CNN,从而解决了速度问题。
在该模型中,图像首先进入ConvNet, 从ConvNet的最后一个特征图中获取用于区域提取的特征(更多详细信息请参阅该论文的2.1部分),最后还有完全连接层、回归、和分类开始。
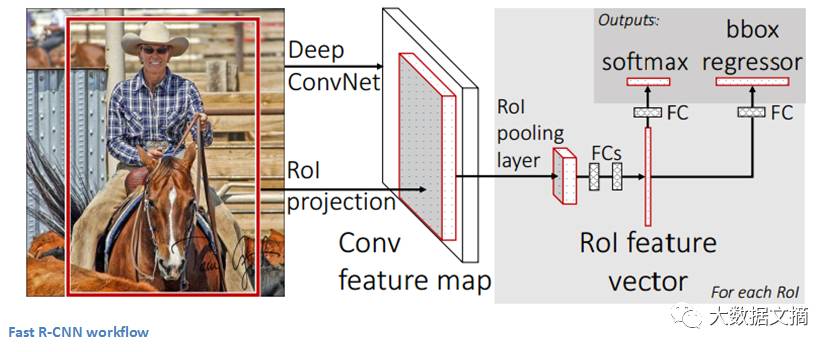
Faster R-CNN可以用于解决R-CNN和Fast R-CNN所使用的复杂的训练管线 。 作者在最后一个卷积层之后插入了一个区域候选网络(region proposal network,RPN)。 该网络能够在仅看到最后的卷积特征图后就从中产生区域建议。 从那个阶段开始,与R-CNN相同的管道就被使用了(感兴趣区域池层 ROI pooling,全连接层FC, 分类classification,回归regression… )。
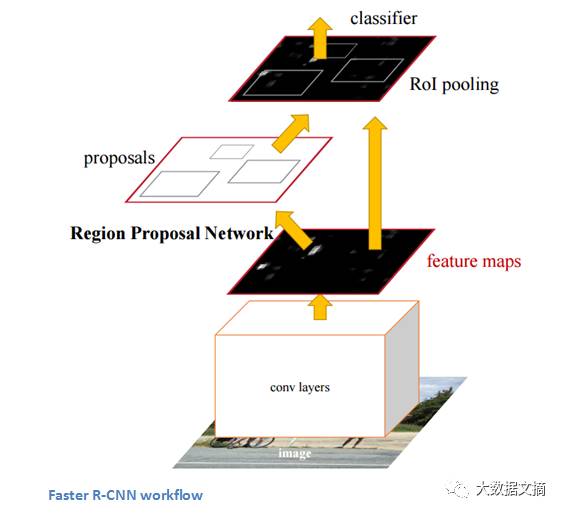
Faster R-CNN工作流程
能够确定特定对象在图像中是一回事,但是能够确定对象的确切位置是另外一回事,那是计算机知识的巨大跳跃。 Faster R-CNN已经成为今天对象检测程序的标准。
据Yann LeCun介绍,这些网络可能是下一个大发展。 在谈论这篇文章之前,让我们谈谈一些对抗范例。 例如,让我们考虑一个在ImageNet数据上运行良好的CNN。 我们先来看一个示例图,再用一个干扰或一个微小的修改使预测误差最大化,预测的对象类别结果因此而改变,尽管扰动后的图像相比愿图像本身看起来相同。 从高层视野 来看,对抗组示例基本上是愚弄ConvNets的图像。

对抗的例子(《神经网络中的有趣属性》)肯定让很多研究人员感到惊讶,并迅速成为一个令人感兴趣的话题。现在我们来谈一谈生成对抗网络。让我们来看两个模型,一个生成模型和一个判别模型。鉴别模型的任务是,确定一个给定的图像是否看起来自然(来自数据集的图像)或者看起来像人造的。生成器的任务是创建图像,使鉴别器得到训练并产生正确的输出。这可以被认为是一个双玩家间的零和博弈(zero-sum)或最大最小策略(minimax)。
该论文中使用的类比是:生成模式就像“一批冒牌者试图生产和使用假货”,而判别模式就像“警察试图检测假冒货币”。生成器试图愚弄判别器,而判别器试图不被生成器愚弄。随着模型的训练,两种方法都得到了改进,直到“假冒品与正品无法区分”为止。
听起来很简单,但为什么我们关心这些网络呢?正如Yann LeCun 所说,判别器现在知道“数据的内部表示”是因为它已理解来自数据集的真实图像和人为创建的之间的差异。 因此,你可以把它作为一个特征提取器用于CNN中 。 此外,您可以创建一些非常酷的人造图像,而且这些图像在我看来是很自然的(The Eyescream Project) 。
Generating Image Descriptions (2014)
https://arxiv.org/pdf/1412.2306v2.pdf
当你把CNN与RNN组合起来时会发生什么?不好意思,您不会得到R-CNN的。但是你会得到一个非常棒的应用程序。 作者Andrej Karpathy(我个人最喜欢的作者之一)和Fei-Fei Li一起撰写了这篇论文, 研究了CNN和双向RNN (Recurrent Neural Networks)的组合,以生成不同图像区域的自然语言描述。大体来讲,该模型能够拍摄一张图像并输出如下图片:

这很不可思议!我们来看看这与正常的CNN相比如何。 对于传统的CNN,训练数据中每个图像都有一个明确的标签。 本论文中所描述的模型,其每个训练实例都具有一个与各个图像相关联的句子或标题 。 这种类型的标签被称为弱标签,其中句子的成分指的是图像的(未知)部分。 使用这个训练数据,一个深度神经网络“推断出句子的各个部分和他们描述的区域之间的潜在对应”(引自论文)。 另一个神经网络将图像作为输入,并生成文本描述。 让我们来看看这两个组件:对准和生成。
这一部分模型的目标是,对齐视觉数据和文本数据(图像及其句子描述)。 该模型通过接受图像和句子作为输入,输出它们的匹配 程度得分。
现在让我们考虑将这些图像表现出来。 第一步是将图像送到R-CNN中,以便检测各个物体。 该R-CNN已对ImageNet数据进行了训练。 最先的19个(加上原始图像)对象区域被嵌入到500维的空间中。 现在我们有20个不同的500维向量(在论文中由v表示)。 我们有了关于图像的信息,现在我们想要有关句子的信息。 我们通过使用双向循环神经网络,将单词嵌入到同一个多模态空间中。 从最高层次来说,这是用来说明给定句子中单词的上下文信息的。 由于关于图片和句子的信息都在相同的空间中,我们可以通过计算它们的内积来得到它们的相似度。
对准模型的主要目的是创建一个数据集,其中包括一组图像区域(由RCNN找到)和其相应的文本(由BRNN找到)。 现在,生成模型将从该数据集中学习,以生成给定图像的描述。 该模型接收图像并交给CNN处理。最软层(softmax layer)被忽略,因为完全连接层的输出将成为另一个RNN的输入。 RNN的功能是形成一个句子中不同单词的概率分布(RNN也需要像CNN那样训练)。
免责声明:这绝对是本章节中诘屈聱牙的论文之一,所以如果有任何更正或其他解释,我很乐意听到他们的意见。

组合使用这些看似不同的RNN和CNN模型来创建一个非常有用的应用程序,对我来说是个有趣的想法,这是结合计算机视觉和自然语言处理领域的一种方式。 这开启了处理跨领域的任务时实现计算机和模型更加智能化的新思路。
Spatial Transformer Networks (2015)
最后,让我们走近一篇最近发表的论文。这篇文章是由Google Deepmind的一个小组在一年多前撰写的,主要贡献是引入空间变换模块。这个模块的基本思想是, 以一种方式转换输入图像,使得随后的图层更容易进行分类。作者担心的是在将图像在输入特定的卷积层之前出现的更改,而不是对CNN主体架构本身进行的更改 。这个模块希望纠正的两件事情是,形状正则化(对象被倾斜或缩放)和空间注意力(引起对拥挤图像中的正确对象的关注)。对于传统的CNN,如果你想使模型对不同尺度和旋转的图像保持不变性,你需要大量的训练示例。让我们来详细了解这个变换模块是如何帮助解决这个问题。
传统CNN模型中,处理空间不变性的实体是最大分池层[1] ( maxpooling layer)[2] 。 这一层背后的直观原因是,一旦我们知道某一个特定的特征位于原始输入空间内(任何有高激活值的地方),它的确切位置就不像其他特征的相对位置那样重要了。 这种新的空间变换器是动态的,它将为每个输入图像产生不同的行为(不同的扭曲或变换)。 它不仅仅是一个传统的maxpool那么简单和预定义。 我们来看看这个变换模型的工作原理。 该模块包括:
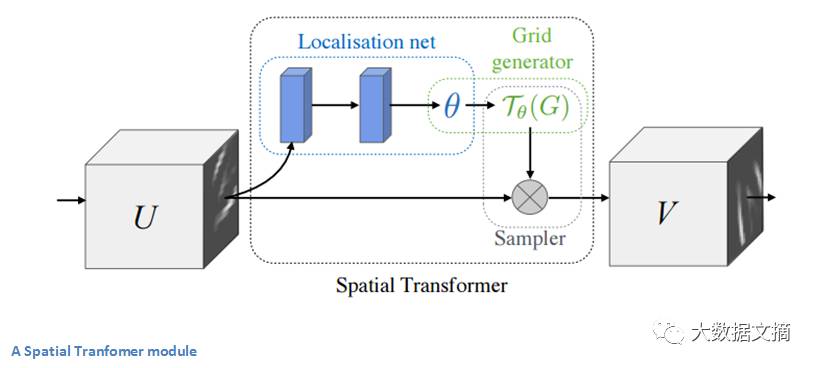
该模块可以随时投入CNN,并且会帮助网络学习如何以在训练中以最小化成本函数的方式来转换特征图。
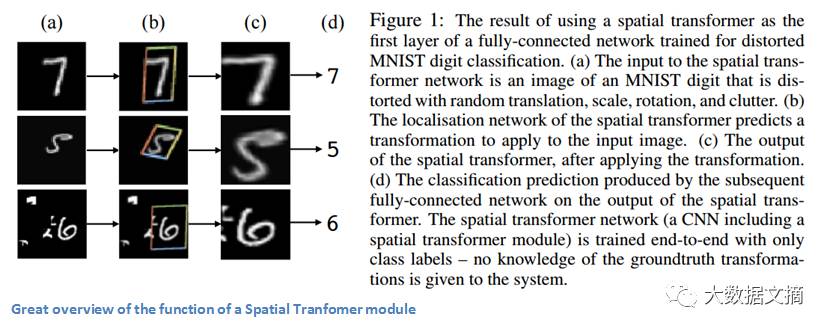
这篇论文之所以引起了我的注意,主要是因为它告诉我们CNN的改进不一定要来自网络架构的巨大变化,我们不需要创建下一个ResNet或Inception模块。 这篇论文实现了对输入图像进行仿射变换的简单思想,使得模型对转换、缩放、旋转操作变得更加稳定。
我们的《CNN入门手册》系列就正式结束了,希望大家通过阅读这一系列对卷积神经网络有了较为深入的了解。如果你想学习到更多关于卷积神经网络的知识,我再次强烈推荐斯坦福CS 231n课程视频。
鞠躬!









