作者:郁松、章邯、程超、癫行
前言
2016财年,阿里巴巴电商交易额(GMV)突破3万亿元人民币,成为全球最大网上经济体,这背后是基础架构事业群构筑的坚强基石。
在2016年双11全球购物狂欢节中,天猫全天交易额1207亿元,前30分钟每秒交易峰值17.5万笔,每秒支付峰值12万笔。承载这些秒级数据背后的监控产品是如何实现的呢?接下来本文将从阿里监控体系、监控产品、监控技术架构及实现分别进行详细讲述。
1、阿里监控体系
阿里有众多监控产品,且各产品分工明确,百花齐放。
整个阿里监控体系如下图:
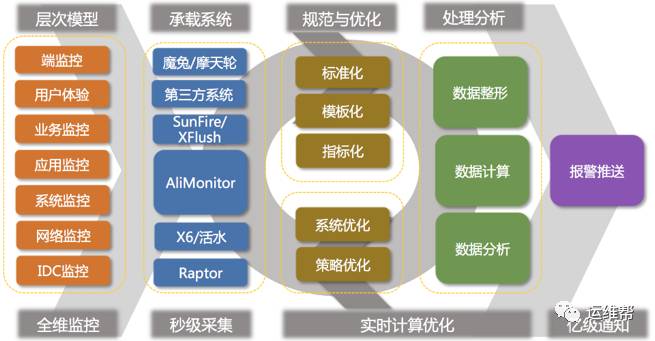
集团层面的监控,以平台为主,全部为阿里自主研发(除引入了第三方基调、博睿等外部检测系统,用于各地CDN用户体验监控),这些监控平台覆盖了阿里集团80%的监控需求。
此外,每个事业群均根据自身特性自主研发了多套监控系统,以满足自身特定业务场景的监控需求,如广告的GoldenEye、菜鸟的棱镜、阿里云的天基、蚂蚁的金融云(基于XFlush)、中间件的EagleEye等,这些监控系统均有各自的使用场景。
阿里的监控规模早已达到了千万量级的监控项,PB级的监控数据,亿级的报警通知,基于数据挖掘、机器学习等技术的智能化监控将会越来越重要。
阿里全球运行指挥中心(GOC)基于历史监控数据,通过异常检测、异常标注、挖掘训练、机器学习、故障模拟等方式,进行业务故障的自动化定位,并赋能监控中心7*24小时专业监控值班人员,使阿里集团具备第一时间发现业务指标异常,并快速进行应急响应、故障恢复的能力,将故障对线上业务的影响降到最低。
接下来将详细讲述本文的主角:承载阿里核心业务监控的SunFire监控平台。
2、监控技术实现
2.1 监控产品简介
SunFire是一整套海量日志实时分析解决方案,以日志、REST 接口、Shell 脚本等作为数据采集来源,提供设备、应用、业务等各种视角的监控能力,从而帮您快速发现问题、定位问题、分析问题、解决问题,为线上系统可用率提供有效保障。
SunFire利用文件传输、流式计算、分布式文件存储、数据可视化、数据建模等技术,提供实时、智能、可定制、多视角、全方位的监控体系。其主要优势有:
-
全方位实时监控:提供设备、应用、业务等各种视角的监控能力,关键指标秒级、普通指标分钟级,高可靠、高时效、低延迟。
-
灵活的报警规则:可根据业务特征、时间段、重要程度等维度设置报警规则,实现不误报、不漏报。
-
管理简单:分钟级万台设备的监控部署能力,故障自动恢复,集群可伸缩。
-
自定义便捷配置:丰富的自定义产品配置功能,便捷、高效的完成产品配置、报警配置。
-
可视化:丰富的可视化 Dashboard,帮助您定制个性化的监控大盘。
-
低资源占用:在完成大量监控数据可靠传输的同时,保证对宿主机的 CPU、内存等资源极低占用率。
2.2 监控架构
Sunfire技术架构如下:
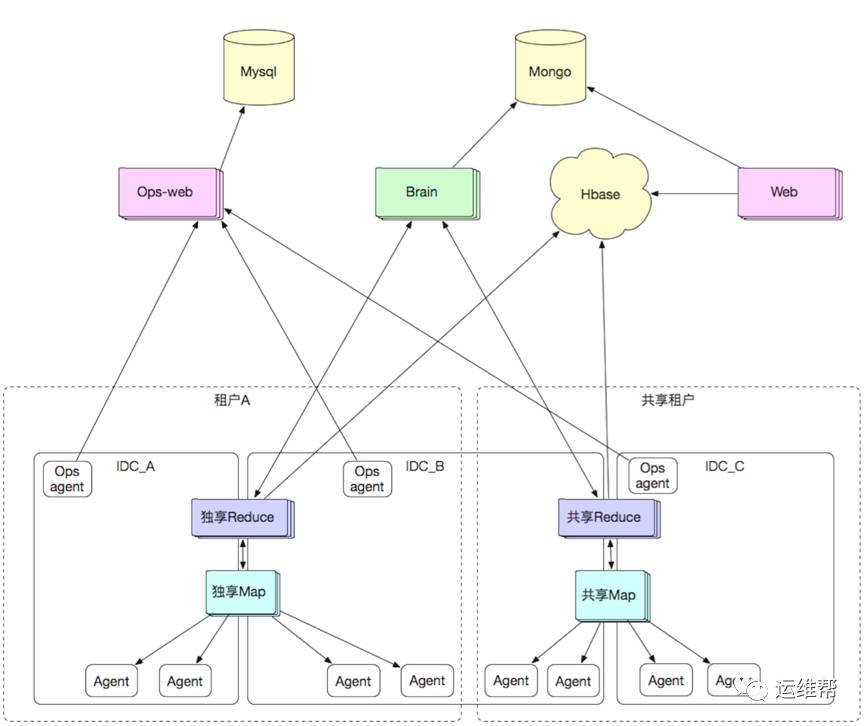
2.3.1 采集
Agent负责所有监控数据的原始采集,它以 Agent 形式部署在应用系统上,负责原始日志的采集、系统命令的执行。
2.3.1.1 定位
日志原始数据的采集,按周期查询日志的服务,且日志查询要低耗、智能。Agent上不执行计算逻辑。
2.3.1.2 特性
低耗
采集日志,不可避免要考虑日志压缩的问题,通常做日志压缩则意味着它必须做两件事情:一是磁盘日志文件的内容要读到应用程序态;二是要执行压缩算法。
这两个过程就是CPU消耗的来源。但是它必须做压缩,因为日志需要从多个机房传输到集中的机房。跨机房传输占用的带宽不容小觑,必须压缩才能维持运转。所以低耗的第一个要素,就是避免跨机房传输。SunFire达到此目标的方式是运行时组件自包含在机房内部,需要全量数据时才从各机房查询合并。
网上搜索zero-copy,会知道文件传输其实是可以不经过用户态的,可以在linux的核心态用类似DMA的思想,实现极低CPU占用的文件传输。SunFire的Agent当然不能放过这个利好,对它的充分利用是Agent低耗的根本原因。以前这部分传输代码是用c语言编写的sendfile逻辑,集成到java工程里,后来被直接改造为了java实现。
最后,在下方的计算平台中会提到,要求Agent的日志查询服务具备“按周期查询日志”的能力。这是目前Agent工程里最大的难题,我们都用过RAF(RandomAccessFile),你给它一个游标,指定offset,再给它一个长度,指定读取的文件size,它可以很低耗的扒出文件里的这部分内容。然而问题在于:周期≠offset。从周期转换为offset是一个痛苦的过程。
在流式计算里一般不会遇到这个问题,因为在流式架构里,Agent是水龙头,主动权掌握在Agent手里,它可以从0开始push文件内容,push到哪里就做一个标记,下次从标记继续往后push,不断重复。这个标记就是offset,所以流式不会有任何问题。
而计算平台周期任务驱动架构里,pull的方式就无法提供offset,只能提供Term(周期,比如2015-11-11 00:00分)。Agent解决此问题的方式算是简单粗暴,那就是二分查找法。而且日志还有一个天然优势,它是连续性的。所以按照对二分查找法稍加优化,就能达到“越猜越准”的效果(因为区间在缩小,区间越小,它里面的日志分布就越平均)。
于是,Agent代码里的LogFinder组件撑起了这个职责,利用上述两个利好,实现了一个把CPU控制在5%以下的算法,目前能够维持运转。其中CPU的消耗不用多说,肯定是来自于猜的过程,因为每一次猜测,都意味着要从日志的某个offset拉出一小段内容来核实,会导致文件内容进入用户态并解析。这部分算法依然有很大的提升空间。
日志滚动
做过Agent的同学肯定都被日志滚动困扰过,各种各样的滚动姿势都需要支持。SunFire的pull方式当然也会遇到这个问题,于是我们简单粗暴的穷举出了某次pull可能会遇到的所有场景,比如
这段逻辑代码穷举的分支之多,在一开始谁都没有想到。不过仔细分析了很多次,发现每个分支都必不可少。
查询接口
Agent提供的查询服务分为first query和ordinary query两种。做这个区分的原因是:一个周期的查询请求只有第一次需要猜offset,之后只需要顺序下移即可。而且计算组件里有大量的和Agent查询接口互相配合的逻辑,比如一个周期拉到什么位置上算是确定结束?一次ordinaryquery得到的日志里如果末尾是截断的(只有一半)该如何处理…… 这些逻辑虽然缜密,但十分繁琐,甚至让人望而却步。但现状如此,这些实现逻辑保障了SunFire的高一致性,不用担心数据不全、报警不准,随便怎么重启计算组件,随便怎么重启Agent。但这些优势的背后,是值得深思的代码复杂度。
路径扫描
为了让用户配置简单便捷,SunFire提供给用户选择日志的方式不是手写,而是像windows的文件夹一样可以浏览线上系统的日志目录和文件,让他双击一个心仪的文件来完成配置。但这种便捷带来的问题就是路径里若有变量就会出问题。所以Agent做了一个简单的dir扫描功能。Agent能从应用目录往下扫描,找到同深度文件夹下“合适”的目标日志。
2.3.2 计算
由Map、Reduce组成计算平台,负责所有采集内容的加工计算,具备故障自动恢复能力及弹性伸缩能力。
2.3.2.1 定位
计算平台一直以来都是发展最快、改造最多的领域,因为它是很多需求的直接生产者,也是性能压力的直接承担者。因此,在经过多年的反思后,最终走向了一条插件化、周期驱动、自协调、异步化的道路。
2.3.2.2 特性
纯异步
原来的SunFire计算系统里,线程池繁复,从一个线程池处理完还会丢到下一个线程池里;为了避免并发bug,加锁也很多。这其中最大的问题有两个:CPU密集型的逻辑和I/O密集型混合。
对于第一点,只要发生混合,无论你怎么调整线程池参数,都会导致各式各样的问题。线程调的多,会导致某些时刻多线程抢占CPU,load飙高;线程调的少,会导致某些时刻所有线程都进入阻塞等待,堆积如山的活儿没人干。
对于第二点,最典型的例子就是日志包合并。比如一台Map上的一个日志计算任务,它要收集10个Agent的日志,那肯定是并发去收集的,10个日志包陆续(同时)到达,到达之后各自解析,解析完了data要进行merge。这个merge过程如果涉及到互斥区(比如嵌套Map的填充),就必须加锁,否则bug满天飞。





