本文是大数据杂谈 7 月 21 日社群公开课分享整理,也是第四范式主题月的第三堂公开课内容。
大家好,我是第四范式的陈迪豪,目前负责先知机器学习平台的架构与实现。
今天很高兴和大家分享《打造机器学习的基础架构平台》的话题,主要会介绍机器学习底层原理和工程实现方面的内容,也欢迎大家会后多多交流。
基础架构(Infrastructure)相比于大数据、云计算、深度学习,并不是一个很火的概念,甚至很多程序员就业开始就在用 MySQL、Django、Spring、Hadoop 来开发业务逻辑,而没有真正参与过基础架构项目的开发。在机器学习领域也是类似的,借助开源的 Caffe、TensorFlow 或者 AWS、Google CloudML 就可以实现诸多业务应用,但框架或平台可能因行业的发展而流行或者衰退,而追求高可用、高性能、灵活易用的基础架构却几乎是永恒不变的。
Google 的王咏刚老师在《为什么 AI 工程师要懂一点架构》提到,研究院并不能只懂算法,算法实现不等于问题解决,问题解决不等于现场问题解决,架构知识是工程师进行高效团队协作的共同语言。Google 依靠强大的基础架构能力让 AI 研究领先于业界,工业界的发展也让深度学习、Auto Machine Learning 成为可能,未来将有更多人关注底层的架构与设计。
因此,今天的主题就是介绍机器学习的基础架构,包括以下的几个方面:
基础架构的分层设计;
机器学习的数值计算;
TensorFlow 的重新实现;
分布式机器学习平台的设计。
大家想象一下,如果我们在 AWS 上使用编写一个 TensorFlow 应用,究竟经过了多少层应用抽象?首先,物理服务器和网络宽带就不必说了,通过 TCP/IP 等协议的抽象,我们直接在 AWS 虚拟机上操作就和本地操作没有区别。其次,操作系统和编程语言的抽象,让我们可以不感知底层内存物理地址和读写磁盘的 System call,而只需要遵循 Python 规范编写代码即可。然后,我们使用了 TensorFlow 计算库,实际上我们只需调用最上层的 Python API,底层是经过了 Protobuf 序列化和 swig 进行跨语言调研,然后通过 gRPC 或者 RDMA 进行通信,而最底层这是调用 Eigen 或者 CUDA 库进行矩阵运算。
因此,为了实现软件间的解耦和抽象,系统架构常常采用分层架构,通过分层来屏蔽底层实现细节,而每一个底层都相当于上层应用的基础架构。
那么我们如何在一个分层的世界中夹缝生存?
有人可能认为,既然有人实现了操作系统和编程语言,那么我们还需要关注底层的实现细节吗?这个问题没有标准答案,不同的人在不同的时期会有不同的感受,下面我举两个例子。
在《为了 1% 情形,牺牲 99% 情形下的性能:蜗牛般的 Python 深拷贝》这篇文章中,作者介绍了 Python 标准库中 copy.deep_copy() 的实现,1% 的情况是指在深拷贝时对象内部有可能存在引用自身的对象,因此需要在拷贝时记录所有拷贝过的对象信息,而 99% 的场景下对象并不会直接应用自身,为了兼容 100% 的情况这个库损失了 6 倍以上的性能。在深入了解 Python 源码后,我们可以通过实现深拷贝算法来解决上述性能问题,从而优化我们的业务逻辑。
另一个例子是阿里的杨军老师在 Strata Data Conference 分享的《Pluto: 一款分布式异构深度学习框架》,里面介绍到基于 TensorFlow 的 control_dependencies 来实现冷热数据在 GPU 显存上的置入置出,从而在用户几乎不感知的情况下极大降低了显存的使用量。了解源码的人可能发现了,TensorFlow 的 Dynamic computation graph,也就是 tensorflow/fold 项目,也是基于 control_dependencies 实现的,能在声明式机器学习框架中实现动态计算图也是不太容易。这两种实现都不存在 TensorFlow 的官方文档中,只有对源码有足够深入的了解才可能在功能和性能上有巨大的突破,因此如果你是企业内 TensorFlow 框架的基础架构维护者,突破 TensorFlow 的 Python API 抽象层是非常有必要的。
大家在应用机器学习时,不知不觉已经使用了很多基础架构的抽象,其中最重要的莫过于机器学习算法本身的实现,接下来我们将突破抽象,深入了解底层的实现原理。
机器学习,本质上是一系列的数值计算,因此 TensorFlow 定位也不是一个深度学习库,而是一个数值计算库。当我们听到了香农熵、贝叶斯、反向传播这些概念时,并不需要担心,这些都是数学,而且可以通过计算机编程实现的。
接触过机器学习的都知道 LR,一般是指逻辑回归(Logistic regression),也可以指线性回归(Linear regression),而前者属于分类算法,后者属于回归算法。两种 LR 都有一些可以调优的超参数,例如训练轮数(Epoch number)、学习率(Learning rate)、优化器(Optimizer)等,通过实现这个算法可以帮忙我们理解其原理和调优技巧。
下面是一个最简单的线性回归 Python 实现,模型是简单的 y = w * x + b。
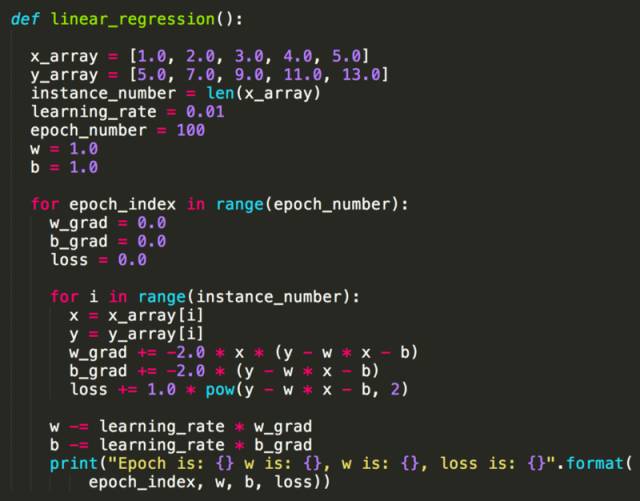
从这个例子大家可以看到,实现一个机器学习算法并不依赖于 Scikit-learn 或者 TensorFlow 等类库,本质上都是数值运算,不同语言实现会有性能差异而已。细心的朋友可能发现,为什么这里 w 的梯度(Gradient)是 -2 * x * (y – x * x –b),而 b 的梯度这是 -2 * (y – w * x - b),如何保证经过计算后 Loss 下降而准确率上升?这就是数学上保证了,我们定义了 Loss 函数(Mean square error)为 y – w * x - b 的平方,也就是说预测值越接近 y 的话 Loss 越小,目标变成求 Loss 函数在 w 和 b 的任意取值下的最小值,因此对 w 和 b 求偏导后就得到上面两条公式。
如果感兴趣,不妨看一下线性回归下 MSE 求偏导的数学公式证明。

转自:大数据杂谈









