出品 | AI科技大本营(ID:rgznai100)
一年一度在人工智能方向的顶级会议之一AAAI 2020于2月7日至12日在美国纽约举行,旨在汇集世界各地的人工智能理论和
领域应用的最新成果。
以下是蚂蚁金服的技术专家对入选论文
《基于长短期老师的样本蒸馏方法》与
《自动车险定损系统:
像专业定损员一样读取和理解视频》
做出的深度解读。
此前,AI科技大本营(ID:rgznai100)已发布
《基于可解释性通道选择的动态网络剪枝方法》与《无语预训练的网络剪枝技术》
两篇论文的深度解读文章。

基于长短期老师的样本蒸馏方法(
LongShort-Term Sample Distillation
)
随着深度学习的快速发展,神经网络的深度迅速增加。
而由于存在梯度消失、过拟合等问题,越深的神经网络越难训练。
在过去的一段时间里,如何训练深度神经网络已经取得了很大的进展。
最近一些关于老师-学生模型的研究表明,在同一个训练过程中,前面训练过程的历史信息可以作为后面训练过程的老师,从而使模型的训练更稳定,达到更好的效果。
在这篇文章中,我们提出了Long Short-Term Sample Distillation(LSTSD)方法来从两方面提升深度神经网络的效果。
一方面,LSTSD将历史训练过程的信息分为两部分:
长期信号和短期信号。
长期信号来自于n(n>1)训练周期之前,并在较长的一段时间内保持稳定,从而保证学生模型和老师模型之间的差异性。
短期信号来自于上一个训练周期,并在每个周期都更新为最新的信息,从而保证老师模型的质量。
另一方面,每一个样本的老师信号都来自于不同的历史训练时刻,因此在训练的每个时刻,模型都是同时向多个历史时刻的模型学习,集百家之所长,从而得到更好的训练效果。
我们在自然语言处理和计算机视觉的多个任务上进行了实验,实验结果证明我们提出的LSTSD的有效性。
简介
近年来的许多工作证明了基于知识蒸馏思想的老师-学生模型能够帮助训练深度神经网络。
老师-学生模型的训练通常分为两个阶段:
在第一阶段先预训练好一个老师模型,在第二阶段固定老师模型,用于指导学生模型的训练。
老师-学生模型最初被应用在将复杂神经网络压缩成简单神经网络,在预测精度几乎无损失的同时获得预测加速。
后来的一些工作发现老师-学生模型还可以用于模型的精度提升,这些工作通常先训练一个老师模型,然后重新随机初始化一个和老师模型有相同结构的学生模型,学生模型的监督信息包括:
真实标签和老师模型输出的概率分布。
此外,还有一些工作证明同时向多个老师模型学习能进一步提升学生模型的效果。
最近的一些工作提出在一个阶段里实现老师-学生模型优化,核心思想是用前面训练过程的历史信息作为老师,指导模型的后续训练过程。
这些工作证明在老师-学生模型中,老师的质量以及老师-学生差异性是非常重要的两个因素。
如果老师的质量太差,可能会给学生带来噪声,而如果老师和学生的差异性太小,那么学生没法从老师学到很多知识。
而在一阶段老师-学生模型中很难同时保证这两点,因为随着训练的进行,高质量的老师应该是离当前时刻很近的模型;
而差异性大的老师却应该是离当前时刻较远的模型,这两者相互矛盾。
我们提出的LSTSD将训练过程的历史信息解构成两部分:
长期信号和短期信号。
长期信号和短期信号。
长期信号来自于n(n>1)训练周期之前,并在较长的一段时间内保持稳定,从而保证学生模型和老师模型之间的差异性。
短期信号来自于上一个训练周期,并在每个周期都更新为最新的信息,从而保证老师模型的质量。
此外,每一个样本的老师信号都来自于不同的历史训练时刻,因此在训练的每个时刻,模型都是同时向多个历史时刻的模型学习,能进一步提升效果。
解读
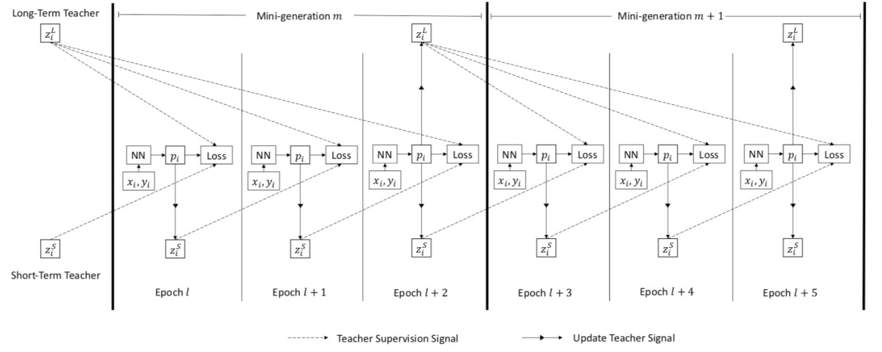
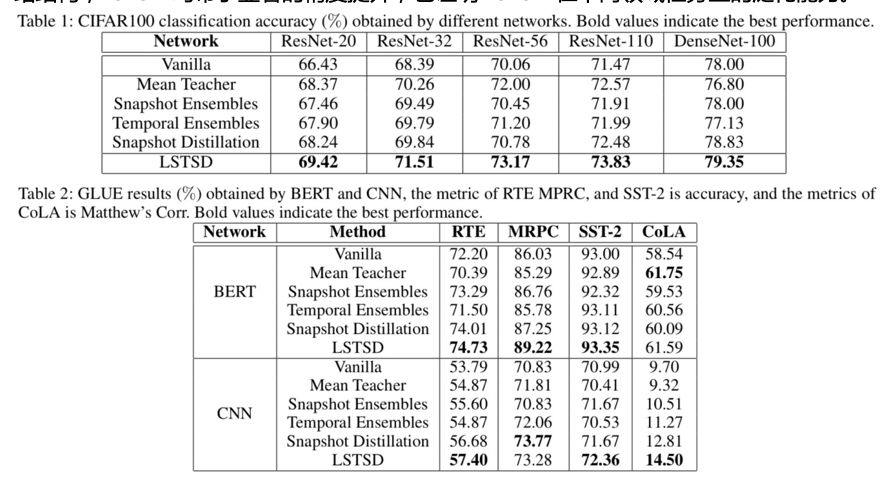
如上图,首先我们将整个训练过程分为多个子训练过程(mini-generation),每个子训练过程包含若干个训练周期(epoch),每个训练周期中每个样本会随机被挑选一次作为训练样本更新网络参数。
每个样本的长期老师来自于上一个子训练过程的最后一个训练周期,短期老师来自于上一个训练周期。
给定一个样本(xi,yi),以其在第(m+1)个子训练过程中第(l+4)个训练周期为例,它的短期老师来自于上一个周期(即第(l+3)个训练周期)中(xi,yi)被选中时的网络参数。
假设(xi,yi)在第r步被随机挑选作为训练样本,则其短期老师为此时刻网络对它预测的概率分布:
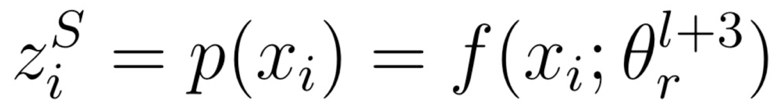
它的长期老师来自于上一个子训练过程最后一个训练周期(即第l+2个训练周期)中(xi,yi)被选中时的网络参数。
假设(xi,yi)在第w步被随机挑选作为训练样本,则其长期老师为此时刻网络对它预测的概率分布:
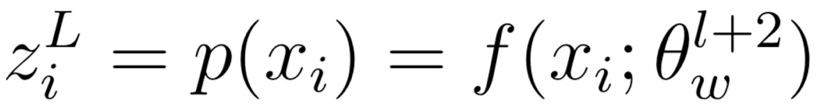
样本(xi,yi)的监督信号分为三部分:
真实标签、长期信号、短期信号。
因此总的目标函数为:
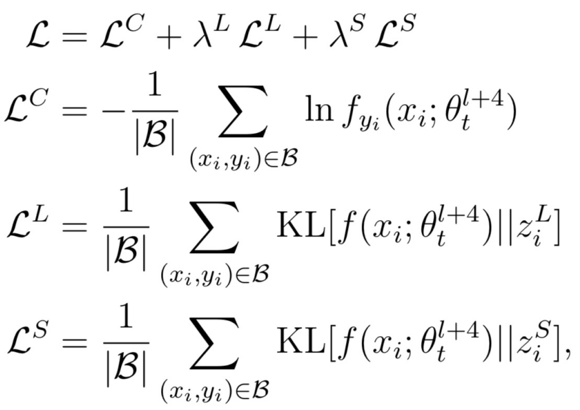
由于每个样本的老师信号来自于它被选中时刻的网络对它的概率输出,在每个训练周期中选择训练样本的顺序都不一样,因此在第(l+4)个训练周期中每一批样本来自于第(l+3)、(l+2)个训练周期中不同批,因此每一批样本都对应了多个时刻的老师模型。
而学生模型在每一个时刻都在同时向多个老师学习。
这种实现方式的好处在于不会增加额外的计算时间代价,相比于存网络参数的方式,耗费的存储空间也非常小。
我们在计算机视觉和自然语言处理的多个分类任务上进行了实验,实验结果表明对于多种网络结构,LSTSD均带了显著的精度提升,也证明LSTSD在不同领域任务上的泛化能力。
应用
我们提出的方法LSTSD已经在蚂蚁金服若干场景落地,包括分类任务、匹配任务、排序任务,这也证明了LSTSD的通用性。
未来我们还将继续探索LSTSD的改机,以及在更多场景进行落地。

自动车险定损系统:
像专业定损员一样读取和理解视频
车险定损是车险理赔中最为重要的操作环节。以往传统保险公司的车险处理流程,一般为报案、现场查勘、提交理赔材料、审核、最终赔付。传统流程对用户和保险公司分别造成了时间成本和人力、管理成本。本文提出的自动车险定损系统不仅能通过AI算法替代定损环节中重复性人工作业流程,而且能通过深度学习技术让用户在车险理赔过程中现场拍摄视频,在几秒内就能得到准确的定损结论,并快速获得理赔。
目前有相关工作在用户拍摄的照片上进行车险定损,拍摄照片对拍摄距离有较高的要求,用户交互复杂。也有采用远程视频会议系统,由专业定损员在控制中心指导拍摄过程并进行定损。本系统采用拍摄视频的方式在云端自动定损,简化了用户交互过程,降低了定损成本。
系统架构与实现方案
通过计算机视觉技术进行定损会遇到以下挑战:(1)在不可控的场景下,由于拍摄角度、距离、对焦等因素影响,用户很难拍摄出高质量的视频或图像(2)车辆表面的反光、污渍、贴画等容易被误识别为损伤(3)深度学习需要的训练数据标注成本很高,需要一定的专业知识,像素级分割标注成本更高。针对上述挑战,本文采用前端拍摄模块来引导用户拍摄高质量和适当距离的视频。通过视频中的多帧融合,来抑制定损过程中遇到的噪声。基于弱监督学习模型采用检测框标注数据来提高损伤定位精度以获取像素级分割结果。
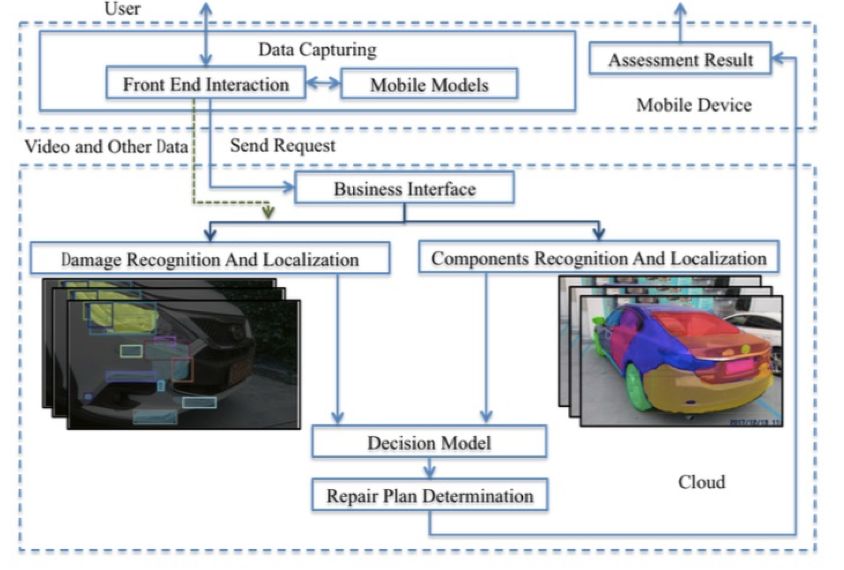
系统整体框架
系统主要包括:数据采集、车损识别和定位、车辆部件识别和定位、决策和维修方案四个部分。
-
数据采集模块
前端交互模块用来引导用户拍摄高质量视频,本文采用移动端的推理引擎来调用部署在移动端的轻量级深度模型,从而指导拍摄过程。
在拍摄过程中,通过友好简洁的用户交互来引导拍摄距离的远近,同时视频关键内容和其他相关信息被上传到云端来进行分析识别。
-
车损识别定位模块
车损识别可被定义为多类别检测或者分割问题。
训练模型需要大量的丰富的标注样本,分割所需的像素级标注成本较高,很多情况下损伤纹理边界也难以定义清楚。本文采用检测模型和弱语义分割融合的方法,从标注框中学习更精确的像素级分割结果。另外,可以进一步利用从视频中提取的多帧图像,通过时间一致性和内容互补性进一步滤除噪声提高召回率。
-
车辆部件识别定位模块
采集的远距离拍摄的帧图像有利于识别车辆部件,近距离的有利于识别损伤细节。
现有的基于图片的算法一般需要用户手动拍摄两种图像,用户交互复杂。本文的关键帧抽取算法从视频中自动抽取两种图像,模型检测部件的同时也分割出部件边界,并利用多帧图像结果的融合得到更精确的识别结果。
-
决策和维修方案模块
给定了损伤和部件识别结果之后,决策模型学习对损伤部件和损伤程度进行预测,系统基于定价策略把预测结果转换为维修方案。
上述识别模块和决策模块没有设计成端到端的模型,这样在每个阶段可以利用多个模型的融合来提高精度。
本文分别用基于视频和基于图像的车险定损app采集了1000个以上的案例,并在数据采集质量和定损精度上进行了对比。在预先定义好的高质量数据评测标准上,视频比图像高出20%。在定损平均精度上,视频比图像高出29.1%。
用例
当车辆事故发生时,车主可以用本系统来评估车损。具体来说,用户根据拍摄引导过程,拍摄远距离和近距离的视频。在拍摄过程中,视频被上传到云端完成损伤识别。最终维修方案和价格评估返回前端后,用户可以决定理赔或者个人完成维修。
结束语
本文展示了基于视频采集、理解分析技术的车险自动定损系统,讨论了高质量数据采集、提升车损识别质量、降低分割标注成本的难点和技术方案。实际应用表明本系统比基于图像的定损更有效,不仅提高标准化定损的准确率,更重要的是,可以让没有定损专业知识的普通用户自助定损,进一步提升用户理赔体验,降低保险公司成本。










