
授权摘自吆喝科技
摘要:
重度雾霾天,你出门可能戴口罩,也可能没戴。如果没戴口罩,今天痛苦地咳嗽了 100 分钟(会不会挂掉?),你会很后悔地想:要是我今天记得戴口罩,那么我可能只会咳嗽 10 分钟。戴口罩的话你会咳嗽 10 分钟,不戴口罩的话你会咳嗽 100 分钟,咳嗽 10 分钟和 100 分钟分别就是这两个处理所对应的潜在结果。因为你实际上没戴口罩而咳嗽了 100 分钟,所以,这戴口罩只咳嗽 10 分钟的潜在结果只是你想象的结果,不是实际发生和观察到的。
听起来是不是有点反事实 (Counterfactual) 推断的味道?是的,潜在结果就是这种想象中的:假如我这几年买的是美股,而不是 A 股,那结果就是赚 100 万,而不是赔 100 万了(捶胸顿足)。
有点意思?那继续……下面才是正菜。
这不只是一篇干货文,
,
还是本文作者的公开课邀请函
报名具体方式见文末
对 A/B 测试有了解的读者都知道,A/B 测试通过用户分组进行在线试验,可以对比产品两个版本的方案找出哪一个更好。但是很多人可能会问:我为什么一定要用 A/B Testing?Google Analytics 这么强大,我的产品的用户访问一目了然,通过数据分析不难找到问题所在,A/B 测试还有必要吗?
这篇文章里,作者将从因果关系方面仔细分析为什么在关键的产品决策时,您需要 A/B Testing,而不仅仅是像 GA 这种观察性的数据分析工具。
相关性与因果关系
▼
前面问题的回答从统计学上看很简单,GA 这种观察性的数据分析工具主要用于探索性的研究,它长于发现问题,而不是解决问题;它可以用来发现事物之间的相关性,但是很难用来确认因果关系。
在概率论和统计学中,相关(Correlation,或称相关系数),显示两个随机变量之间线性关系的强度和方向。
——维基百科
相关性在探索性的研究中是很有用的,它可以在实践中预示某种关系,指明进一步研究的方向。相关性的典型例子是产品的需求和价格的关系,空气质量和汽车数量的关系。这两个相关性的例子都暗示了更进一步的因果关系,因为从经济学上看价格下降会提升需求,汽车数量增加使得尾气排放量增加而导致空气质量变差。但是,不是所有的相关性都有因果关系,相关并不意味着因果。
15 Insane Things That Correlate With Each Other
这个网站收集了很多看起来很荒谬的相关性例子。
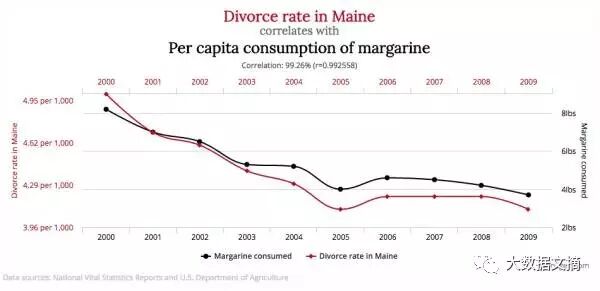
上面的例子中,美国缅因州的离婚率和人均黄油消耗量在 2000 年至 2009 年间达到了极强的相关性(相关系数 0.9926)。吃黄油和离婚明显是没有因果关系的两件事,因为根据我们的常识,吃多点黄油不至于让人性情大变而导致离婚,离婚之后也不太可能因为心情沮丧而多吃黄油。
如果我们的研究目的是找出缅因州离婚率下降的主因,人均黄油消耗量和离婚率之间的相关性有用吗?显然这个相关性的作用是很有限的,你不能据此得出结论:
少吃黄油有助于婚姻和谐。
我们希望得到的是和离婚率之间的因果关系,这就需要针对性的调查或试验。吃黄油和离婚两者表面上的相关性顶多起到提示性的作用(假如有的话),例如,研究人员可能会想到,是否有一个第三因素,导致了缅因州离婚率和黄油消耗量的共同下降,如经济形势?
因果关系在很多应用场合是我们的核心关注点,例如产品的优化方案。
更醒目的 Call to Action 按钮是否会促进着陆页的转化?什么样的表单用户更愿意去完成?这些问题的背后都是一些 PM 需要去确证的因果关系,正是 A/B 测试可以大展身手的地方。
A/B 测试也称为在线对照试验 (Online Controlled Experiments) ,是一种科学地进行统计因果推断的研究方法,它和其他统计研究方法(如观察性研究)的主要区别在于它可以通过针对性的试验简单高效地对所考察的因素和变量间的因果关系进行科学地推断。
那到底什么是因果关系呢?
▼
因果关系是一个事件(即“因”)和第二个事件(即“果”)之间的关系,其中后一事件被认为是前一事件的结果。一般来说,因果还可以指一系列因素(因)和一个现象(果)之间的关系。对某个结果产生影响的任何事件都是该结果的一个因素。
——维基百科
A/B 测试要研究的就是这种简单逻辑上的因果关系,而不是先有鸡还是先有蛋这种近乎哲学上的因果。
确切地说,我们通过试验要证明的是:某个因素/处理是否会对某个现象/结果产生作用。

下面我们将根据统计学上的潜在结果模型,仔细分析因果关系的定义和推断过程。
潜在结果
▼
首先明确一下统计学上因果关系的定义。在试验的上下文中,我们讨论的因果关系是和某个处理 (treatment) 关联在一起的,作用的目标主体是参加试验的个体。
一个或多个处理作用在个体上产生的预期效果我们称之为潜在结果 (Potential outcome)。
之所以称为潜在结果是因为在一个个体上最终只有一个结果会出现并被观察到,也就是和个体所接受的处理相对应的那个结果。另外的潜在结果是观察不到的,因为它们所对应的处理并没有实际作用在该个体上。
举个例子,今天北京是重度雾霾天(很正常),你出门可能戴口罩了,也可能没戴口罩(忘了,很不幸!)。这个小试验的个体就是你,戴口罩和不戴口罩就是两个不同的处理。戴或者不戴,当然只能选一个,结果也只能观察到一个。

如果你没有戴口罩,今天痛苦地咳嗽了 100 分钟(会不会挂掉?),你会很后悔地想:要是我今天记得戴口罩,那么我可能只会咳嗽 10 分钟。戴口罩的话你会咳嗽 10 分钟,不戴口罩的话你会咳嗽 100 分钟,咳嗽 10 分钟和 100 分钟分别就是这两个处理所对应的潜在结果。
因为你实际上没戴口罩而咳嗽了 100 分钟,所以,这戴口罩只咳嗽 10 分钟的潜在结果只是你想象的结果,不是实际发生和观察到的。
听起来是不是有点反事实 (Counterfactual) 推断的味道?是的,潜在结果就是这种想象中的:假如我这几年买的是美股,而不是 A 股,那结果就是赚 100 万,而不是赔 100 万了(捶胸顿足)。
因果效果
▼
在定义了潜在结果之后,不同的处理产生的因果效果 (Causal effect)就很清楚了,它就是不同潜在结果的比较。

在上面的例子中,作用在个体“你”上的因果效果就是戴口罩咳嗽 10 分钟 - 不戴口罩咳嗽 100 分钟 = 少咳嗽 90 分钟。我们用符号 Y 来表示潜在结果,Y(不戴口罩) 和 Y(戴口罩) 分别表示两个不同处理(戴 or 不戴口罩)情况下的潜在结果。
我们可以看出,
因果效果的定义依赖于潜在结果,但是它并不依赖于哪一个潜在结果实际发生。
无论你今天戴了口罩(观测到咳嗽 10 分钟)还是没戴口罩(观测到咳嗽 100 分钟),个体的因果效果都是不变的(戴口罩少咳嗽 90 分钟)。
可能你会问了:事实上我今天没戴口罩,我知道我咳嗽了 100 分钟,但是我怎么知道如果我戴了口罩,只会咳嗽 10 分钟呢?这确实是个问题,戴或者不戴口罩,你只能选择一个,观测到一个结果。聪明的读者可能会想到一个解决办法:你可以今天不戴口罩,明天戴口罩,对比一下,不就知道了吗?这个办法在逻辑和推断上不是那么严谨的,因为今天和明天,尽管只隔了一天,但是很多情况会发生变化,导致今天戴口罩和明天戴口罩观察到的咳嗽时间是不一样的。
例如,虽然北京的雾霾每天都很醇,但是今天和明天还是有差别的,可能今天和燕京啤酒一样醇,明天和茅台一样醇,那么你今天戴口罩会咳嗽10次,明天戴还是要咳嗽 100 次。很明显,有雾霾时段这个另外的因素影响的话,我们就不知道戴口罩的效果是多少了,因为第二天的醇如茅台的雾霾完全抵消了你戴口罩的效果,让你误以为戴口罩没有用。
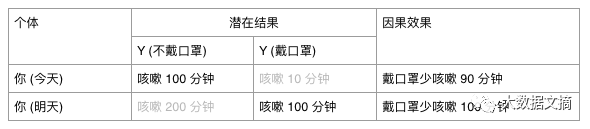
我们都知道 A/B 测试是隔绝了其他影响因素条件下对某个因素的效果进行比较,而把今天的结果和明天的结果进行直接比较的做法已经不是严谨的对照试验了。从潜在结果模型的观点来看,今天的“你”和明天的“你”已经不是同一个统计个体了 (⊙o⊙)(虽然从物理上看,明天的你还是原来的你),而个体级别的因果效果是对同一个统计个体而言的。因此,对比个体在不同时段得到的潜在结果不再能够反映个体的因果效果,据此决策将导致逻辑上错误的结论。
难道就没有办法了吗?是的,时光不能倒流,你不可能在不戴口罩观测一次之后再回退然后戴口罩重来一次。对于作用在个体上的因果效果而言,我们确实没有太好的办法。从因果效果的定义上来看,因为两个潜在结果你注定只能观测到其中一个,所以你不能只靠一个实际观测结果就知道比较的效果,这是统计因果推断要解决的一个基本问题。
不过好消息是在 A/B 测试中我们关心的是如何“估计”总体中所有个体上的平均因果效果,没必要准确知道每一个个体的因果效果。因此,和上面类似的办法在恰当的统计模型下也是可行的。
这里我们要注意到因果效果的“定义”和“估计”的区别。
大家都知道统计是一门以概率为基础的科学,统计推断得到的结论不是绝对正确的唯一结果,而是有一定概率分布的多种可能结果。
我们进行因果推断的主要任务是要得到有一定概率保证的“估计”,而不是绝对符合“定义”的正确结果。
因果效果的“估计”和“定义”相比所要进行的潜在结果的比较是不同的。因果效果的定义不要求多个个体,而对于估计和推断,我们需要比较实际观测到的潜在结果,我们不得不考虑多个个体的情况。因为单个个体我们只能观测到一个潜在结果,我们必须观测多个个体,其中一部分和另外一部分分别接受不同的处理,观测到不同的潜在结果。我们前面说的同一个人在不同时段的比较,以及不同人在同一时段的比较,都属于多个个体的情况。这样的比较尽管不严格符合因果效果的定义,却是估计因果效果的关键方法。
SUTVA 假定
▼
有了多个个体进行观测就万事大吉了吗?统计学家常用的一招还没使出来呢,那就是
把复杂的现实世界简化为理想数学模型的强力手段——假定 (Assumption)。
在因果推断的潜在结果模型中,我们需要一个非常重要的 SUTVA (stable unit treatment value assumption) 假定,它包括两个部分:
-
任何个体的潜在结果不受其他个体所接受处理的影响;
-
每一个个体所接受的处理水平是唯一的,所导致的潜在结果也是唯一的。
我们先看看 SUTVA 假定的第一部分,
无干扰原则:某个体所接受的处理不会影响到其他个体的潜在结果。
以上面的例子来说,就是假定你戴口罩与否不会影响你的朋友小强和小明的咳嗽时间。在我们的雾霾小试验中,这显然是一个很合理的假定。因为个人的力量是有限的,即便你不戴口罩大力呼吸,为北京的空气净化作出了很大个人牺牲,这点微薄贡献和整个北京的雾霾相比是微不足道的,小强和小明吸入的雾霾不会因此变少,当然咳嗽时间也不会有变化。(不过,如果咳嗽能够传染,而你和小明在一起的话,这种情况下无干扰原则可能就不能成立了:你不戴口罩使劲咳嗽传染了带口罩的小明,小明的咳嗽时间也增加了。)
无干扰原则是很重要的,如果个体之间互相干扰,干扰的效果难以确定,那么潜在效果的比较就不准确,不同处理造成的因果效果就很难确定了。在实际应用中,我们通常根据试验的内容及相关的知识来判断这个原则是否成立。在大多数情况下,这个原则是成立或者说近似成立的。但是在某些特殊试验情况下,这个原则是否成立就要慎重考虑了。
例如,在社交类产品如微信的 A/B 测试中,假如产品经理要测试新版的红包设计是否会促使用户发送更多的红包,无干扰原则很可能就不成立了。因为即使看到新版红包的用户很喜欢这个设计从而发送了更多的红包,但是没看到新版红包的用户可能因为收到朋友更多的红包,出于回赠心理也发送了更多的红包,这样新版的用户和老版的用户之间的效果就难以比较了。
SUTVA 假定的第二部分是指所有处理水平都是已知和明确定义的,没有隐藏的不同之处。
以我们的雾霾小试验为例,处理水平只有两个:戴口罩和不戴口罩。这里我们认为,戴口罩的作用对个人是相同的,没有不同牌子的口罩带来过滤效果不同诸如此类的影响。如果你戴的口罩是 3M 牌子,他戴的口罩是 9M 牌子,是 3M 牌子效果的 3 倍,SUTVA 假定的第二部分就不成立了。
我们必须注意到,SUTVA 假定的第二部分并没有要求每个个体所受处理的潜在结果是相同的,它只要求指定个体及处理水平的潜在结果是明确不变的。
SUTVA 假定是使用潜在结果模型进行因果推断的前提,因此,我们在进行试验前,必须认真考虑试验的情况,检查该假定是否成立。如果假定不成立,据此进行推断很难得到可信的结果。
此文中我们介绍了用于 A/B 测试因果推断的潜在结果模型,包括潜在结果的定义,因果效果和 SUTVA 假定等重要的概念,下一篇文章中我们将从统计学上看看这个模型是怎么应用的。
公开课邀请函
·
大数据文摘在本周五晚上,
邀请本文作者为读者们
献上一场公开课。
不过瘾的同学来
猛戳底部海报
,
约一个本周公开课
!

主 题
▼
A/B 测试的基本原理
时间
▼
2016-12-30 20:00
形式
▼
线上分享
扫
底部海报二维码
,添加文文了解详情!

嘉宾介绍
▼
钟书毅
大数据文摘特邀嘉宾;
数据产品经理,
目前任职于A/B测试
云服务平台吆喝科技
负责数据产品;
具有多年技术以及
网站分析经验,
研究兴趣为统计学和机器学习。
分享内容
▼
揭秘 A/B 测试背后的统计学原理:
为什么在产品优化的关键时刻
你需要A/B 测试而不是 GA?
相关性等于因果关系吗?
A/B 测试的潜在结果模型等统计学原理
增长黑客如何设计试验迭代优化产品?

学渣的逆袭:他叛逆狂妄,却搞出不少大新闻





