第一是问题难度,国际象棋棋盘为8x8, 围棋棋盘为19x19,考虑到每次走棋都有近乎19*19的可能性,对整盘棋来说围棋的搜索空间巨大;其次,围棋一次落子,即使在相邻的两个格子上,对结果会产生天差地别的影响,即落子的评价函数是高度不连续和突变的。据说,下围棋要比下国际象棋难大概一百万到十亿倍(吴军:智能时代),围棋代表了人类的最高智力游戏。
第二是算法,深蓝依靠象棋规则的逻辑推理和穷举搜索,AlphaGo则依靠大数据和深度学习智能算法,有两个关键算法,一是采用深度学习网络作为评价落子好坏或获胜概率的评价函数;二是蒙特卡洛树搜索算法缩小搜索空间,减少计算量。还有一点,AlphaGo还能自己左右手互搏,除了用人类棋谱训练自己,还能自我对战、自我学习。
第三是希望,当年深蓝战胜人类冠军后,人类还是有希望破解深蓝,以至于深蓝不再应战;AlphaGo与人类冠军一战后,预示着人类几乎没有希望在围棋上胜出机器智能,年底的Master全胜人类顶级棋手,也已经说明了这点。
毫无疑问,AlphaGo使用了大数据(所有可收集到的棋谱)和机器学习技术,代表了人工智能领域的最近技术水平,但是AlphaGo的胜利并不表示机器智能真的全面战胜人类智能,并不代表未来机器会控制人类。我前面用两篇技术篇介绍了大数据和机器学习的算法原理,弄清楚原理和条件后,就需要分析它的应用,它究竟会在哪些应用领域取得突破?它真的是万能的吗?它有弱点吗?
一、信息来自哪里?
还是从我熟悉的化工行业说起,化学工程就是研究物质和能量转化和转移的过程,所以化工过程的核心就是物质和能量。这是我们对化工传统的认识,但是要实现物质、能量的可控转化和转移,还离不开信息的传递,利用过程信息实现对整个流程的控制。所以在物质、能量之外,化学工程的核心还需要加上信息。
再推广到人类生活的客观世界,客观世界应该有三要素:物质,能量,信息。人类文明的重要发展总是伴随着这三样元素的突破性发展。例如,人类已经经历的三次工业革命:第一次为利用蒸汽的机械化;第二次为利用电的电气化;第三次为利用集成电路的自动化。正在来临的第四次工业革命是利用网络的智能化。
第一、二次工业革命为能源利用方式的革新变化;第三、四次工业革命为信息处理和整合方式的革新变化。当然,每次工业革命除了生产力的变化,工业生产组织方式也会随之变化,例如第二次电气化带来的流水线生产方式。
(题外:几次工业革命都没有体现物质利用的革命性变化,化学工业的出现实现了人类自己设计和创造自然界没有的物质和材料,完全是客观世界(三元素)变化的一个里程碑,不知为何没有列入工业革命?可能工业革命的定义仅局限于工业生产力和组织方式。)
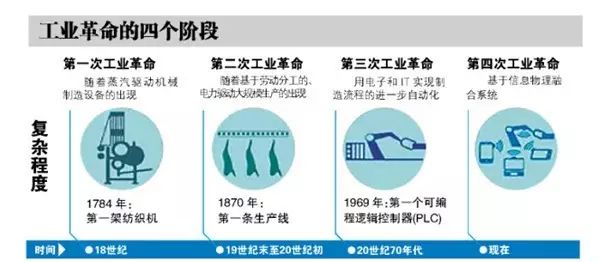
工业革命
那到底什么是信息?信息就是消除不确定的东西。例如对面走来一个人,穿着白裙子,还披着长长的披肩发,手里面拿着IPhone。这段描述里面,第一句话只说是一个人,不确定的内容太多。后面的描述“白裙子和披肩长发”可以确定是女人,消除了一部分不确定性,它们就是信息。
信息来自数据,是对数据的提取和抽象。这里的数据包括数字、文本、图像和声音等一切可以被人类五官直接或者通过仪器间接观察到并记录下的东西。并非所有数据都有信息,例如噪声,只有能消除目标问题不确定性的数据才能产生信息。
科学出现的标志应该是人通过主动设计实验来验证某个假说。科学进一步的发展是主动改变实验条件从而发现试验因素和目标变量之间的相关性,再进一步便是记录下实验数据并提出一个模型来契合(fit)这些实验数据。科学研究的核心手段就是通过实验获取数据,谁有高精准的实验仪器、有大量实验员和科研劳工,谁就越容易产生大量的实验数据,就越容易获得新科学信息和知识。不大量烧钱做实验,不可能产生新科学知识,所以现代科学不存在民间科学家这回事,不说民科就是一般的公司也烧不起这个钱。
二、大数据和人工智能为什么突然爆发了?
科学家和工程师一直在产生数据和分析数据,数据一直都有。我在”技术篇“中介绍了几种经典的机器学习算法,除了深度学习是在2006年提出的,其他算法全部都有20年以上的历史。既然数据和算法都已经长期存在了,为什么2010年后人工智能重焕青春呢?有三个主要原因:
数据:互联网尤其是移动互联网的发展,使得每个人的每一步智能手机就是一个数据发生和收集器,海量个人数据产生,数据收集变得容易。
算法:深度神经网络是目前主流人工智能算法,Hinton等人在2006年提出新的训练算法。
计算能力:2010后云计算兴起,另外发现GPU特别适合深度学习,这两点极大提高了计算效率和缩短训练时间。
正如Hinton在2006年的论文里说:
“… providedthat computers were fast enough, data sets were big enough, and the initialweights were close enough to a good solution. All three conditions are nowsatisfied.”
我认为最重要的因素还是数据的爆发,尤其是移动智能设备导致的个人数据爆发,例如GPS个人位移信息,网络购物和浏览信息,百度搜索记录,微信聊天和朋友圈评论信息。所以大数据和以往的数据处理在本质上的区别还是一个”大(big)“字,但是这个“大”不仅仅指数量大,IBM提出大数据的4V特点:Volume(大量)、Velocity(高速)、Variety(多样)、Value(低价值密度)。
Volume:数据量大,包括采集、存储和计算的量都非常大,TB级起步
Variety:类型繁多,种类和来源多样化,具体表现为网络日志、音频、视频、图片、地理位置信息等等多类型数据。
Velocity:数据增长速度快,处理速度也快,时效性要求高。比如个性化推荐算法尽可能要求实时完成推荐。
Value:数据价值密度相对较低,需要从沙子里面淘金。
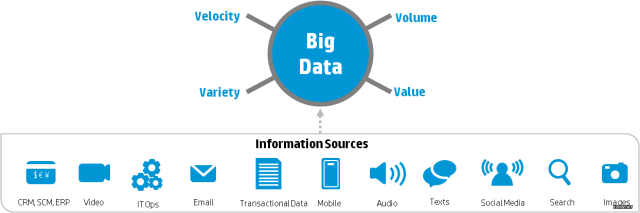
大数据特征
这4个V是互联网数据和传统实验室数据和工业数据主要区别。随着互联网以及物联网的广泛应用,信息感知无处不在,信息海量,但价值密度较低,如何结合业务逻辑并通过强大的机器算法来挖掘数据价值,是大数据时代最需要解决的问题。
用大数据解决现实问题,相关技术可以分为六大方向:
(1)大数据采集与预处理方向--传感器
(2)大数据存储与管理方向--数据库和服务器
(3)大数据计算模式方向--并行计算和云计算
(4)大数据分析与挖掘方向--机器学习。这是大数据的核心,因为要数据的目的就是为了获取信息和知识,让数据真正产生效益!
(5)大数据可视化分析方向--数据可视化
(6)大数据安全方向--信息安全
以上这些大数据的定义可以看出,大数据的概念覆盖了机器学习,并和现在的人工智能概念有较大重叠。再一次强调,我们这些非专业人士,没有必要纠结于概念,三种概念都是从数据中提取信息和知识,最终让机器能够代替人做出决策,形成机器智能。
三、大数据思维和方法为什么会取得成功?
不管自然科学、社会科学还是工程理论,其研究的目的都是找到各个领域的规律,进而利用这个规律做预测,从而进行设计、控制、优化。找规律做预测也有两种途径:
1. 找到相关性,即观察到某个变量发生变化时,另外一个变量也发生变化,则就说两个变量具有相关性。若将第一个变量称为观察变量,第二个变量称为目标变量,在观察变量较目标变量具有时序上先导性性或目标变量不易观察和测量时,利用观察变量预测目标变量是一种好方法。有相关性不一定表示观察变量的变化是目标变量变化的原因,有可能两者变化都是同一个其他因素变化导致。
2. 找到因果性,即找到导致目标变量变化的根本因素,根本因素(原因)发生变化必然导致目标变量(结果)发生变化,两者之间存在必然的关系。
显然找到因果性是解决问题的根本方法,也是实现系统可控性的条件。根本因素必然是独立自由的,而相关性中的观察变量不一定有独立性,有可能只是系统中的一个状态变量。所以要实现目标变量的可控比找到它的一个预测方法困难的多。
另外,即使找到了因果性,如何描述因果性?科技史上牛人都是用一些极其简洁的方程来描述这些因果性规律,例如牛顿万有引力方程、麦克斯韦电磁方程、爱因斯坦的质能方程。在牛顿之后人类产生了机械思维,即这个世界的运行和变化是有规律的、并且是确定的,这些规律可以被认识并用简洁的方程描述,这些规律可以推广的未知领域。这里的“推广”是指应用到更大的范围,例如万有引力方程并非用天体做实验得到的结论,但应用到天体运动也完全正确,即具有普遍适用型。找到这些具有普适性的、表达因果性的简洁方程实在太伟大,以至于100年只能出几个这样的方程。把大学物理翻出来,把自牛顿开始到现在物理发展的所有经典方程抄下来,一页A4纸足以。再看看化学学科,除了几个基本的守恒方程和物理化学中几个方程,再也没有了。寻找这些普适性方程太具偶然性和运气成分了,自然科学、工程技术以及社会科学的发展绝不能仅仅依靠它们。
我们都希望快速解决问题,那就退而求其次,只要能表达因果关系,方程简洁不简洁就不管了,所以我们见到的大部分方程、尤其是工科领域,基本都是所谓的半理论半经验方程或经验方程。化学工程里面,我敢说90%都是这类方程,对一个具体方程,例如压降公式,对流传热膜系数公式,为什么要采用那样的形式?就是因为这个方程形式拟合实验数据比较好,当然还是有一部分的理论依据的。我特别佩服化学工程里面用的一种建模方法:因次分析法,这种方法极大减少了方程里面待定的系数。但如果你仔细思考一下因此分析法,它假设目标变量同所有影响变量的幂形式成正比,显然这个假设不是完全正确的,但是因次分析法建立的模型满足了工程设计的要求和精度。大数据模型在两个方面体现了优越性和成功性。
1 对多变量问题,只要数据足够,大数据模型能够快速地建立一个足够精度的数据模型来描述各个自变量如何影响因变量。
只要数据够准、够全面、够足,建立的数据模型预测性的精度和准度都可以保证,并且数据越多越好,不是用传统的抽样样本而是用所有可用的全样本。虽然利用全样本建立模型增加了建模计算时间,但是节省了难以计量的问题机理研究时间,即用数据收集时间和计算时间换取问题研究时间。
2 仅仅利用相关性也可以建立一个一定精度的预测模型,用相关性代替因果性也能解决很多问题
如前所述,很多问题,尤其是社会学、经济学、医学问题,要找到目标变量变化的根本原因非常困难,很难像理工科一样在实验室创造一个理想实验条件:排除干扰,固定其他所有影响因素,每次只改变一个影响因素,从而可以独立地观察每个可能因素是如何改变目标变量的。同时多个因素变化,很难判断到底是哪个因素对结果产生影响。幸运的是,实现预测并不是只有因果性这一条路可走,还可以利用相关性,利用计算机很容易找到所有变量间的两两相关性,数据量越大,检验出的相关性便越可靠。一个经典案例便是Google的流感预测模型,即利用搜索关键词的变化预测流感的传播区域和时间。
另外,不同的领域对预测精度的要求并不一样,下图来自宝钢郭朝晖博士的报告,看看标题便受益匪浅:要放弃对绝对真理的奢求。很多领域,预测正确性有60~70%就不错了。
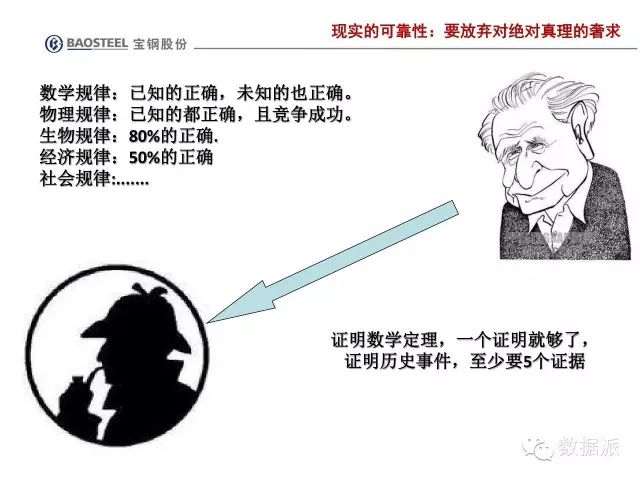
郭朝晖博士讲义
让我们再看看大数据技术或人工智能到底在哪方面应用最成功?在国内,百度是人工智能领域做得最好的公司,其百度大脑已经成功应用于多个领域,当然,这些研究都是跟着Google走,下图是百度大脑主页的截图,可见目前人工智能主要还是应用于语音、图像和机器翻译这些传统的人工智能领域。所有的这些领域的应用,都只能算是利用相关性的预测,根本算不上探寻因果性,预测准确率从来没有不切实际地要求100%准确,但是他们确实具有实际应用所要求的精度了,够成功了。
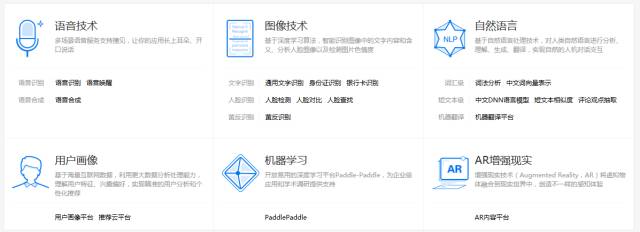
百度大脑应用
未完待续,下文主要谈谈大数据有哪些“不能”!
版权声明:作者保留全文版权,任何其他公众号转载需取得作者同意。欢迎转载和转发!

您若对该文章内容有任何疑问或质疑,请留言,谢谢
创始人微信号:mahoupao2011 服务电话:021-80392998
展会 培训 合作 广告 化工技术难题求助
点击↓↓阅读原文进入原文出处
点击“写留言”↓↓,写您想说






