他是人工智能领域最牛的几位大神之一,他的演讲视频你不能错过。
作者 | 龟途慢慢
毫无疑问,「Yann LeCun」是人工智能领域最为显赫的几个名字之一,作为人工智能领域的世界级专家,他在机器学习等技术上都有卓越的贡献,「卷积神经网络(convolutional neural networks)」更是他的代表作。
在 2013 年年底,Facebook 公司 CEO 扎克伯格确信 AI 技术——这个被他称为「我们这个时代最困难的一项工程挑战」——将会是公司未来的重心,因此,他在这时成立了专注于这个项目的实验室。为此,他找来了当时还在纽约大学的 Yann LeCun 合作,任命其为 Facebook AI 研究院的院长。
当时,LeCun 拒绝离开纽约。为了解决这个问题,Facebook 为 LeCun 在曼哈顿设立了 Facebook AI 实验室的总部。由此也可看出 LeCun 在业界的地位和影响力。
3月22日,作为本次系列课程中唯一的一次公开课,由清华大学经济管理学院发起,清华x-lab与Facebook公司联合设计并推出的《创新与创业:硅谷洞察》第三次课程在清华大学大礼堂开讲。极客公园来到了现场,为大家整理了如下的课堂笔记:
监督学习(Supervised Learning)
首先,LeCun 以监督学习开场,他用非常简洁的例子为大家介绍了监督学习的原理,「就像你给小孩子打开一本书,然后指着一张图片,告诉他这就是大象,然后他就记住这是大象了。只不过区别是你要给机器看成千上万张图片」

深度学习(Deep Learning)
之后,他又简单介绍了一下深度学习(deep learning)技术的发展,并对传统模式识别、主流现代模式识别以及深度学习特征提取方式进行了比对。「它被称为 deep learning 的原因就是因为那些系统可以被划分成许多层(layer),而每一层都是可训练的。」同时,正是因为大量数据的出现以及 GPU 这样的硬件被开发出来,这项技术才在这几年有了突飞猛进的变化。

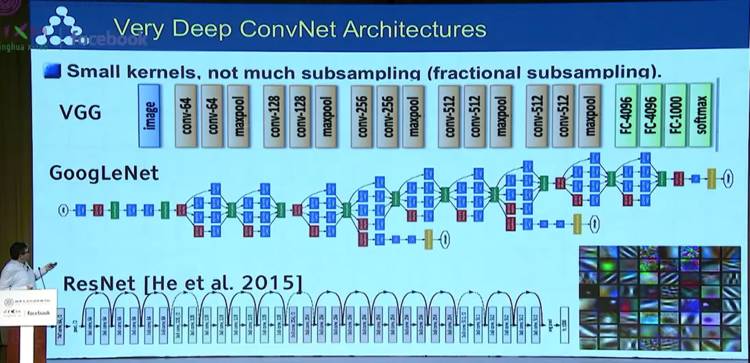
卷积神经网络(Convolutional Neural Network)
这是 LeCun 自己的代表作,他从 1980 年代就开始了这方面的研究。他在演讲中详细讲述了这部分的原理,大家可以看看下面这张幻灯片。他同时提到自己是受了诺贝尔奖得主大卫·休伯尔(David Hubel)以及托斯坦·威泽尔(Torsten Wiesel)的启发才有了相应的灵感,这两位的工作给人们呈现了视觉系统是如何将来自外界的视觉信号传递到视皮层,并通过一系列处理过程(包括边界检测、运动检测、立体深度检测和颜色检测),最后在大脑中构建出一幅视觉图像的。

而卷积神经网络在图像处理的原理上和人类大脑处理相应的问题有异曲同工之妙。
此外,他还给大家展示了一段录制于 1993 年的珍贵视频——年轻的 LeCun 在一台 486 PC 上编写的光学字符识别系统。
同时,LeCun 给大家展示了他在 1995 年所见证的两位机器学习前辈 Jackel 和 Vapnik(当时他们都在贝尔实验室,Jackel 是 Vapnik 的上司)的两个有趣赌局:第一个赌局中,Jackel 声称在 2000 年 3 月 14 日之前,我们就会有一个关于大的神经网络为什么有效的理论解释,当然随后的历史证明他输了;第二个赌局中,Vapnik 声称最迟到 2005 年 3 月 14 日之后,没有人将会继续使用 1995 年的这些神经网络结构,结果 Vapnik 也输了。

他同时表示:「深度学习的要点在于,不仅仅是去分类(classify),而是要代表(represent)这个世界,包括了我们的感知世界和个体世界。」

深度卷积神经网络(Deep ConvNet)
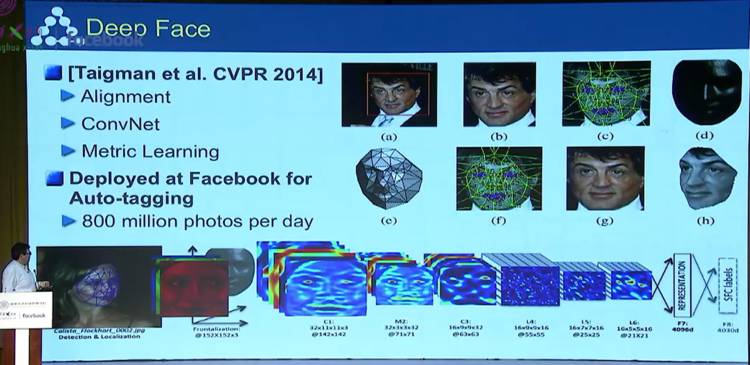
之后,他又介绍了更进一步的深度卷积神经网络(Deep ConvNet),在面部识别、无人驾驶等领域都发挥了很大的作用。

AI 领域进步的最大障碍——怎样使机器获得「常识」?
随后,LeCun 开始讨论 AI 的进步最大障碍:怎样让机器有常识。他列举了以下几点:
-
机器需要学习/理解世界运行的方式
-
机器需要学习非常大量的背景知识
-
机器需要理解世界的状态
-
机器学习更新和记忆对世界状态的估计
-
机器需要推理和规划

所以,在他看来,智能&常识=感知+预测模型+记忆+推理和规划。


他同时认为,常识就是有填补空白的能力,由此,机器必须有「预测」的能力,这也就是他所提出的预测学习(predictive learning)的概念,也就是从提供的任何信息预测过去、现在以及未来的任何一部分。或者,你也可以称其为「无监督学习(unsupervised learning)」。

他同时用了一个例子为我们对比了「强化学习」、「监督学习」以及「无监督学习」之间的区别,我们可以看到他们在需要收集的信息量上有着很大的差距,但同时导致的学习结果也就不太相同。

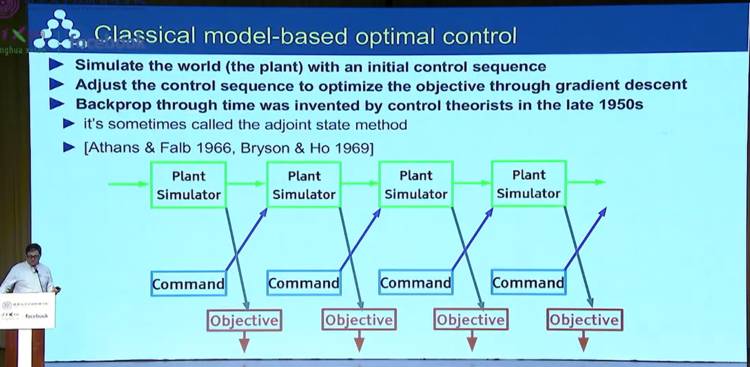
经典基于模型的最优化控制过程(Classical model-based optimal control)
之后,Yann LeCun 介绍了经典基于模型的最优化控制过程(Classical model-based optimal control)。即利用初始控制序列对世界进行仿真,调整控制序列利用梯度下降法对目标进行最优化,再进行反向传播。
随后,他又为我们介绍了人工智能系统的架构。他给出了一个公式:预测+规划=推理。他表示,「智能」的本质就是要有预测的能力,我们需要提前计划,去模拟这个世界,然后采取行动以最小化预测的损失。
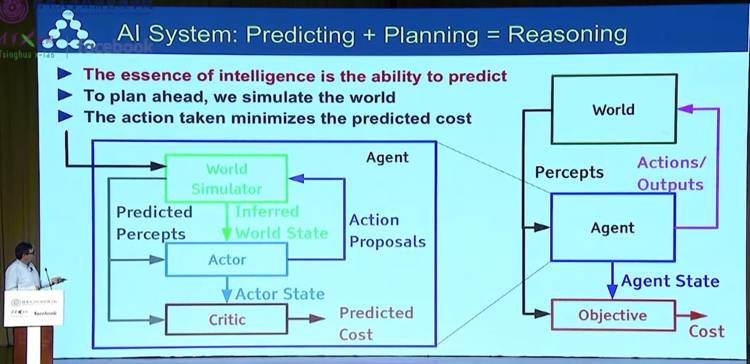
最终得出结论:我们需要的是基于模型的强化学习(Model-based Reinforcement Learning)。
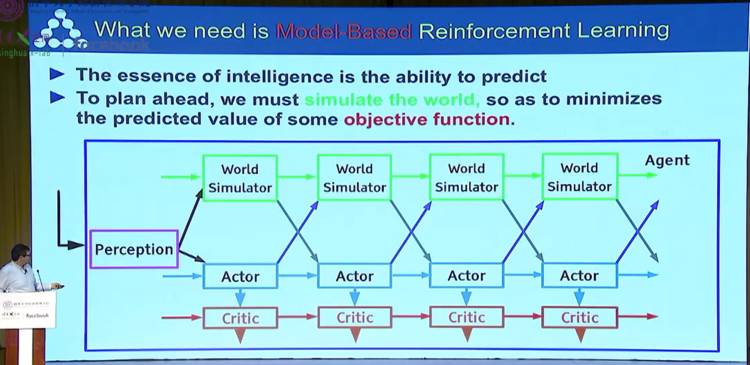
机器去学习能够预测世界的模型
下面这一部分是关于机器如何学习能够预测世界的模型。

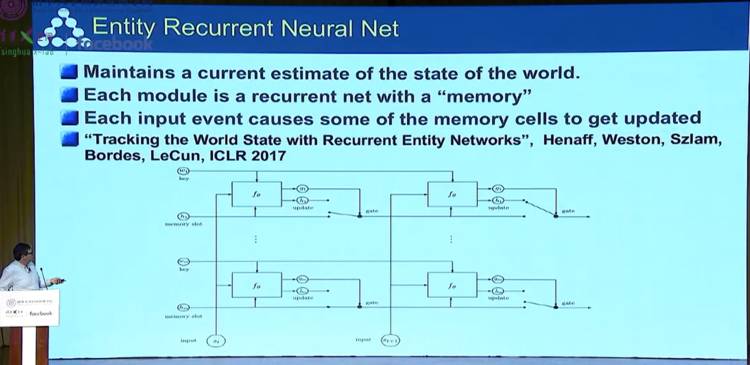
实体神经网络(RNN)
然后,他也介绍了「根据文本推断世界的状态:实体 RNN」

下面这部分谈到了对具有记忆模块的增强神经网络(Augmenting Neural Nets)的使用

这部分谈到了实体循环神经网络(Entity Recurrent Neural Net)的作用:
-
维持一个对于当前世界状态的估计
-
每一个网络都是一个带有一个记忆的循环网络
-
每一个输入事件都会导致记忆单元获得一些更新

这里提到了塑造能量函数(Energy Function)的 7 种策略
对抗训练(Adversarial Training)
接下来的部分是关于对抗训练((Adversarial Training)的,Yann LeCun 本人对对抗训练给予高度肯定,他认为对抗训练是改进机器预测能力的一种方式。

它的难点在于在不确定条件下进行预测
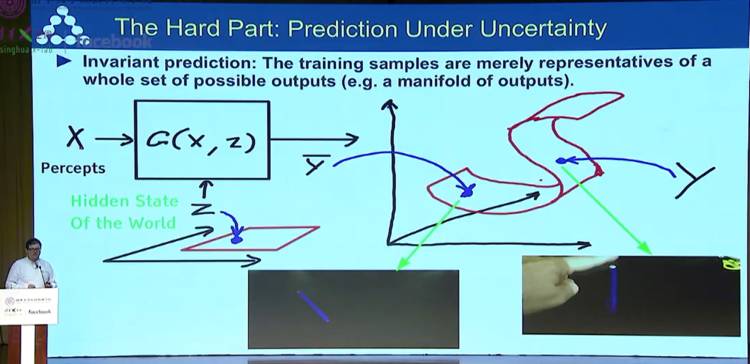
实践中,通用型对抗网络(Generative Adversarial Networks)是一个训练机器预测能力新方法,它的特性可以转化为一些更好、更敏锐、质量更高的预测模型。

为了展现这一点,LeCun 和他的团队用各种图片数据组训练了 DCGAN,这些图片采集了 ImageNet 数据组中一组特定图像,比如所展示的卧室或者动漫人脸识别。

DCGAN 也能够识别模式并将某些相似表征放在一起。比如,在脸部图像数据集中,生成器不理解什么是微笑的意义,但是,它能发现人类微笑图片的相似性,并将它们分为一组。

最后,LeCun 提到了
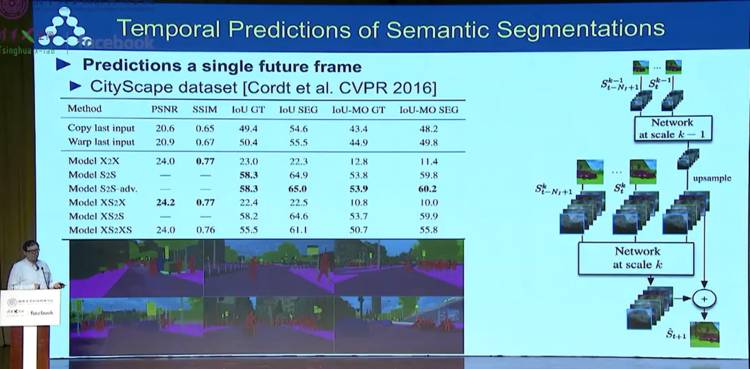
基于语义分割的视频预测技术及时间预测技术。

总结
总结一下,LeCun 首先为我们介绍了一下人工智能领域这些年的发展,然后重点提及了无监督学习,他认为无监督学习会成为未来的主流。同时,他也认为机器必须要有预测未来的能力,而挡在这一过程中的最大障碍就是「常识」。后面,他也强调了对抗训练((Adversarial Training)的价值,认为这项技术之后会发挥越来越大的作用。
而毫无疑问,对于所有对人工智能感兴趣的朋友来说,如果你没能到场亲自聆听 LeCun 的演讲,那我们在这里也为你独家准备了他的演讲视频,不要错过哟。
![]()
本文由极客公园原创
转载联系 [email protected]