用 10 周时间,让你从 TensorFlow 基础入门,到搭建 CNN、自编码、RNN、GAN 等模型,并最终掌握开发的实战技能。4 月线上开课,
www.mooc.ai
现已开放预约。
雷锋网按:
谷歌毕竟就只是发了一篇描述一个数年前就开始的项目的内部结构和一些性能参数的论文和一篇提炼了其中一些内容的博文而已,但前两天 TPU 的发布却让黄仁勋亲自出来发声要把 Google 怼回去,天知道他一边怼心里会不会一边有那么一种 “我为什么要跟他纠结于几倍还是几十倍性能这种破事上…… 本文作者在这里想说,在 TPU 这件事上,谷歌一点也不高调。
距离 Google 发布 TPU 也有一个星期了,掐指一算,国内众媒体和大众的解读的热情也差不多该降下来了。我想在这里说点大家可能不愿意听的。
这次谷歌公布了许多非常详细的技术指标,确实能让许多对 TPU 有好奇心的人一饱眼福。但我看到有些媒体一如既往的秉持小事化大,大事化炸的风格。
尤其是一篇公众号的文章说谷歌在 TPU 的对外宣传上吹的 “天花乱坠”,并由此直线上升到批判西方一向善于 “炒作一些概念”,让我感觉到有些话不吐不快:谷歌毕竟就只是发了一篇描述一个数年前就开始的项目的内部结构和一些性能参数的论文和一篇提炼了其中一些内容的博文而已,很大程度上,这些略显强行的解读并没有什么意义。
TPU 的架构是不是以前就有?
TPU 采用的脉动阵列处理结构,最早由美籍华人计算机科学家孔祥重 (H.T.Kung) 和澳大利亚计算机科学家及数学家 Richard P. Brent 提出,它与现在流行的 SIMD 结构 (单指令多数据流) 结构有相似之处,但又有着明显的区别。
简单解释一下的话,就是在脉动阵列处理结构下,数据向负责处理的运算阵列(运算阵列中有许多个独立的运算单元)传递和处理的方式是有严格的流程规定的,以确保能将所有芯片的处理能力最大限度的发挥出来,在这种计算方式中,需要运算的数字就像流水一样井然有序的 “流” 进每个处理器中,并得到这些处理器的同时处理。
当全部的数字都 “流” 进去的时候,计算也就在同时完成了。这样精细安排结构的代价就是其通用性受到了限制。80 年代初,中科院的前辈们就曾将这种架构的计算设备用在石油勘探上过。
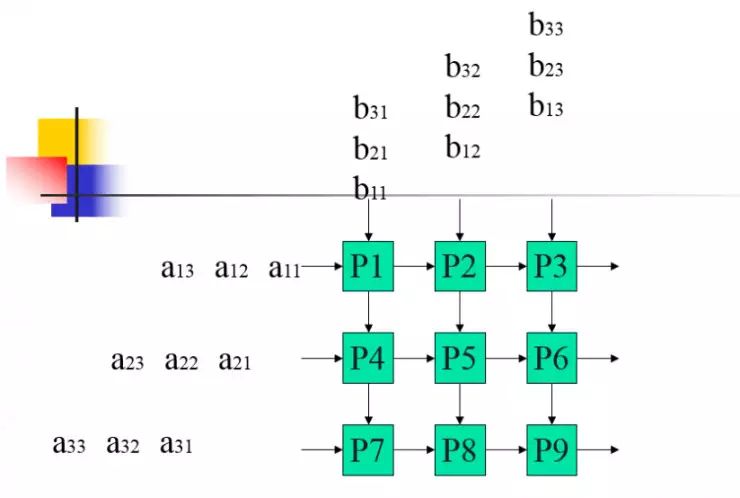
(如果你有一定线性代数基础的话,应该可以理解,上面就是脉动阵列处理机在进行矩阵乘法运算时的过程,举个例子,其中的 a11 每次向右移一格,刚好依次与自己在同一格相遇的 b11、b12、b13 相乘,而 b11 则是每次向下一格,刚好依次与 a11、a21、a31 相乘,以此类推)
这个架构在今天的日常生活中并不多见。相比之下通用性更好的 SIMD 成为了今天的主流。而通用性或许是 SIMD 胜出很关键的一个原因,毕竟相对于在某个领域的速度快点,更多人需要的是一种通用的能满足他们各种需求的计算设备,你不可能要求每个人要用电脑来做什么事之前先根据自己的需求把电路的结构优化一下。
不过当今的世界对于计算能力的需求其实处于一个很矛盾的状态。通用平台早就已经能满足大部分人的需求,以至于像做手机这样的事都慢慢被大家戏称为搭积木——SOC 已经给手机需要的绝大多数运算量提供了一个很好的解决方案,而且这个运算量也已经慢慢超出了大众使用的需求,更不用说电脑了。
但是在另一方面,在一些科研的前沿领域,比如深度学习。计算量却一直显得捉襟见肘,训练一个深度学习算法动辄需要几周甚至几个月。当摩尔定律指出的硬件发展规律慢慢开始表现出瓶颈,开始有人尝试使用一些不那么主流的架构,或者研发一些新的架构。
TPU 就属于找到了一些以前的架构,并尝试能不能利用现在的技术将它的优势更好的发挥出来。
在 TPU 这件事上,谷歌高调吗?
谷歌一点也不高调,而且这种不高调简直是全方位的不高调。首先,TPU 不卖,至少谷歌已经在很多场合公开表示过 TPU 不会进入市场售卖,雷锋网也对此进行过报道。也就是说谷歌完全没有
必要
像英特尔或者英伟达那样费劲吆喝自己的产品,好博取更大的市场份额。
从谷歌自己的表述来看,它之所以设计这么一个专用的芯片,是因为自己的越来越多的产品开始使用非常复杂的深度学习模型,从而产生了真真切切的提升计算能力的需求。
这也是谷歌同英特尔和英伟达这两家同样为
人工智能
设计了芯片的公司的不同之处:后者是看到了市场上这样的需求,于是自己针对这种需求设计了好产品,以期获得更好的销量,而谷歌是自己就有这种需求。所以设计了一个产品来满足它。出发点是满足自己的需求,也同样意味着没有必要向市场太过高调的宣传自己的产品。
事实上谷歌对 TPU 这件事也确实一直比较低调,包括这次的发布,基本也只是在博客上说了一下性能相对于以前硬件的优势,发了一篇中规中矩的论文,不像英特尔和英伟达的新产品通常还要开个发布会,更何况这也不是新产品,而是谷歌内部已经使用了几年的芯片。
谷歌甚至还在论文里说:现在在计算机对新架构的尝试实在是比较少,因此希望 TPU 的发布能给后来者以启示,在此基础上做出更成功的继任产品。
也就是说谷歌都不介意其他厂商模仿自己的产品,只要对计算平台的整体水平有所促进就行。这样的行为,我实在是没法将其与 “天花乱坠的炒作概念” 联系起来。也没有感觉到有什么往市场或者人工
智能
发展方面进行 “深度解读” 的必要性。

谷歌真的在论文里说,“我希望我们的后继者能造出比我们更强的产品”
如果说非要针对 TPU 说出个一二三,那我们到底应该怎么看待它?
前面说过了,TPU 不卖,如果谷歌不反悔的话,这就意味着我们除非自己进了谷歌,想用上 TPU 只能寄希望于谷歌的云服务能开放我们对 TPU 的使用权限了,这首先是说,TPU 不太可能会成为英特尔和英伟达产品的直接竞争对手。但就算 TPU 进入了市场,仍然有许多其他的因素会影响它的最终成绩。
前两天 TPU 的发布还让黄仁勋亲自出来发声要把 Google 怼回去,天知道他一边怼心里会不会一边有那么一种 “我为什么要跟他纠结于几倍还是几十倍性能这种破事上…… 没办法,谁让观众愿意看呢” 的想法。

因为不管大家有没有意识到,一个硬件发布的最终意义,不是去和别的硬件比在这种计算上又快了多少倍,那种计算上又省了多少电,而是它对它的购买者来说,
够不够划算?
对于开发者来说,到底
够不够好用?
(当然,有很多时候这两者可能是同一人)
什么叫划不划算?性价比这个词我相信大家一定不陌生,有些硬件,可能拥有能把整个世界踩在脚下的计算能力,但对于一个全新的领域来说,新硬件的性能越强大,往往也意味着需要越高的水平才能驾驭。在实际的开发中,知道如何用最简洁的方法编写代码、如何使用才能发挥出硬件的最大实力和使用多强的硬件一样重要甚至要更重要。
如果代码写的不好,计算机总是要在重复的步骤上浪费很多时间,那用再强的硬件也没有多大意义。超级大企业里专门研究这种方向的部门肯定有很多厉害的人物,他们会知道如何把这些个硬件的性能榨干到一丝不剩,但是现在和以后可能会出现的更多轻度使用 AI 技术来改善自己业务水平的中小企业往往没有条件和动力去找到这样的人,而且他们对时间的紧迫程度要求也不一定会很高,算法训练慢上几天一个月,他们可能不是很在意。
所以最后影响销量的最大因素可能还是营销和价格…… 除非能在性价比上拉开非常非常大的差距。
在讲到性价比的同时,我们也提到了好不好用。这款硬件是横刀千军、自重三吨的大锤,还是弹药稀缺却能百步穿杨的步枪?一个开发者要花掉多少时间才能学会这个硬件能提供的大部分特性?
它的易扩展性、稳定性到不到位?
这其中任何一点差距都可能导致开发者还没来得及赢回训练算法的那几周时间,先在设计算法上卡了一个月。
一款好的硬件发展的最终境界应该是达到对使用者透明的程度,也就是使用者在编程的过程终不需要去关心它的存在,只要按照自己的需要去写程序就好了,而这个硬件自然就能找到最合适的办法把程序运行出来。越能接近这种程度的硬件,可以说是会越受欢迎的。
目前的这些硬件,不管是 TPU,还是在文章中被拿来和其相比的 K80 和 Haswell CPU,目前在 AI 开发方面都还没法达到这种程度。也就是说,我的看法是:为 AI 定制的硬件估计还有很长的路要走,TPU 与 NVIDIA 和英特尔的同类产品相比,可能有一些优势,但终究没有拉开质的差距,何况以黄仁勋的反应来看,它的性能优势也没有到轻轻松松几十倍那么夸张,仍然能顺利的归入硬件性能的自然发展曲线之列。那在这基础之上,再做更多的琢磨揣测,就显得很无必要了。
无论如何,每一次的进步都是值得我们为之鼓掌的,但同时,也是无需强行解读的。在硬件向着那个方向努力发展的时候,我们只要好好关注这领域的动向,客观的评价每一次进步,并将这些进步应用于自己的实际工作中(如果这是你的工作的话),这样,应该就是对这些努力研发新硬件的先驱者们最大的鼓励了。




