转自老顾谈几何
公众号ID:conformalgeometry
作者:顾险峰
这篇文章是顾险峰老师所写的《看穿机器学习的黑箱》的第三篇,
第一篇
与
第二篇
可点击超链接查看。
上周,老顾访问了UCLA的师兄朱松纯教授和吴英年教授,向他们学习计算机视觉的统计观点。早在二十多年前,以Mumford先生,朱松纯教授为代表的计算机视觉领域的哈佛学派就大力提倡将统计概率系统性地引进到视觉领域,用统计方法来解释和处理视觉领域的基本问题。目前,这一方法论早已在视觉领域深入人心,实际上也是机器学习的理论基础之一。最优传输理论描述了概率分布的几何,因此有助于我们研究视觉方面的机器学习。下面,我们开始撰写第三次讲稿。
直观而言,视觉领域机器学习的统计观点如下:我们将所有可能的图像构成的空间设为
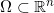 ,其中n是总的像素个数,每张图像视为全图像空间中的一个点
,其中n是总的像素个数,每张图像视为全图像空间中的一个点
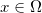 。每个有意义的视觉“概念”(例如所有猫的图像)是全空间
。每个有意义的视觉“概念”(例如所有猫的图像)是全空间
 的一个可测子集,
的一个可测子集,
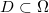 。固定一个概念
。固定一个概念
 ,每张图片是否表达了这个概念就给出了一个概率分布
,每张图片是否表达了这个概念就给出了一个概率分布
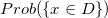 。这样,视觉中的问题就被转化为概率统计的问题:如何表示概率分布,如何衡量概率分布间的距离,如何近似一个概率分布,如何生成满足特定概率分布的随机变量,如何根据概率分布进行统计推断,等等。
。这样,视觉中的问题就被转化为概率统计的问题:如何表示概率分布,如何衡量概率分布间的距离,如何近似一个概率分布,如何生成满足特定概率分布的随机变量,如何根据概率分布进行统计推断,等等。
近年来,依随Internet技术的发展,人类已经积累了大量的视觉数据,这使得估计各种概率分布成为可能。同时,GPU技术的发展,使得各种统计计算方法的实现成为可能。因此,我们迎来了机器学习的科技大潮。但是,我们依然无法严密解释机器学习算法的有效性。
老顾倾向于认为,从基础理论角度而言,研究概率分布的一个强有力工具是最优传输理论(optimal mass transportation theory),这个理论着重揭示概率分布这一自然现象的内在规律,因此并不从属于某个学派,也不依赖于具体的算法。相反,这一理论会为算法的发展提供指导,同时真正合理有效的算法(例如机器学习算法),应该可以被传输理论来解释。
简而言之,传输理论给出了概率分布所构成空间的几何。给定一个黎曼流形,其上所有的概率分布构成一个无穷维的空间:Wasserstein空间,最优传输映射的传输代价给出了Wasserstein空间的一个黎曼度量。Wasserstein空间中的任意两点可以用Wasserstein距离来测量相近程度,自然也可以用测地线来插值概率分布。每个概率分布有熵,沿着测地线熵值的变化规律和黎曼流形的曲率有着本质的关系。这一几何事实在网络领域已经被应用,但在视觉领域,似乎还没有相关工作。
但在实际计算中,高维的最优传输映射,Wasserstein距离计算复杂。一个自然的想法是降维,将高维空间的概率分布投影到低维子空间,在低维空间上计算边际分布之间的变换。这有些象盲人摸象,每次得到局部信息,如果摸得充分,我们也可以恢复大象的整体信息。
在
第一讲
(看穿机器学习W-GAN的黑箱)中,我们给出了最优传输问题的凸几何解释:给定两个概率分布
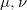 ,存在唯一的最优传输映射
,存在唯一的最优传输映射
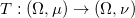 ,将初始概率分布
,将初始概率分布
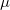 变换成目标概率分布
变换成目标概率分布
 ,
,
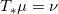 ,同时极小化传输代价,
,同时极小化传输代价,
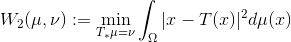 ,
,
这里
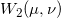 被称为是两个概率分布
之间的Wasserstein距离。同时,最优传输映射是某个凸函数
被称为是两个概率分布
之间的Wasserstein距离。同时,最优传输映射是某个凸函数
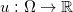 的梯度映射,
的梯度映射,
 ,这个函数满足蒙日-安培方程。我们的理论给出了一种几何变分方法来求解最优传输映射。
,这个函数满足蒙日-安培方程。我们的理论给出了一种几何变分方法来求解最优传输映射。
在
第二讲
(看穿机器学习的黑箱(II))中,我们澄清了这样的观点:相比于学习一个映射,学习一个概率分布要容易很多。满足
的映射构成了一个无穷维的李群。
但是,在视觉问题中,通常图像全空间的维数非常高,计算难度较高。因此,我们可以放弃理论上的最优性,寻找计算更加简单有效,同时又和最优传输距离等价的算法。下面,我们就讨论这些更为实用的算法及其背后的理论。

图1. 直方图均衡化结果(histogram equalization)。
直方图均衡化是提高灰度图像对比度的常见算法。如图1所示,左侧输入图像的灰度分布在一个狭窄区域,朦胧昏暗;右侧是直方图均衡化的结果,清晰明亮,对比鲜明。我们设输入图像像素的灰度为一随机变量,其取值范围为单位区间
 ,其概率测度为
,其概率测度为
 ,直方图均衡化算法的核心就是求灰度空间(单位区间)到自身的一个映射
,直方图均衡化算法的核心就是求灰度空间(单位区间)到自身的一个映射
 ,这一映射将
变换成均匀分布。
,这一映射将
变换成均匀分布。
实际上,传统的直方图均衡化就是一维的最优传送映射。假设我们有两个连续的概率分布
,其对应的累积分布函数(CDF)是
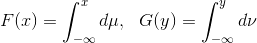 ,
,
那么直方图均衡化映射就是传输映射:
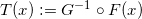 。首先,我们可以证明这个映射满足两个条件:
。首先,我们可以证明这个映射满足两个条件:
-
,
-
单调递增。
另一方面,我们应用最优传输理论:存在一个凸函数,其梯度映射给出最优传输映射。由函数
 的凸性,我们得到最优传输映射也满足上面两条性质。更进一步,我们可以证明,在一维情形,满足上面两条的映射是唯一的。这意味着,
一维直方图均衡化映射就是最优传输映射
。
的凸性,我们得到最优传输映射也满足上面两条性质。更进一步,我们可以证明,在一维情形,满足上面两条的映射是唯一的。这意味着,
一维直方图均衡化映射就是最优传输映射
。
因此,一维的最优传输映射非常容易计算。下面,我们应用一维最优传输映射来近似高维最优传输映射。
有多种最优传输映射的近似算法。我们先讨论
迭代分布传输算法
(Iterative Distribution Transfer ):给定单位向量
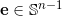 ,我们将整个空间投影到一维线性子空间
,我们将整个空间投影到一维线性子空间
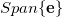 上,投影映射为:
上,投影映射为:
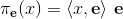 ,
,
投影诱导的概率分布(边际概率分布)记为
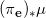 。
在算法第k步,假设当前源空间的概率分布为
。
在算法第k步,假设当前源空间的概率分布为
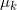 ;我们随机选取欧氏空间
;我们随机选取欧氏空间
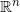 的一个标准正交基
的一个标准正交基
 ;为每一个基底向量
;为每一个基底向量
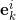 构造一维的最优传输映射
构造一维的最优传输映射
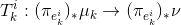 ,
,
由此构造映射,在标架
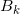 下
下
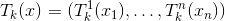 ,
,
其诱导的概率分布为
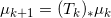 。不停地重复这一步骤,对于足够大的n,复合映射:
。不停地重复这一步骤,对于足够大的n,复合映射:
 ,
,
将初始概率分布
映成了目标概率分布
。
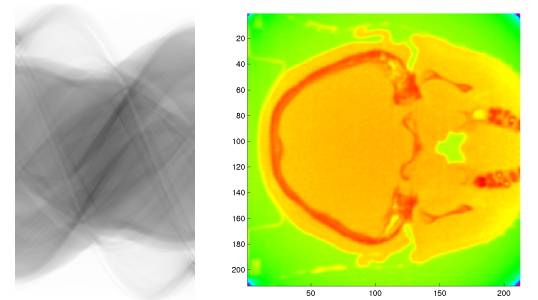
图2. 从拉东变换恢复的医学图像。
这一论断的证明需要用到拉东变换(Radon Transform):给定
 中的一个概率分布
中的一个概率分布
 ,
的Radon transform
,
的Radon transform
 是一族一维的概率测度,
是一族一维的概率测度,
 ,
,
换句话说,给定一个单位向量,它生成一条直线,我们将全空间向这条直线投影,得到边际概率分布。拉东变换的基本定理断言:如果两个概率测度的拉东变换相等,则两个概率测度相等。如图2所示,这一定理是医学图像上CT断层扫描技术的基本原理。
迭代算法如果最后达到一个平衡状态,则在任意一条过原点的直线上,
 的边际概率分布等于
的边际概率分布,因此由拉东变换原理
收敛于
,
的边际概率分布等于
的边际概率分布,因此由拉东变换原理
收敛于
,
 。这样,我们将高维的传输映射转换成一维传输映射的复合,降低了计算难度。
。这样,我们将高维的传输映射转换成一维传输映射的复合,降低了计算难度。
另外一种迭代算法想法比较类似。给定两个
上定义的概率测度
和
 ,对于任意一个单位向量
,对于任意一个单位向量
 ,我们考虑投影映射
,我们考虑投影映射
 。投影映射诱导两个直线上的概率分布
。投影映射诱导两个直线上的概率分布
 和
和
 ,它们之间的最优传输映射记为
,它们之间的最优传输映射记为
 。由此,每个点都沿着
。由此,每个点都沿着
 平移一个向量:
平移一个向量:
 。
。
我们考察所有的单位向量,然后取平均
 ,
,










