作者:李嘉铭
Northwestern University | CS
量子位 已获授权编辑发布
面向读者:没有或有一定机器学习经验并对Prisma之类的app背后的原理感兴趣的读者。比较有经验的读者可以直接参照原文罗列的引用论文。
阅读时间:10-20分钟
注:多图,请注意流量。
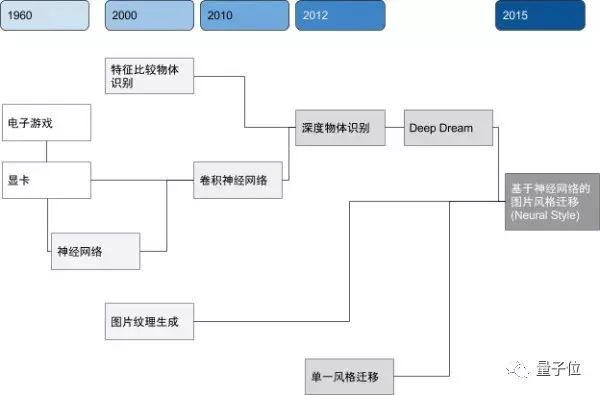
△ 图像风格迁移科技树
序:什么是图像风格迁移?
先上一组图吧。
以下每一张图都是一种不同的艺术风格。作为非艺术专业的人,我就不扯艺术风格是什么了,每个人都有每个人的见解,有些东西大概艺术界也没明确的定义。如何要把一个图像的风格变成另一种风格更是难以定义的问题。
对于程序员,特别是对于机器学习方面的程序员来说,这种模糊的定义简直就是噩梦。到底怎么把一个说都说不清的东西变成一个可执行的程序,是困扰了很多图像风格迁移方面的研究者的问题。

在神经网络之前,图像风格迁移的程序有一个共同的思路:分析某一种风格的图像,给那一种风格建立一个数学或者统计模型,再改变要做迁移的图像让它能更好的符合建立的模型。
这样做出来效果还是不错的,比如下面的三张图中所示,但一个很大的缺点:一个程序基本只能做某一种风格或者某一个场景。因此基于传统风格迁移研究的实际应用非常有限。

△ 景色照片时间迁移
改变了这种现状的是两篇Gatys的论文,在这之前让程序模仿任意一张图片画画是没法想象的。
 △ 第一个基于神经网络的图像风格迁移算法,生成时间:5-20分钟
△ 第一个基于神经网络的图像风格迁移算法,生成时间:5-20分钟
这篇文章中你不会看到数学公式,如果想要更加详细了解其中的数学的话可以阅读原论文。
我想试着从头开始讲起,从Gatys et al., 2015a和Gatys et al., 2015b中用到的一些技术的历史开始讲起,用最简单的方法说清楚基于神经网络的图像风格迁移的思路是什么,以及Gatys为什么能够想到使用神经网络来实现图像风格迁移。
如果大家对这个感兴趣的话,我将来可以继续写一些关于Neural Style最新的一些研究的进展,或者其他相关的一些图像生成类的研究,对抗网络之类的。写的有错误的不到位的地方请随意指正。
Neural Style元年前20年-前3年
要理解对于计算机来说图片的风格是什么,只能追根溯源到2000年以及之前的图片纹理生成的研究上。明明是图像风格迁移的文章,为啥要说到图片纹理?在这儿我先卖个关子吧。
据我所知,在2015年前所有的关于图像纹理的论文都是手动建模的,其中用到的最重要的一个思想是:纹理可以用图像局部特征的统计模型来描述。没有这个前提一切模型无从谈起。什么是统计特征呢,简单的举个栗子——

这个图片可以被称作栗子的纹理,这纹理有个特征,就是所有的栗子都有个开口。
用简单的数学模型表示开口的话,就是两条大概某个弧度的弧线相交嘛,统计学上来说就是这种纹理有两条这个弧度的弧线相交的概率比较大,这种可以被称为统计特征。
有了这个前提或者思想之后,研究者成功的用复杂的数学模型和公式来归纳和生成了一些纹理,但毕竟手工建模耗时耗力,(通俗的说,想象一下手工算栗子开口的数学模型,算出来的模型大概除了能套用在开心果上就没啥用了。。。)当时计算机计算能力还没现在的手机强,这方面的研究进展缓慢,十几年就这么过去了。
 △ 早期纹理生成结果
△ 早期纹理生成结果
与此同时,隔壁的图像风格迁移也好不到哪里去,甚至比纹理生成还惨。
因为纹理生成至少不管生成什么样子的纹理都叫纹理生成,然而图像风格迁移这个领域当时连个合适的名字都没有,因为每个风格的算法都是各管各的,互相之间并没有太多的共同之处。
比如油画风格迁移,里面用到了7种不同的步骤来描述和迁移油画的特征。又比如头像风格迁移里用到了三个步骤来把一种头像摄影风格迁移到另一种上。
以上十个步骤里没一个重样的,可以看出图像风格处理的研究在2015年之前基本都是各自为战,捣鼓出来的算法也没引起什么注意。相比之下Photoshop虽然要手动修图,但比大部分算法好用多了。
 △ 头像风格迁移
△ 头像风格迁移
 △ 油画风格迁移
△ 油画风格迁移
同一个时期,计算机领域进展最大的研究之一可以说是计算机图形学了。(这段有相关知识的可以跳过,不影响之后的阅读。)简单的来说计算机图形学就是现在几乎所有游戏的基础,不论是男友1(战地1)里穿越回一战的战斗场景,还是FGO之类的手游,背后都少不了一代又一代的图形学研究者的工作。
在他们整日整夜忙着研究如何能让程序里的妹纸变成有血有肉的样子的时候,点科技树点出了一个重要的分支:显卡(GPU)。
游戏机从刚诞生开始就伴随着显卡。显卡最大的功能当然是处理和显示图像。不同于CPU的是,CPU早期是单线程的,也就是一次只能处理一个任务,GPU可以一次同时处理很多任务,虽然单个任务的处理能力和速度比CPU差很多。
比如一个128x128的超级马里奥游戏, 用CPU处理的话,每一帧都需要运行128x128=16384歩,而GPU因为可以同时计算所有像素点,时间上只需要1步,速度比CPU快很多。
为了让游戏越来越逼近现实,显卡在过去20年内也变得越来越好。巧合的是,显卡计算能力的爆炸性增长直接导致了被放置play十几年的神经网络的复活和深度学习的崛起,因为神经网络和游戏图形计算的相似处是两者都需要对大量数据进行重复单一的计算。
可以说如果没有游戏界就没有深度学习,也就没有Neural Style。所以想学机器学习先得去steam买买买支持显卡研究(误)。
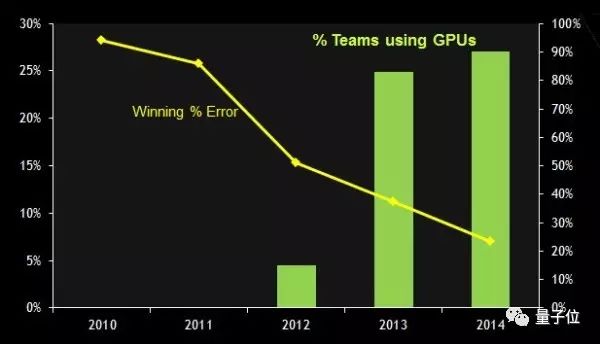
△ ImageNet物体识别比赛中使用GPU的队伍数量逐年上升,错误率逐年下降
提到神经网络我想稍微讲一下神经网络(特别是卷积神经网络)和传统做法的区别,已经有了解的可以跳过本段。卷积神经网络分为很多层,每一层都是由很多单个的人工神经元组成的。可以把每个神经元看作一个识别器,用刚刚的栗子来说的话,每一个或者几个神经元的组合都可以被用来识别某个特征,比如栗子的开口。
在训练前它们都是随机的,所以啥都不能做,训练的过程中它们会自动的被变成一个个不同的识别器并且相互组合起来,大量的识别器组合起来之后就可以识别物体了。整个过程除了一开始的神经网络的设计和参数的调整之外其他全是自动的。
这里我们就不介绍神经网络(Neural Network)和卷积神经网络(Convolutional Neural Network)具体怎么工作的了,如果对于神经网络具体怎么工作不了解的话,相信网上已经有很多很多相关的介绍和教程,有兴趣的可以去了解一下,不了解也不影响本文的阅读。
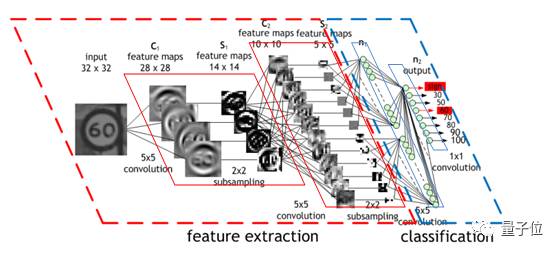
△ 卷积神经网络图例
Neural Style元年前3年-前1年
2012-2014年的时候深度学习刚开始火,火的一个主要原因是因为人们发现深度学习可以用来训练物体识别的模型。
之前的物体识别模型有些是用几何形状和物体的不同部分比较来识别,有些按颜色,有些按3d建模,还有一些按照局部特征。
传统物体识别算法中值得一提的是按照比较局部特征来识别物体,其原理如下。比如我们的目标是在图片之中找到这个人:

△ 目标物体
对于程序而言这个人就是一堆像素嘛,让它直接找的话它只能一个个像素的去比较然后返回最接近的了(近邻算法)。
但是现实中物体的形状颜色会发生变化,如果手头又只有这一张照片,直接去找的速度和正确率实在太低。
有研究者想到,可以把这个人的照片拆成许多小块,然后一块一块的比较(方法叫Bag of Features)。最后哪一块区域相似的块数最多就把那片区域标出来。这种做法的好处在于即使识别一个小块出了问题,还有其他的小块能作为识别的依据,发生错误的风险比之前大大降低了。
 △ Bag of Features
△ Bag of Features
这种做法最大的缺点就是它还是把一个小块看成一坨像素然后按照像素的数值去比较,之前提到的改变光照改变形状导致物体无法被识别的问题根本上并没有得到解决。
用卷积神经网络做的物体识别器其实原理和bag of features差不了太多,只是把有用的特征(feature)都装到了神经网络里了。
刚提到了神经网络经过训练会自动提取最有用的特征,所以特征也不再只是单纯的把原来的物体一小块一小块的切开产生的,而是由神经网络选择最优的方式提取。

△ 卷积神经网络提取的特征示意图,每一格代表一个神经元最会被哪种图片激活
卷积神经网络当时最出名的一个物体识别网络之一叫做VGG19,结构如下:
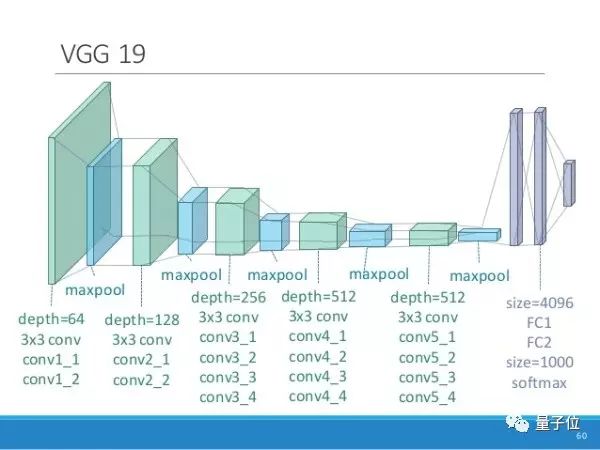 △ VGG19网络结构
△ VGG19网络结构
每一层神经网络都会利用上一层的输出来进一步提取更加复杂的特征,直到复杂到能被用来识别物体为止,所以每一层都可以被看做很多个局部特征的提取器。VGG19在物体识别方面的精度甩了之前的算法一大截,之后的物体识别系统也基本都改用深度学习了。
因为VGG19的优秀表现,引起了很多兴趣和讨论,但是VGG19具体内部在做什么其实很难理解,因为每一个神经元内部参数只是一堆数字而已。每个神经元有几百个输入和几百个输出,一个一个去梳理清楚神经元和神经元之间的关系太难。
于是有人想出来一种办法:虽然我们不知道神经元是怎么工作的,但是如果我们知道了它的激活条件,会不会能对理解神经网络更有帮助呢?
于是他们编了一个程序,(用的方法叫back propagation,和训练神经网络的方法一样,只是倒过来生成图片。)把每个神经元所对应的能激活它的图片找了出来,之前的那幅特征提取示意图就是这么生成的。
有人在这之上又进一步,觉得,诶既然我们能找到一个神经元的激活条件,那能不能把所有关于“狗’的神经元找出来,让他们全部被激活,然后看看对于神经网络来说”狗“长什么样子的?
长得其实是这样的:
 △ 神经网络想象中的狗
△ 神经网络想象中的狗
这是神经网络想象中最完美的狗的样子,非常迷幻,感觉都可以自成一派搞个艺术风格出来了。而能把任何图片稍作修改让神经网络产生那就是狗的幻觉的程序被称作deep dream。
 △ Deep Dream
△ Deep Dream
Neural Style元年
有了这么多铺垫,一切的要素已经凑齐,前置科技树也都已经被点亮了,终于可以进入正题了。基于神经网络的图像风格迁移在2015年由Gatys et al. 在两篇论文中提出:Gatys et al., 2015a和Gatys et al., 2015b。
Gatys et al., 2015a论文地址:
http://papers.nips.cc/paper/5633-texture-synthesis-using-convolutional-neural-networks
Gatys et al., 2015b论文地址:
https://arxiv.org/abs/1508.06576
我们先说第一篇。第一篇比起之前的纹理生成算法,创新点只有一个:它给了一种用深度学习来给纹理建模的方法。之前说到纹理生成的一个重要的假设是纹理能够通过局部统计模型来描述,而手动建模方法太麻烦。
于是Gatys看了一眼隔壁的物体识别论文,发现VGG19说白了不就是一堆局部特征识别器嘛。他把事先训练好的网络拿过来一看,发现这些识别器还挺好用的。
于是Gatys套了个Gramian matrix上去算了一下那些不同局部特征的相关性,把它变成了一个统计模型,于是就有了一个不用手工建模就能生成纹理的方法。
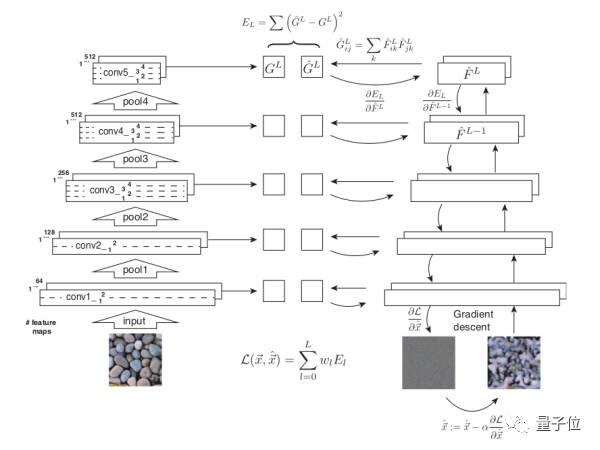 △ 基于神经网络的纹理生成算法
△ 基于神经网络的纹理生成算法
从纹理到图片风格其实只差两步。
第一步也是比较神奇的,是Gatys发现纹理能够描述一个图像的风格。严格来说文理只是图片风格的一部分,但是不仔细研究纹理和风格之间的区别的话,乍一看给人感觉还真差不多。第二步是如何只提取图片内容而不包括图片风格。
这两点就是他的第二篇论文做的事情:Gatys又偷了个懒,把物体识别模型再拿出来用了一遍,这次不拿Gramian算统计模型了,直接把局部特征看做近似的图片内容,这样就得到了一个把图片内容和图片风格(说白了就是纹理)分开的系统,剩下的就是把一个图片的内容和另一个图片的风格合起来。
合起来的方法用的正是之前提到的让神经网络“梦到”狗的方法,也就是研究员们玩出来的Deep Dream,找到能让合适的特征提取神经元被激活的图片即可。
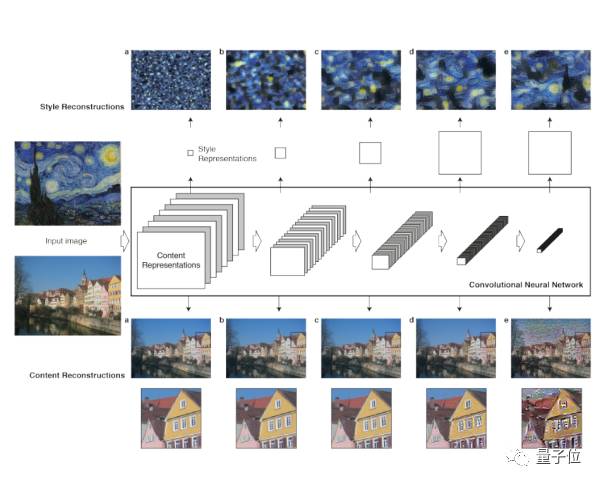 △ 基于神经网络的图像风格迁移
△ 基于神经网络的图像风格迁移
至此,我们就把关于基于神经网络的图像风格迁移(Neural Style)的重点解释清楚了。背后的每一步都是前人研究的结果,不用因为名字里带深度啊神经网络啊而感觉加了什么特技,特别的高级。
Gatys所做的改进是把两个不同领域的研究成果有机的结合了起来,做出了令人惊艳的结果。其实最让我惊讶的是纹理竟然能够和人们心目中认识到的图片的风格在很大程度上相吻合。(和真正的艺术风格有很大区别,但是看上去挺好看的。。。)从那之后对neural style的改进也层出不穷,在这里就先放一些图,技术细节暂且不表。
 △ 改进后的图像风格迁移算法,左:输入图像,中:改进前,右:改进后。生成时间:5-20分钟
△ 改进后的图像风格迁移算法,左:输入图像,中:改进前,右:改进后。生成时间:5-20分钟
 △ 多个预设风格的融合,生成时间:少于1秒,训练时间:每个风格1-10小时
△ 多个预设风格的融合,生成时间:少于1秒,训练时间:每个风格1-10小时
 △ 最新的实时任意风格迁移算法之一,生成时间:少于10秒(少于一秒的算法也有,但个人认为看上去没这个好看),训练时间:10小时
△ 最新的实时任意风格迁移算法之一,生成时间:少于10秒(少于一秒的算法也有,但个人认为看上去没这个好看),训练时间:10小时
 △ 图片类比,生成时间:5-20分钟
△ 图片类比,生成时间:5-20分钟
最后安利一篇与本文无关的文章吧,Research Debt 是我写本文的动机。希望各位喜欢本文,也希望有余力的人能多写一些科普文。文笔不好献丑了。
Research Debt 地址(英文):
https://distill.pub/2017/research-debt/
知乎相关问题地址:
https://www.zhihu.com/question/57639134
点击左下角“*阅读原文”,查看带参考文献的原文
也可解锁作者的更多文章~
【完】
交流沟通
量子位读者6群开启,对人工智能感兴趣的朋友,欢迎加量子位小助手的微信qbitbot2,申请入群,一起探讨AI。
想要更深一步的交流?
量子位还有自动驾驶、NLP、CV、机器学习等专业讨论群,仅接纳相应领域的一线工程师、研究人员等。
同样需要添加qbitbot2为微信好友,提交相应说明,符合条件后将被邀请入群。(审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者等岗位,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。
△ 扫码强行关注『量子位』
追踪人工智能领域最劲内容










