
雷锋网AI 科技评论按:苹果的新一期机器学习开发日记来了~ 这次苹果介绍了通过讲话就能唤醒Siri的“Hey Siri”功能是如何从技术上实现的,同时也介绍了为了从用户体验角度改善“Hey Siri”的表现,苹果的工程师们都做了哪些取舍和调整。与之前的文章一样,苹果的产品开发中并没有令人震惊的新技术,但严谨、细致、以用户为中心打磨产品的态度是自始至终的。雷锋网 AI 科技评论全文编译如下。
iOS设备上的“Hey Siri”功能可以让用户无需接触设备就唤醒Siri。在iOS设备上,有一个非常小的语音识别器一直在运行着,就等着听这两个词。当它检测到用户说“Hey Siri”后,Siri 其它的部分就会把接下来的语音分解成一个控制指令或者一次查询。“Hey Siri”检测器中使用了一个深度神经网络(DNN),每时每刻把你的语音模式转换成一个不同讲话声音的概率分布。它使用了一个时间积分的过程对听到的语音计算一个置信度分数,判断你说的词语是不是“Hey Siri”。如果这个分数足够高,Siri 就会醒来。这篇文章就简单介绍了其中蕴含的技术,它的主要目标读者是对机器学习有一些了解但是对语音识别了解不多的研究者们。
如果要让 Siri 做什么,只需说:“Hey Siri”。当说出“Hey Siri”时不需要按设备上的任何一个按钮,这使得 Siri 无需触碰就可以操作。这件事看起来简单,但是在幕后有许多的故事才能让 Siri 唤醒得又快又高效。硬件、软件和网络服务无缝共同合作,提供了出色的用户体验。

图1, Hey Siri 功能在 iPhone上的工作流程
在做饭或者开车这种双手很忙的时候,能够不按按钮就使用 Siri 显得尤其的有用,使用 Apple Watch时也是这样。如图1所示,整个系统包含许多组件。Siri 的大多数功能都是在云端实现的,包括主要的自动语音识别、自然语言转述以及各种丰富的信息服务。也有一些服务器会给手机中的检测器提供声学模型的更新。这篇文章重点介绍系统中运行在本地设备上的部分(比如iPhone或者Apple Watch上)。这篇文章尤其关注了检测器:一个专用的语音识别器,它始终在聆听,而且仅仅听它的唤醒短语(在较为近期的iPhone上,并开启了“Hey Siri”功能时)。
iPhone或者Apple Watch上的麦克风会把你的声音转化成一组短时的波形采样流,采样速率是每秒16000次。一个频谱分析阶段会把波形采样留转换成一组音频帧,每一个帧都描述了大概0.01秒的声音频谱。每次会有大约20个这样的帧(0.2秒长的音频)送入声学模型,这是一个深度神经网络,把音频样本中的每一个都转换成一组语言声音类别的概率分布:“Hey Siri”短语中用到的声音,或者静音和其它语音,加起来一共大约20个声音类别。详见图2。
这个深度神经网络主要由矩阵乘法和逻辑非线性组成。每一个隐含层的内容都是DNN经过训练后发掘出的中间层表征,最终把过滤器中每个频道的输入转换为不同的声音类别。最终的非线性阶段本质上是一个Softmax函数(也就是一个一般逻辑或者正则化指数函数),不过由于苹果的工程师们想要的是对数概率,所以实际的数学计算会比这个简单一点。

图2,用来检测“Hey Siri”的深度神经网络。其中的隐含层是全连接的。顶层进行的是一个时间集成的过程。实际的深度神经网络是图中虚线框圈出的部分。
不同的设备上运行“Hey Siri”时有不同的运算资源,苹果的工程师们据此为隐含层中的神经元设定不同的数目。苹果用的网络一般含有五个隐含层,每层都有同样的神经元数目,根据设备的内存和能源限制,数目为32、128或者192个。在iPhone上,苹果设计了两个网络,一个用于初始检测,另一个用于第二步检测。初始检测中的神经元数目比第二步检测中的少。
这个声学模型的输出是为每一帧计算语音类别的概率分布。一个语音类别可以是“前有一个舌位较高的前元音、后面有一个前元音的/s/发音的第一部分”这样的东西。
为了检测“Hey Siri”,这个目标短语的读音经过声学模型之后的输出应当在输出序列中靠前的位置上。为了给每一帧计算单独的分数,苹果工程师们按照时间顺序把这些局部的值累计在一个序列中。这部分就是图2中最终层(顶层)的部分,一个循环网络中带有到同一个神经元和下一个神经元的连接。在每个神经元中都有一个取最大值操作和一个加法操作。
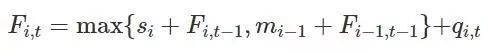
其中:
其中si和mi都是基于训练数据中语音分割时长和相关标签的分析得到的。(这个过程中应用了动态编程,而且可以由隐马尔可夫模型HMMs的思路得到)

图3,方程的可视化描述
每一个累计分数Fi,t都和前一帧带有状态的标签有关,正如一系列最大化操作结果中展示的那样。每一帧的最终分数是Fi,t,这个语音段落的最后一个状态是状态i,在帧序列中一共通过N帧得到了这个结果。(N可以通过回溯最大化操作的序列得到,但实际上的做法是向前传播帧的数目,因为这条路径进入的是语音段落的第一个状态)
“Hey Siri”检测器的计算几乎都是在这个声学模型中完成的。这个时间积分计算的代价还比较低,所以在评估模型大小或者计算资源的时候都不需要考虑它。
看看下面的图4,你应该能更好地理解这个检测器是如何工作的。其中在假设使用了最小的深度神经网络的情况下,不同阶段中声学信号是什么样的。在最下面是麦克风采集到的声音的频谱图。在这个例子中,有人在说“Hey Siri what”,其中较亮的部分是语音段落中最响亮的部分。“Hey Siri”声音的模式就是两条垂直线之间的部分。

图4,音频样本经过检测器之后的样子
倒数第二个横向图中是把同一段语音用Mel滤波器组分析后的结果,其中根据感知测量的结果给不同的频率赋予了权重。这个转换同时也让频谱图中能看到的细节变得更平滑,这是由于人声中激活特性的精细结构,要么是随机的,比如/s/中这样,或者是持续性的,体现为图中的竖向条纹。
图4中标注为H1到H5的绿色和蓝色的横条是5个隐含层中每个神经元的数值(激活状况)。这张图中每一层32个神经元经过了重新排列,让具有类似输出的神经元距离更近一些。
再网上的一个横条(带有黄色信号的)展示的是声学模型的输出。在每一帧中,语音段落中的每一个状态都会有一个输出,另外还有其它对应着静音或者其它语音声音的输出。最终的评分显示在最上方,是按照公式1,沿着发光的信号把每个局部的分数积分起来得到的。值得注意的是,一旦整个语音段落都输入了系统,这个最终评分就会达到最高点。
苹果的工程师们为最终评分设立了两个阈值来决定是否要激活Siri。实际上,阈值并不是固定的数值。苹果工程师们设定了一定的灵活性,在嘈杂的环境下更容易激活Siri,同时也不会显著增加误激活的次数。两个阈值中一个是主阈值,或者是普通阈值,还有一个较低的阈值,达到这个较低阈值并不会像正常那样启动Siri。如果最终评分达到了较低的阈值但是没有达到普通阈值,有可能确实是设备没有识别出用户说的“Hey Siri”。当评分在这个范围时,系统会进入一个更敏感的状态并保持几秒钟,这样如果用户重新说这句话,即便他没有说得更大声更清晰,Siri也会被唤醒。这种“二次机会”机制极大地提升了系统的可用性,同时还没有让误唤醒率提升多少,因为设备也只会在这个非常敏感的时间保持很短的时间(下文会更多地讨论准确率的测试和调节)
“Hey Siri”检测器不仅需要检测结果准确,还要在达到高识别速度的同时不造成明显的电量消耗。同时还需要尽量降低对内存和处理器的需求,尤其是对于处理器需求峰值。
为了避免让iPhone的主处理器全天运行就为了等待听到激活短语,iPhone 6S以及之后的iPhone上都搭载了一个 Always On Processor (持续工作处理器,AOP) ,这是一个小体积、低功耗的协处理器,也就是iPhone上内置的型号M开头的运动协处理器。它能够获取麦克风采集的信号。苹果的工程师们拿出了AOP中有限的计算资源的一小部分来运行一个“Hey Siri”检测器中的深度神经网络的缩小版本。当评分达到了一个阈值之后,运动协处理器会唤醒主处理器,主处理器就会用一个更大的深度神经网络分析声音信号。在第一个带有AOP支持的“Hey Siri”检测器版本中,前一个协处理器中的检测器中的5个隐含层每个隐含层有32个神经元,第二个主处理器中的检测器中的5个隐含层每个隐含层有192个神经元。

图5,两步检测
在Apple Watch上实现“Hey Siri”检测器的时候苹果工程师们遇到了更大的困难,因为它的电池要小得多。Apple Watch用的是一个一步检测的检测器,其中的声学模型大小介于刚才说到的其它iOS设备中第一步检测和第二步检测的模型大小之间。这个“Hey Siri”检测器只有当手表中的运动协处理器检测到手腕抬起动作的时候才开始工作,同时也会亮起屏幕。这时WatchOS其实要做许多的事情,唤醒电源、准备屏幕等等,整个系统只会在本来就非常有限的计算资源中分配给“Hey Siri”检测器很小的一部分(大概5%)。及时启动音频采集抓住激活词语是一项挑战,所以苹果也在检测器的初始化过程中预留了一些空间,允许出现一些断续。
一直开着的“Hey Siri”检测器可以对附近任何人说的激活短语做出响应,苹果的工程师们最初是这样设计的。为了减少误激活带来的麻烦,在iOS设备上打开“Hey Siri”功能后,用户需要进行一个简短的注册环节。在注册环节中,用户需要说五个以“Hey Siri”开头的短语,然后这些语音样本会被保存在设备上。
未来设备上录制到的任何“Hey Siri”语音都会和存储的样本做对比。(第二步)检测器会产生时间信息,可以把语音样本转换成一个固定长度的向量,这个过程中会把每一帧对齐到每个状态之后取平均。另外一个单独的、专门训练过的深度神经网络会把这个向量转换到一个“讲话者空间”中去。这个设计的想法是,同一个讲话者的语音样本会较为接近,不同讲话者之间的语音样本就会离得比较远。识别时,会把新语音和之前注册时录制的语音之间的距离和一个阈值进行对比,判断触发了检测器的这个声音有多大可能是来自注册过的用户的。
这个过程不仅降低了另一个用户说的“Hey Siri”会激活iPhone的可能,同时也降低了其它听起来接近的词语激活Siri的可能。
在通过iPhone上的层层识别阶段之后,这段语音会被传到Siri服务器上去。如果服务器上的主语音识别器认为说的内容并不是“Hey Siri”(比如其实说的是 “Hey Seriously”),服务器就会给手机发回一个取消信号,让它重新进入睡眠状态(图1中所示)。在有些系统中,苹果也会在本地设备上设置一个缩减版本的主语音识别器,在更早的时候提供多一步检查。
深度神经网络的声学模型是“Hey Siri”的核心所在。下面来详细看看它是如何训练的。早在推出“Hey Siri”功能之前,就有一小部分用户使用在Siri时在讲命令之前先说“Hey Siri”;这时候激活Siri都是靠按下按钮的。苹果的工程师们就使用了这些“Hey Siri”语音用作美国英语的检测模型的初始训练集。他们同时还用了一些一般的语音样本,就像训练主语音识别用到的那样。在这两种情况下,苹果都使用了训练短语的自动文本转录结果。Siri团队检查了这些转录结果中的一部分,确认正确率足够。
苹果为不同语言单独设计了“Hey Siri”短语的语音特征。以美国英语为例,系统中设计了两种变体,其中的“Siri”有两种不同的首元音,一个像“serious”中那样,另一个像“Syria”中那样。他们还考虑了如何应对这两个词中间的短暂间隔,尤其是这个短语书写的时候都经常会带上一个逗号变成“Hey,Siri”。每个语音符号都会被分为三种语音类别(开头,中部以及结尾),每一个在经过声学模型后都会得到各自的输出。
苹果使用了一个对话语料库来训练这个检测器的深度神经网络,同时Siri的主语音识别器会给每一帧提供一个声音类别标签。主声音检测器中有数千种声音类别,不过只有大约20种是检测“Hey Siri”的读音时用得到的(包括一个初始声音),然后把所有其它的声音都归为一个大类就可以。训练过程的目标是根据局部音频样本,让DNN对标识了相关的状态和音素的帧输出的判别结果尽量接近1。训练过程通过标准的反向传播和随机梯度下降调节连接权值。开发过程中,苹果使用了许多种不同的神经网络训练工具包,包括Theano、Tensorflow 以及 Kaldi。
训练过程中根据给定的局部声学样本估计音素和状态的概率,但是这些估计值中会包括音素在训练集中的出现概率(首选),它们的分布可能不均匀,而且也和检测器的实际应用场景关系不大,所以苹果工程师们在应用声学模型之前先对这些首选做了补偿。
训练一个模型通常需要花一天的时间,苹果通常也会同步训练好几个模型。一般一次会训练三个版本,一个小模型用在运动协处理器的第一步检测上,一个大模型用在主处理器的第二步检测上,以及一个中等大小的模型用于Apple Watch。
“Hey Siri” 功能可以支持所有Siri支持的语言,不过让Siri开始聆听的指令不一定非要是“Hey Siri” 这两个词。比如,讲法语的用户需要说 “Dis Siri”,讲韩语的用户说“Siri 야”(发音类似“Siri Ya.”)在俄罗斯,用户要说“привет Siri “ (听起来像“Privet Siri”),在泰国就是“หวัดดี Siri”.(听起来像“Wadi Siri”)。
无论用户在什么时候说“Hey Siri”,一个理想的检测器都应该马上启动起来,同时不在其它的时候启动。苹果用两种不同的错误描述检测器的准确率,一个是在错误的时候启动,一个是没能在正确的时候启动。前者是错误接受率(FAR或误警率),是每小时平均误启动的数目(或者是误启动之间的平均间隔时间);后者错误拒绝率(FRR)是尝试激活Siri的动作中失败的比例。(值得注意的是,用来衡量FAR的单位和衡量FRR的不一样,甚至测量的指标都不一样。所以不存在FAR和FRR相等的状况)
对于一个给定的声学模型,可以在两种错误率中做平衡取舍,改变激活的阈值就可以。图6中表现的就是在两个开发早期的模型基础上做这种取舍的例子,做的操作就是沿着曲线改变阈值。
在开发过程中,苹果的工程师们尝试用一个很大的测试集估计系统的准确率,这样的测试集采集和准备起来很花钱,但却是必不可少的。测试集中有正例数据也有负例数据。正例数据中确实含有目标激活词语。你可能会想,用“Hey Siri”系统本来采集到的声音来做测试不行吗?但其实系统并没有捕捉到没能激活Siri的那些语音,而苹果的目标是提升系统表现,尽量让以前激活失败的声音在现在可以激活成功。
一开始苹果使用了一些用户在按下Home按钮同时说的“Hey Siri”语音,但是其实这些用户并没有试着让Siri集中注意力听他们说什么(按下Home按钮的动作就已经表达了这个意图),而且同时麦克风也一定是在用户的一臂距离之内。相比之下,苹果希望“Hey Siri”可以在整个房间的范围内都有效。所以苹果专门根据不同的环境录制了很多语音,比如在厨房(远近都有)、车上、卧室、餐馆;苹果分别请了把各种语言做母语的人参与这项录制。
负例数据是用来测试误激活(以及误唤醒)的。数据集中有不同来源的共数千小时录音,包括语音博客和Siri收到的各种语言语音中不含有“Hey Siri”的那些,它们分别代表了背景声音(尤其是人类对话)和用户跟另一个人讲话时容易出现的词语。苹果需要准备大量的数据,因为他们的目标误激活率要低至每周一次(如果在标识为负例的数据中确实出现了激活词语,这样的情况就不算为出错)

图6,检测器准确率。较小和较大的深度神经网络中对检出的阈值有不同取舍
系统的调节在很大程度上就是一个决定用什么阈值的过程。图6中,较大的深度神经网络的那条较低的权衡曲线上的两个点,就是选出的正常阈值和“再说一次”的阈值。较小的模型(一步检测)的工作点在最右侧。图中的曲线展示的仅仅是检测器中两个阶段的检出率曲线,并未包括之后的个性化阶段或者后续检查。
对于在测试集上表现较好的模型,苹果的工程师们当然有信心认为它们确实更优秀,但把离线测试的结果转换成对用户体验的靠谱的预测就是另一件事情了。所以除了刚刚介绍的离线测试之外,苹果还从最新的iOS设备和Apple Watch上对生产数据(用户真实使用状况下的数据)进行了每周采样,用来估计误识别率(用户没有说“Hey Siri”的时候Siri就启动了)和冒名接受率(检测器已经经过了用户语音的训练,但是另一个人说“Hey Siri”的时候Siri也启动了)。这些数据中并不能得到拒绝率(用户说了“Hey Siri”但Siri并没有应答),但是这个指标可以由系统开发人员从刚好高出阈值的真实激活动作的比例,以及设备上记录的刚好未达到阈值的事件次数中推测出来。
苹果的工程师们用这篇文章中介绍的训练和测试方法以及它们的变种,不断评估、改进着“Hey Siri”功能以及在背后支持着功能的模型。训练中总是包含了各种不同的语言,测试中也总是考虑了各种变化的条件。
下次你再对手机说出“Hey Siri”的时候,你可能会想起苹果工程师们为了能应答这个短语而做的所有这一切,但苹果工程师更希望的是你能觉得“it just works"!
via Apple Machine Learning Journal,雷锋网 AI 科技评论编译











