
在今年11月中旬举办的“2016年超算大会上”,FPGA大厂Xilinx发布了可重配置加速栈(ReconfigurableAcceleration Stack)。配合可重构的FPGA,这个架构能解决可重构计算中的编程困难问题,并加速可重构计算生态的建设。
日前,Amazon云服务AWS更是基于Xilinx高端Ultrascale+ FPGA推出了使用在云端的FPGA解决方案。众多巨头的参与,让诞生几十年的可重构计算再度成为业界关注的焦点。但是你真的懂得可重构计算吗?
可重构计算的起源
自从计算机诞生以来,科学家们就意识到计算机架构对于其处理能力有着至关重要的影响。事实上,从来不存在一种对所有运算任务都是最优解的计算机架构。这是因为计算机的运算单元由芯片构成,而在芯片的面积固定的情况下计算机架构就决定了如何分配芯片的资源。
举例来说,机器学习应用(尤其是CNN)会比较注重并行运算,因此最适合的架构是能处理并行运算的多核架构,而每个核的运算能力并不需要特别强。另一方面,在一些科学及工业运算上,计算是无法并行执行的,于是最适合的架构是单核架构并把这个核做到非常强。
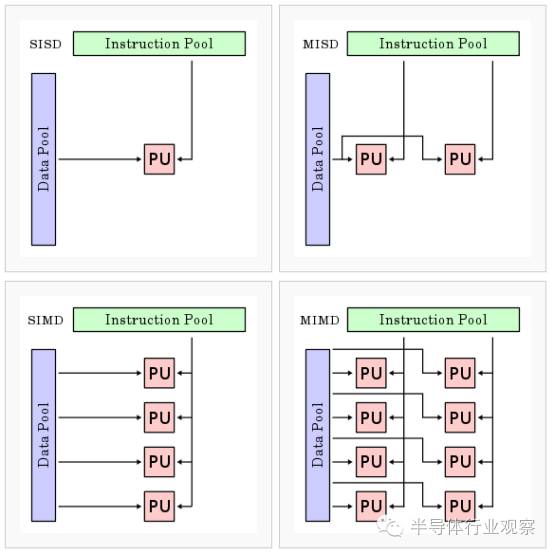
根据数据和指令的执行方式,60年代著名的计算机科学家
Flynn
提出了架构的分类方法,一共有单指令流单数据流(
SISD
),单指令流多数据流(
SIMD
),多指令流单数据流(
MISD
)以及多指令流多数据流(
MIMD
)四种。
正是由于对于不同的任务有最合适的架构,计算机科学家们开始构思如何使用一种灵活的架构解决这个问题。可重构运算(reconfigurable computing)从上世纪
60
年代由
Gerald Estrin
提出,到现在已经经历了半个世纪。
在
Estrin
最初的设想中,可重构运算包括一个作为中央控制单元的标准
CPU
,以及众多可重构的运算单元,这些可重构运算单元由中央
CPU
控制,在执行相应任务(如图像处理,模式识别,科学运算等等)时配置成对应的最优架构(即硬件编程)。
在理论上这个构想非常成功:
2001
年,
Reiner Hartenstein
的论文中提到,即使可重构运算使用的运算单元(
FPGA
)时钟频率远低于当时的
CPU
,但是可重构计算的综合运算能力却可以超越
CPU
数倍,而功耗也远小于
CPU
。
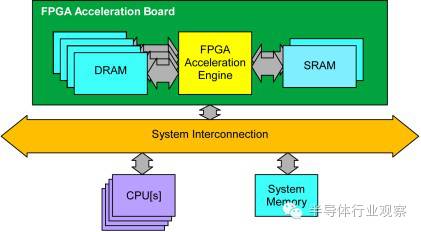
可重构计算的例子(使用FPGA作为可重构计算单元)
然而,可重构运算在当时并没有普及。从可重构运算提出直到二十一世纪初的40年正是摩尔定律的黄金时期,工艺一年半就更新一次,因此架构上更新带来的性能增强可能还不如工艺更新来得强。
当时最流行的就是靠摩尔定律狂飙突进来实现处理器运算能力的进化,因此与旧架构相差很大的可重构运算并未得到重视:花五年时间研发的可重构计算芯片很可能性能还不及依靠摩尔定律提升性能的传统架构
CPU
。
同时,由摩尔定律带来的
CPU
性能增长完全可以满足当时运算的需求。因此当时可重构运算还只是停留在学术圈子里的精致理论,业界推广的动力并不大。
另一个可重构运算普及的障碍是使用难度。传统CPU上编程使用抽象的高级语言(如
C++
,
Java
等等)描述,已经有成熟的体系。然而可重构计算需要的硬件编程通常使用硬件描述语言(
Verilog
,
VHDL
等等),对于程序员来说需要大量的时间才能掌握。
这样的话可重构计算的生态就无法发展:门槛高意味着做的人少,做的人少意味着知名度低,相关项目数量少,这又导致了无法吸引到开发者参与项目。
异构计算与可重构计算
在今天,摩尔定律遇到了瓶颈,因此可重构计算普及的第一个障碍正在慢慢消失。摩尔定律的瓶颈第一来自于经济学,第二来自于物理定律。从经济学的角度,本来摩尔定律的目标就是通过工艺制程进步缩小特征尺寸让相同功能的芯片需要的晶圆面积更小。工艺制程进步所需的研发成本和mask制作的
NRE
成本上升,而每块芯片的制造成本下降
。在之前的几十年里,工艺制程研发成本和
mask
制作的
NRE
成本上升平摊到每块芯片中不会抵消太多芯片制造成本的下降,从而使用新工艺的芯片的总成本相对于旧工艺会下降。然而,在最新的工艺中,由于新工艺的
mask NRE
成本非常高,生产的芯片必须出货量非常大才能保证摊薄
NRE
成本上升,这对于很多芯片设计公司来说风险很大。因此经济学角度对于摩尔定律的驱动力大大下降了。
从物理学角度来说,障碍主要来源于量子效应和光刻精度。当特征尺寸缩小到
10nm
的时候,栅氧化层的厚度仅仅只有十个原子那么厚,在那个时候会产生诸多量子效应,导致晶体管的特性难以控制。
另一方面,随着大数据时代的来临,整个社会产生的运算需求迅猛增加。这一点与摩尔定律遇到的瓶颈此消彼长,导致计算机以及半导体行业不得不停下来仔细思考在除了继续无脑改进CPU制造工艺之外,还有没有其他满足运算需求的办法。
很自然地,大家想到了计算机架构这件事。目前在云端的计算五花八门,包括机器学习,数据库,图像处理,金融运算等等。为什么运算能力不足?因为大家都想要图方便,只用通用的
CPU
来处理所有的任务。
前面已经提到,
CPU
的架构并不适合所有任务,只是因为在大数据时代来临前
CPU
性能够强而且编程够方便所以大家也没有想要试试其他的架构(当然在图形加速方面用的是
GPU
,不过类似的例子并不普遍)。今天,显然光
CPU
已经不足以满足所有运算的需求了,所以可以根据相应的任务来设计专用加速器,计算机由
CPU
控制并在执行该任务时把相应的运算丢给加速器来完成。
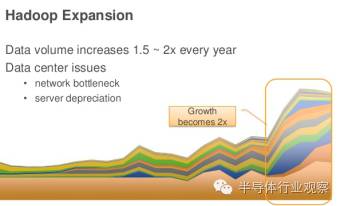
大数据时代的数据量以指数上升(上图),而摩尔定律却遇到了瓶颈(下图),晶体管性能增长有限
这样的架构叫做
异构计算
,即用各种不同的的运算单元去完成相应的任务,区别于传统的用同一个运算单元(
CPU
)去完成所有运算。
异构计算比起可重构计算来说,由于加速器的结构是实现定义好的,因此无需使用者(程序员)再次用硬件语言去配置它,所以普及起来比起可重构计算要容易不少。然而,异构计算也存在一个问题:如果使用者需要临时换一个应用,怎么办?临时安装对应的加速卡很难满足需求,因为加速卡从订购,安装调试到最后能用需要很长的时间,换句话说,异构计算的灵活性是受到限制的。
从另一个角度来说,如果可重构计算能够突破编程困难这个瓶颈,那么在大数据时代一定会成为计算机的重要部分。为了解决编程困难问题,目前业界和学界都在开发能把高级语言(如
C
语言)直接转化为硬件的高级综合(
high-level synthesis tool
)工具。除此以外,
OpenCL
框架也是让程序员直接编程硬件的可行道路。但是,直到最近,可重构计算的生态还没有起来。
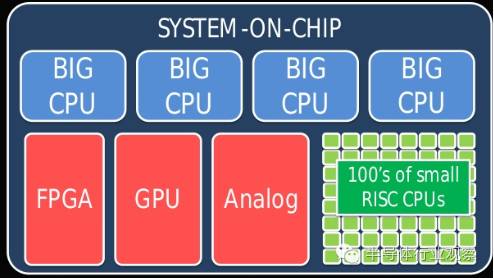
异构计算架构示例
大数据时代可重构计算开始发力
近日,可重构计算进入了超级计算机业界的焦点,Intel收购
FPGA
制造商
Altera
,并且预期到
2020
年将会有三分之一的云端处理器使用
CPU-FPGA
的混合结构。
FPGA
巨头
Xilinx
也不甘落后,于
11
月中旬在
2016
年超算大会上发布了可重配置加速栈(
Reconfigurable Acceleration Stack
)。配合可重构的
FPGA
,该架构旨在解决可重构计算中的编程困难问题,并加速可重构计算生态的建设。
在可重配置加速栈中,
Xilinx
提供了几款流行应用框架的整合,包括
Caffe
(深度学习应用),
FFMPEG
(视频处理)以及
SQL
(数据库)。通过这样的整合,云端服务器的程序员无需使用
Verilog/VHDL
硬件描述语言就可以在可重配置加速栈中使用
FPGA
资源加速这些框架中的应用。除此之外,
Xilinx
还提供了各种库,通过在程序中调用这些库也可以实现更灵活地用
FPGA
硬件加速程序。
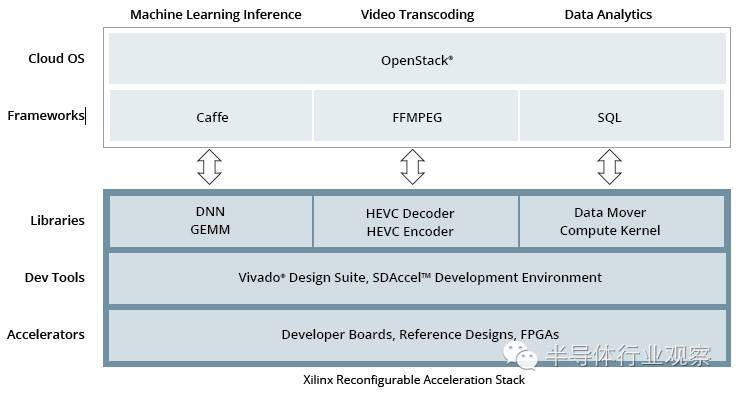
Xilinx推出的
Reconfigurable Acceleration Stack
这些用于云端的FPGA将会使用部分重配置方案。通常
FPGA
配置过程包括硬件描述语言的综合,布局布线,最后产生比特流文件并写入以完成配置。在这个过程中,综合以及布局布线花费的时间非常长,可达数小时,而最后比特流文件写入以及配置可以在一秒内完成。
用于云端的
FPGA
方案为了实现快速应用切换,预计将会使用硬
IP
(即针对某应用硬件加速的比特流),并在需要使用该应用时快速写入该比特流。在未来,云端
FPGA
的生态预计将不止包括
Xilinx
,还会包括许多第三方
IP
提供商,最后形成类似
App Store
的形式让使用者方便地选购对应的硬件加速方案并实时加载
/
切换。
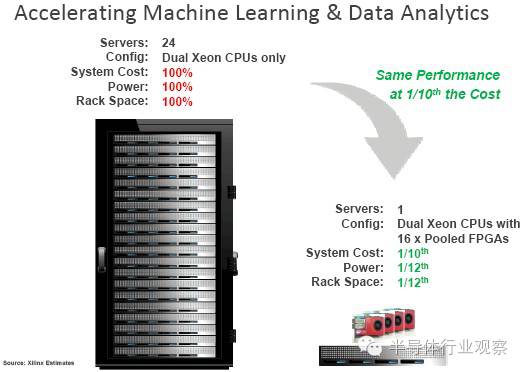
Xilinx FPGA硬件也很强,可以非常高效地实现各种计算。例如,实现相同的性能,使用
FPGA
加速器仅需要
CPU
服务器所占空间的
1/12
, 功耗为
CPU
服务器的
1/12
,而成本也仅为
CPU
服务器的
1/10
。
在云服务商这边,Amazon云服务也于近日推出了使用在云端的
FPGA
解决方案:
EC2 F1
。该解决方案使用
Xilinx
的高端
Ultrascale+ FPGA
(包含
250
万逻辑单元以及
6800









