编者按:
人工智能领域的顶级会议、第32届国际人工智能协会年会(AAAI 2018)于当地时间2018年2
月2日-2月7日在美国新奥尔良(New Orleans)举行。微软亚洲研究院自然语言计算组的实习生闫昭和张志锐均参加了此次大会,并撰文分享了本次大会的一些亮点,以及自己发表在AAAI 2018上的两篇论文内容。想知道本届大会有哪些精彩之处吗?和我们一起来看看吧。
AAAI 2018
会议期间正值新奥尔良市一年一度最盛大的
Mardi Gras
狂欢节举办之时。在节日期间,整座城市被黄绿紫三种颜色所装扮,每天都有盛大的游行队伍经过。热闹的城市氛围给我们带来了轻松欢快的参会心情。

本次大会共计收到
3808
篇有效投稿,相对于去年投稿量增加了
47%
,最终录取了
938
篇,录取率约为
24.6%
。
AAAI
会议是人工智能领域的综合性会议,收到的稿件涉及人工智能的各个主要方向。下图显示了今年
AAAI
会议投稿比较集中的几个领域,可以看出当前人工智能领域研究的热点依然集中在机器学习、计算机视觉、
NLP
、博弈论等。
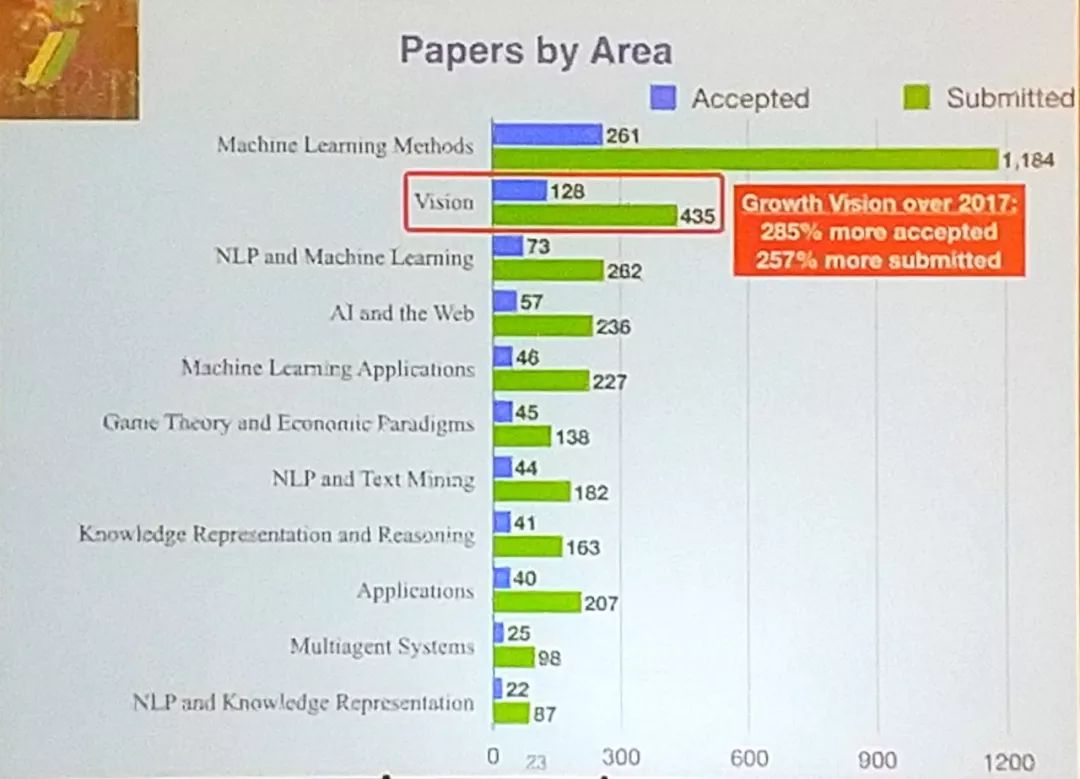
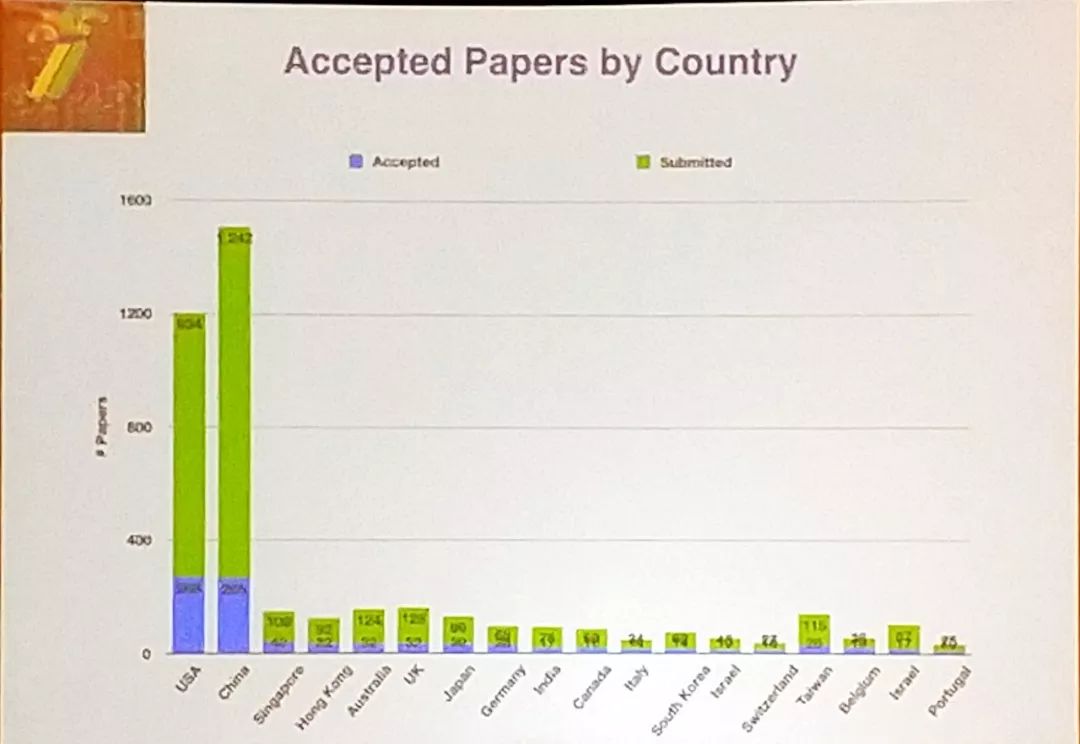
值得一提的是,来自中国的论文数量出现爆炸式增长,提交论文数量实现了
58%
的惊人提升,当仁不让领跑全球,录用数和美国平分秋色。此外,中外科研人员合作撰写的论文占比也非常高。这一数据也反应出目前中国人工智能领域的科研实力。

精彩纷呈的AAAI 2018
大会主要包括四大部分——为期
2
天的讲习班(
Tutorials)
和研讨会(
Workshops)
、
4
天的大会会议(
Technical Program)
和穿插其中的特邀报告(
Invited Talks)
。
大会前两天的议程包括了
26
场讲习班和
15
场研讨会,其中有两场讲习班是由微软的研究员和工程师带来的,包括
“Scalable Deep Learning Using CNTK”
和
“Machine Reading for Precision Medicine”
。研讨会的话题涵盖了诸多当前人工智能领域的热门话题,比如面向人机对话的推理与学习(
Reasoning and Learning for Human-Machine Dialogues)
、面向健康领域的智能(
Health
Intelligence)
、不完全信息游戏中的人工智能(
AI for Imperfect-Information Games)
等。
2月4日,AAAI协会主席Subbarao Kambhampati (Rao)发表了题为 “Challenges of Human-Aware AI Systems”的主旨演讲。在演讲中,Rao认为AI系统的发展应该更加关注与人类相互协作的功能,提出了几个相关的挑战,包括交互过程中人的心理状态的建模、AI在不完整的领域模型下如何进行决策、如何评估人机交互的有效性等。Rao教授是一个
非常幽默且开朗的研究人员,在演讲过程中经常用一些比较幽默的例子进行阐述。值得一提的是,Rao曾于去年到访中国并参加了CCF-GAIR会议,他是“AI威胁论”的坚定反对者,认为人与机器是可以和谐相处的。
会议的正式环节按照主题的不同分成了不同的
session
,由各个论文的作者进行论文的报告并回答听众的问题,
4
号至
6
号每天晚上都安排了海报展示与交流环节。会议的整体学术交流氛围浓厚,无论是在中场休息还是海报环节,随处可见讨论的人。
不同于往届会议,本次大会设立了一个新兴课题环节来探讨人工智能下一阶段的发展方向。过去
AI
系统已经在人类感知(语音识别、图像识别),学习(机器学习)和定义明确的推理任务(自然语言处理,例如机器翻译、阅读理解等)上取得了很大的进展,但这些进步更多是在单一的任务上,往往没有人类的参与。
正如Rao所呼吁的,随着人工智能技术越来越多地应用在我们的日常生活中,未来AI系统必然更需要与人类一起协作的能力。
这次大会将人类和
AI
系统的协作
“Human-AI Collaboration”
列为新兴课题,并组织了
4
个特邀报告和
21
个技术报告。这些报告对于
AI
系统和人类的协作在多个方向上进行探讨和研究,比如康奈尔大学
Ross Knepper
副教授的讲座
“Communicative Actions in Human-Robot Teams”
探讨了一种机器人理解和生成信息的新框架,从而使机器人能更清晰而简洁地与人类沟通,华盛顿大学
Matthew Taylor
教授的讲座
“Improving Reinforcement Learning with Human Input”
探讨如何扩展交互式机器学习,以最大限度地利用计算机和人类独特的能力,从而提升强化学习。
此外,
AAAI 2018
延续了往年的传统,为参会学生举办了多场特别活动,包括招聘会(
Job Fair
)和博士联合会(
Doctoral Consortium
)等。值得一提的是,国内多家企业包括百度、阿里、腾讯、滴滴、京东等业内顶尖公司均有较大规模的团队参加招聘会,这从侧面反映了国内企业对于
AI
人才的渴望。
微软亚洲研究院AAAI 2018
微软亚洲研究院在
AAAI 2018
上发表了多篇论文,可谓收获颇丰。这些论文也涉及人工智能的各个不同方向,包括机器阅读理解、聊天机器人、对话系统、机器学习等。
接下来,我们为大家介绍其中的两篇论文:
Assertion-based QA with Question-Aware Open Information Extraction
论文链接:https://arxiv.org/abs/1801.07414
这篇论文研究的是以包含
一定结构的断言(
assertion
)为粒度的自动问答任务
。与以句子为答案和以文本片段(
span
)为答案的问答任务相比,以包含
SPO
结构的断言作为答案更加适合语音交互场景。并且,从文档中抽取的断言集合可以为构建动态的知识图谱并进行问题推理提供更多的可能性。这项工作首先构建了一个包含
5
万多个问题、
35
万多条断言的数据集,然后进一步提出了抽取式和生成式两种答案生成方法。抽取式方法先使用基于模板的开放式关系抽取工具抽取断言候选,然后通过排序学习技术,对所有问题
-
断言对进行排序,选出最恰当的断言作为答案。生成式方法基于编码
-
解码架构,通过在编码层同时整合问题与证据文档信息,并将解码层拆解成
“
域
-
词
”
两级,使模型可以生成与问题相关的带有层次结构的断言。通过实验,我们不仅验证了所提出方法的有效性,还证明了所抽取的断言可以辅助其它问答任务。

图:Assertion-based QA任务与其它相关任务间的关系
Joint Training for Neural Machine Translation Models with Monolingual Data
论文链接:https://arxiv.org/abs/1803.00353
这一工作提出了一种新的联合训练方法——利用源语言和目标语言的单语数据去同时提升源语言到目标语言(正向)和目标语言到源语言(反向)的神经机器翻译模型。具体来讲,先用双语数据预训练正向和反向的翻译模型,然后用这两个模型分别去翻译源语言和目标语言的单语数据来构造伪双语数据,其中由源语言单语数据构造的伪双语数据用来提升反向翻译模型,而由目标语言单语数据构造的伪双语数据则用来提升正向翻译模型。接着新的正向和反向翻译模型重新对单语数据进行解码,并生成更高质量的伪双语数据,然后新的伪双语数据用来生成性能更好的正反向翻译模型。这个过程不断重复直至开发数据集上的翻译性能不再提高为止。
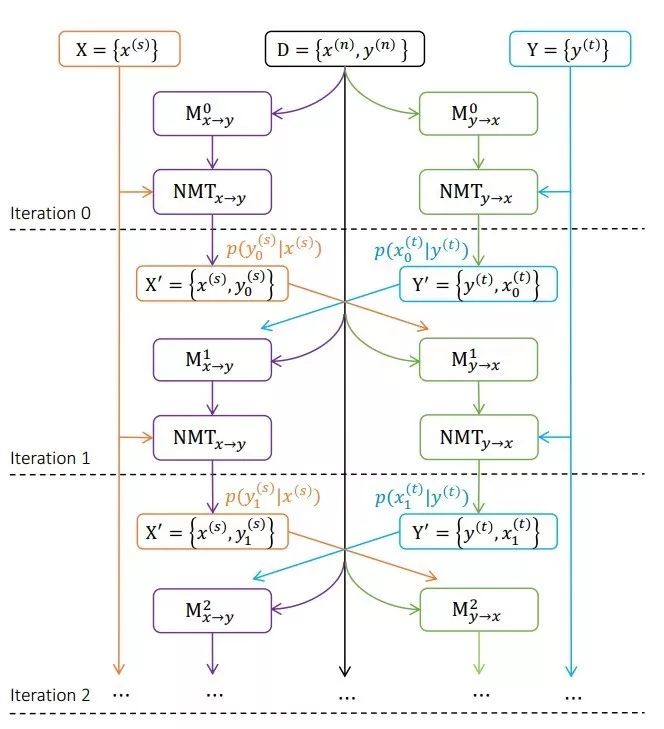
图:正反方向翻译模型的联合训练过程
通过在中英和英德翻译任务上的实验,我们验证了所提出的方法不仅能同时提高正向和反向模型的翻译性能,还明显优于其它基准方法。
参与AAAI大会的经历让我们收获很大,不仅认识了很多新的小伙伴,还锻炼了自己演讲的能力,也从各种学术讲座中学到了很多新知识。另外非常感谢微软亚洲研究院里的导师和同学们一直以来的支持和帮助。很期待能和大家一起继续努力,做出更加有影响力的工作。

闫昭,微软亚洲研究院自然语言计算组的实习生,就读于北京航空航天大学。研究兴趣包括对话系统、问答系统、聊天机器人等。








