大数据文摘作品,转载要求见文末
编译 | 徐宇文,蒋晔、范玥灿
卞峥,yawei xia
技术早已成为金融业的一项资产:金融交易的高速、高频与超大数据体量结合,促使金融机构在一年一年不断地加深对技术的关注,在今天,技术已经切实成为了金融界的一项主导能力。
在金融界最受欢迎的编程语言中,你会看到R和Python,与C++,C#和Java这些语言并列。在本教程中,你将开始学习如何在金融场景下运用Python。本教程涵盖以下这些方面:
基础知识:对于金融入门阶段的读者,你将会首先学到股票和交易策略,什么是时间序列数据,以及如何建立自己的工作空间等等。
时间序列数据和一些最为常见的金融分析的简介,例如滑动时间窗口、波动率计算等等在Python工具包Pandas中的实现。
一个简单的动量交易策略的开发:你将首先按部就班地过一遍开发流程,然后从公式化建立和编写简单的程序化交易策略着手。
紧接着,你将会使用Pandas,zipline和Quantopian对已构建的交易策略进行回测。
而后,你将会看到如何优化你的策略,以及最终你要对策略的表现以及稳健性进行评估。

从这里下载本教程的Jupyter notebook(https://github.com/Kacawi/datacamp-community)
在进入任何交易策略之前,首先摸清基础知识脉络是有帮助的。本教程的第一部分将会专注于解释你需要了解的Python基础知识。然而,这并不意味着你应该完全从零开始:你应该至少学过DataCamp上的Intro to Python for Data Science (https://www.datacamp.com/courses/intro-to-python-for-data-science)免费课程,从中你会学到如何使用Python列表,工具包以及NumPy。此外,你最好已经了解Pandas这个广为流传的Python数据操作工具包,不过这不是必须的。如果你确实希望在学习本教程之前就已经熟知Pandas,你可以考虑学习一下DataCamp上的Pandas Foundations (https://www.datacamp.com/courses/pandas-foundations)课程。
当一家公司希望实现增长、从事新项目或者扩张,它可以通过发行股票来提高资产水平。一股代表着对公司的一部分所有权,并通过金钱交易的形式发行。股票被买进和卖出:买方和卖方交易那些现存的、先前发行的股权。股票卖出的价格变化可以独立于公司经营的成功与否:股票价格反映的是供需关系。这意味着,无论何时,无论是基于成功、还是受欢迎等原因,如果一支股票被认为是抢手的,它的股价就会上涨。
注意,股票并非完全与债券等同,债券是公司通过借贷的方式进行融资的凭证,可能是从银行贷款,或是发行债务。
如前所述, 当谈及股票时,买入、卖出或者交易是非常必要的,但显然并不局限于此:交易是资产买卖的行为,既可以是财政担保,例如股票、债券;亦或者有形产品,例如金子和石油。
股票交易是一个现金交易过程,即用于购买股票而支出的现金转化为对一家公司的一部分所有权,这部分所有权能够通过出售股票的形式转化回现金,并且你有希望从中盈利。现在,为了获得丰厚的利润回报,你可以选择长期或短期的市场策略:你可能会因为认为股票价格会走高而购入股票,以期在未来以更高的价格售出,你也可能卖出股票,认为将来可以以更低的价格重新买入,以实现盈利。当你遵循一种固定的方式来选择长期或短期市场策略的时候,你就已经有了一个交易策略。
开发交易策略是一件需要经过好几个阶段的事情,就比如,当你在建立机器学习模型的时候:你首先构建一个策略,将它具体化成一种可以在你的电脑上测试的形式,你进行初步检验和回测,优化你的策略,最后,你需要评估策略的表现和稳健性。
交易策略通常通过回测来验证:利用历史数据,利用你已开发的交易策略重新构建那些过去应该发生的交易。借此,你能获知你的策略的有效性如何,你也可以以此作为新策略投入市场前的优化和提升的起始点。当然,这一切都在很大程度上依赖于一个根本性的理论或者说信仰,那就是任何在过去表现良好的策略也将在未来继续表现良好,以及,任何在过去表现不好的策略在未来也将会表现很差。
一个时间序列指的是一个在时间维度依次均匀分布的有序的数值数据点。在投资领域,时间序列追踪一些特定的数据点在特定时间段的变动,例如股票价格,这些数据基于正则区间进行记录。如果你仍然对这到底是长什么样子的心存疑问,那么请看一下下面的例子: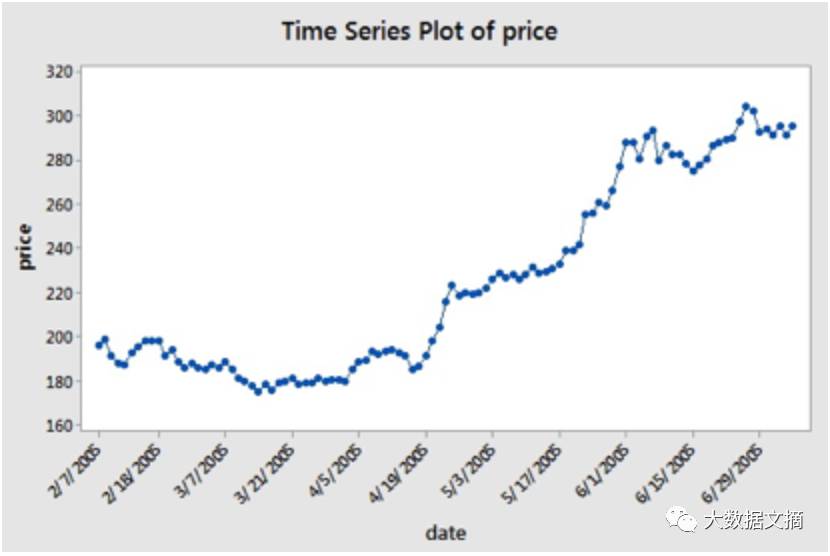 你可以看到日期被置于x轴,价格标注于y轴。所谓“在时间维度依次均匀分布”在这个例子中就是指日期在x轴上以14天的间隔均匀分布:请注意3/7/2005和下一个点3/31/2005的间隔,以及4/5/2005 和 4/19/2005的间隔。
你可以看到日期被置于x轴,价格标注于y轴。所谓“在时间维度依次均匀分布”在这个例子中就是指日期在x轴上以14天的间隔均匀分布:请注意3/7/2005和下一个点3/31/2005的间隔,以及4/5/2005 和 4/19/2005的间隔。
然而,你在处理股票数据的时候可能经常会发现的是,数据并不只有两个包含了时间和价格的列,而是更常见的是,你会有5个列分别包含了在这段时间内的时间期间、开盘、最高、最低以及收盘价。这意味着,如果你的周期被设置为每日更新,一天的所有记录就能告诉你这一天内任何一支股票的开盘和收盘价以及极高和极低波动值。
现在,你已经对学习本教程所需要掌握的基本概念具备了基本的认知,这些概念将会很快再次出现,而你将会在这份教程中对他们了解更多。
准备你的工作环境是一件简单的事:你基本只需要确保你的系统上有Python和IDE。然而,你有多种方法可以着手准备,而其中一些可能会稍微更简单一些。
举个例子,Anaconda是一个Python和R的高性能分布工作空间,并且包含了100多个最受欢迎的Python、R和Scala数据科学工具包。此外,安装了Anaconda你就可以通过conda获取超过720个工具包,以及我们在Anaconda种配置的最新的工具包、从属工具和环境管理工具。以及,除此之外,你还能通过它获取 Jupyter Notebook 和 Spyder IDE。
听起来像是工作量很大,对吗?
你可以从这里安装Anaconda,也别忘了从DataCamp的Jupyter Notebook教程 Jupyter NotebookTutorial: The Definitive Guide中查看如何建立你的Jupyter Notebook。
显然,Anaconda并不是你唯一的选项:你还可以看一下Canopy Python distribution (https://www.enthought.com/products/canopy/)(收费), 或者试试Quant Platform(http://quant-platform.com/)。
在使用比如Jupyter或Spyder IDE的基础上,后者提供了一些额外的好处, 因为它还为你提供了在浏览器上进行金融分析所需的一切!通过Quant平台,你将会获取基于GUI的金融工程的、可交互的和基于Python的金融分析以及你自有的基于Python的分析工具库。此外,你还可以进入一个论坛来跟你的同行一起探讨解决方案和疑问。

当你在金融中使用Python的时候,你将会经常用到数据操作工具包,Pandas。但你也会用到其他的工具包例如NumPy,SciPy,Matplotlib等等,它们将会在你一旦深入的时候出现。
现在,让我们先关注在Pandas上,并且用它来分析时间序列数据。这一部分将会解释你可以怎样使用Pandas输入数据,探索和操作数据。在这之上,你还会学到如何对你输入的数据进行一些常见的金融分析。pandas-datareader 工具包让你可以从Google,Yahoo! 金融和世界银行等渠道读入数据。如果你想要获得更新版的这项功能所能触及的数据源列表,可以去看一下文档。这个教程中,我们将会使用这个工具包从Yahoo! 金融上读入数据。
注意,Yahoo API 的终端最近有所变动,而且如果你已经想要开始自己使用这个工具库了,你需要安装一个暂时的补丁来利用pandas-datareader从Yahoo金融抓取数据,直到正式的补丁完善。在开始之前,请确保阅读了这份说明。
当然,请别担心,在这份教程中,我们已经为你载入了数据,所以在学习如何在金融中通过Pandas使用Python的时候,你不会面对任何问题。聪明的思考角度是,虽然pandas-datareader提供了大量抓取数据的选项,它仍然不是唯一选项:例如,你还可以利用像Quandl这样的其它的工具库从Google金融获取数据。
关于如何使用Quandl直接抓取金融数据的更多信息,请参见这个网页。
最后,如果你已经在金融行业工作了一段时间,你可能知道最常用于数据操作的工具是Excel。因此,你需要知道如何将Python和Excel整合到一起。
更多信息请查看DataCamp的Python Excel Tutorial:The Definitive Guide 。
当你终于在工作空间中获得数据以后,你要做的第一件事就是赶紧上手。然而,既然你现在对付的是时间序列数据,这看起来便可能不是很直接了,因为你的行标签中带有了时间值。
但是,请别担心!让我们首先按部就班地利用一些函数开始探索数据,如果你先前已经有了一些R的编程经验,或者你已经使用过Pandas, 你可能已经对这些函数有所了解了。
无论哪种情况,你都会觉得这非常简单!
正如你在下面的代码中看到的,你已经用过pandas_datareader来输入数据到工作空间中,得到的对象aapl是一个数据框(DataFrame),也就是一个二维带标记的数据结构,它的每一列都有可能是不同的数据类型。现在,当你手头有一个规则的数据框的时候,你可能首先要做的事情之一就是利用head() 和tail() 函数窥视一下数据框的第一和最后一行。幸运的是,当你处理时间序列数据的时候,这一点是不变的。
小贴士:也可以利用describe() 函数来获取一些有用的总结性统计数据
请从这里找到一些附带的练习
正如你在介绍部分所看到的,数据清楚地包含了四个列,包括苹果的股票每天的开盘价和收盘价,和极高和极低的价格变动。此外,你还得到了两个额外的列:Volume 和Adj Close。前一个列是用来记录在这一天内交易的股权总量。后者则是调整的收盘价格:当天的收盘价格经过细微的调整以适应在后一天开盘前所发生的任何操作。你可以使用这一个列来检验历史回报或者对历史回报做一些细致的分析。
前一个列是用来记录在这一天内交易的股权总量。后者则是调整的收盘价格:当天的收盘价格经过细微的调整以适应在后一天开盘前所发生的任何操作。你可以使用这一个列来检验历史回报或者对历史回报做一些细致的分析。
请注意行标签是如何包含日期信息的,以及你的列和列标签是如何包含了数值数据的。
小贴士:如果你现在想要使用pandas 的to_csv()函数把这些数据存储为csv格式的文件,或是通过read_csv()函数把数据读入回Python。这一点在一些特定场景下是极其便利的,例如说Yahoo API终端发生了变动,你难以再次获取数据的情况。
现在,你已经简要地检查了你的数据的第一行,并且已经查看了一些总结性统计数据,现在我们可以稍微深入一步了。
做这件事的一种方法是通过筛选,例如说某一个列的最后十行数据来检查行标签和列标签。后者则被称为取子集,因为你得到的是数据中的一个小的自己。取子集得到的结果是一个序列,也就是一个带标签的,可以是任何数据类型的一维数组。
请记住,DataFrame结构是一个二维标记的数组,它的列中可能包含不同类型的数据。
在下面的练习中,将检查各种类型的数据。首先,使用index和columns属性来查看数据的索引和列。接下来,通过只选择DataFrame的最近10次观察来取close列的子集。使用方括号[ ]来分隔这最后的十个值。您可能已经从其他编程语言(例如R)中了解了这种取子集的方法。总而言之,将后者分配给变量ts,然后使用该type()函数来检查ts的类型。您可以在这里进行练习。
方括号可以很好地对数据进行取子集,但这可能不是使用Pandas最习惯的做法。这就是为什么您还应该看看loc()和iloc()函数:您可以使用前者进行基于标签的索引,后者可用于位置索引。
在实践中,这意味着您可以将行标签(如标签2007和2006-11-01)传递到loc()函数,同时传递整数(如22与43)到iloc()函数。
完成原文中的练习,了解loc()和iloc()两者是如何工作的。
小贴士:如果您仔细查看子集的结果,您会注意到数据中缺少某些日期; 如果您仔细观察这个模式,您会发现通常缺少两三天;这些天通常是周末或公共假期,这些并不是您需要的数据。没有什么可担心的:它完全正常,您不必补全这些缺失的日期。
除了索引之外,您还可能想要探索一些其他技术来更好地了解您的数据。您永远不知道还会出现什么。我们尝试从数据集中抽取大约20行,然后对数据进行重新采样,使得aapl按照每月进行采样而不是每天采样。您可以利用sample()和resample()函数来完成这项功能。
非常简单直接,不是吗?
resample()函数经常被使用,因为它为您的时间序列的频率转换提供了精细的控制和更多的灵活性:除了自己指定新的时间间隔,并指定如何处理丢失的数据之外,还可以选择指示如何重新取样您的数据,您可以在上面的代码示例中看到。这与asfreq()方法形成清晰的对比,它只有前面两种选择。
小贴士:在上述DataCamp Light块的IPython控制台中自己尝试一下。传递aapl.asfreq("M", method="bfill")看看会发生什么!
最后,在您将数据探索提升到一个新的水平之前,请先可视化您的数据并对数据执行一些常见财务分析,您可能已经开始计算每天开盘价和收盘价之间的差额。您可以在Pandas的帮助下轻松执行这项算术运算;只需将aapl数据Close列的值减去Open列的值。或者说,aapl.Close减去aapl.Open。您可以在aapl DataFrame中创建一个新的叫做diff的列存储结果,然后使用del再次删除它。
小贴士:请确保注释掉最后一行代码,以便aapl DataFrame 的新列不会被删除,这样您可以检查算术运算的结果!
当然,以绝对的方式知道了收益,可能已经帮助您了解您是否做出了一个好的投资,但作为一个金融分析师,您可能会对更有力地衡量股票价值更有兴趣,比如某种股票的价值大幅上涨或下跌了多少。这样做的一个方法是计算每日的百分比变化。
现在知道这一点很好,但不要担心; 您会进一步深入它!
本节介绍了一些您在开始执行先验分析之前,可以首先探索数据的方法。但是,在这方面您还可以走得更远。如果您想了解更多,请考虑使用我们的Python Exploratory Data Analysis。
下一步,将使用head(),tail(),索引等等探索您的数据。您可能还需要将您的时间序列数据可视化。Pandas的绘图整合了Matplotlib,使得这项任务变得容易; 只需使用plot()函数并传递相关参数即可。此外,您还可以使用grid参数用以指示在绘图的背景中添加网格。
如果您在原文中运行代码,您将会看到以下图表:
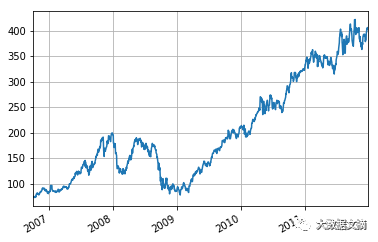
如果您想对Matplotlib了解更多,以及如何开始使用它,请查看DataCamp的Intermediate Python for Data Science课程。
现在,您已经了解了数据,时间序列数据以及如何使用pandas快速浏览数据,现在是深入了解一些您可以做的常见财务分析的时候了,以便您可以开始制定交易策略。
在本节的其余部分,您将了解有关回退、移动窗口、波动率计算和普通最小二乘回归(OLS)的更多信息。
您可以在原文中阅读并练习更多关于常见财务分析的内容。
现在您对数据做了一些初步分析,现在是制定您的第一个交易策略的时候了;但在您进入所有这些之前,为什么不先了解一些最常见的交易策略呢?经过简短介绍,您无疑将更简单地实现您的交易策略。
您可能还记得,在介绍中,交易策略是一个关于长期或短期进入市场的固定计划,但还有更多的信息您还没有真正得到;一般来说,有两个常见的交易策略:动量策略和震荡策略。
首先,动量策略也被称为分离或趋势交易。当您遵循这一策略时,您会这样做的原因是您认为数据的移动将继续朝着当前的方向发展。换句话说,您相信股票有可以发现和利用的惯性,即向上或向下的趋势。
这个策略的一些例子是移动均线交叉,双均线交叉和海龟交易:
移动均线交叉发生在资产的价格从移动平均线的一边移动到另一边的时候。这种交叉代表了势头的变化,可以作为进入或退出市场的决定点。您会看到这个策略的一个例子,本教程后面的定量交易的“您好世界”。
双均线交叉发生在短期平均线跨越长期平均线时。该信号用于识别正在短期平均线的方向上移动的惯性。当短期平均线跨越长期平均线并处于其上方时,产生买入信号,而卖出信号是由短期平均过往长期平均线而低于平均水平触发的。
海龟交易最初是由Richard Dennis教导的一个众所周知的趋势跟踪交易。其基本策略是买入20日高点和卖出20天低点的期货。
其次,震荡策略也被称为融合或循环交易。这一策略背离了数量运动最终会逆转的观点。这可能看起来有点抽象,但是当您使用这个例子时它就不会这么抽象了。回归中值策略,实际上是您相信股票会回到自己的平均水平,那么当您偏离这个平均值时您就可以利用它。
这听起来很实用,是吗?
除了回归中值策略,这种策略的另一个例子是与其相似的配对交易中值回归。回归中值策略基本上表明股票回归中值,而配对交易策略拓展了这一点,并指出如果两个股票相关性相对较高,如果其中一个与另一个移动相关,则可以使用两个股票价格差异的变化表示交易事件。这意味着如果两个股票之间的相关性有所下降,那么价格较高的股票就可以被视为一个空头。另一方面,价格较低的股票应该处于长期状态,因为其价格将会升高,回归平均水平。
除了这两种最常见的策略之外,还有一些您可能偶尔会遇到的其他一些策略,例如预测策略,这种预测策略试图预测股票的方向或价值,如基于某些历史因素的随后的未来时间段。还有高频交易(HFT)策略,利用了亚毫秒级的市场微观结构。
这就是关于现在未来的所有音乐; 让我们现在关注开发您的第一个交易策略!
如上所述,您将从量化交易的“您好世界”开始:移动均线交叉。您将开发的策略很简单:您可以创建两个独立的简单移动平均线(SMA),它们具有不同的回溯期,假设是40天和100天。如果短时移动平均线超过长移动平均线,那么您就走长线,如果长移动平均线超过短移动平均线,则退出。
记住,当您走长线时,您认为股票价格会上涨,将来会以更高的价格卖出(=买入信号); 当您走短线的时候,您卖出您的股票,期望您能以更低的价格买回来,实现利润(=卖出信号)。
当您刚刚开始时,这个简单的策略可能看起来很复杂,但让我们一步步来:
首先定义您的两个不同的回溯期:短窗口和长窗口。您设置两个变量并为每个变量分配一个整数。确保您分配给短窗口的整数小于分配给长窗口变量的整数!
接下来,创建一个空的signals DataFrame,但确保复制您的aapl数据的索引,以便您可以开始计算您的aapl数据的每日买入或卖出信号。
在您的空signals DataFrame中创建一个名为signal的列,并将其行全都初始化为0.0。
在准备工作之后,是时候在各自的长短时间窗口中创建一组短和长的简单移动平均线了。利用的rolling()函数,启动滚动窗口计算:在函数中,指定window和min_period,并设置center参数。在实践中,您将short_window或long_window传递给rolling()函数, 由于窗口观测必须要有值,将1设置为最小值,并设置False使标签不设定在窗口的中心。接下来,不要忘记链接mean()函数,以便计算滚动的平均值。
在计算了短期和长期窗口的平均值后,当短移动平均线跨过长移动平均线时,您应该创建一个信号,但只能在该周期大于最短移动平均窗口期间创建信号。在Python中,需要满足这么一个条件:signals['short_mavg'][short_window:] > signals['long_mavg'][short_window:]。请注意,您添加[short_window:]用以满足条件“只能在大于最短移动平均窗口期间”。当条件为真时,初始化为0.0的signal列将被1.0覆盖。一个“信号”被创建了!如果条件为假,则0.0保留原始值,不生成信号。您可以使用NumPy的where()函数设置此条件。与您刚才读到的一样,您分配这个结果的变量是signals['signal'][short_window],用以在该周期大于最短移动平均窗口期间创建信号。
最后,您可以收集信号的差异,用以产生实际的交易订单。换句话说,在signals DataFrame的这一列中,无论您是买入还是卖出股票,您可以区分长仓和空头。
请看这里的代码。
这不是太难了?输出signals DataFrame并检查结果。重点是这个DataFrame 中positions和signal列的意义。当您继续前进时,您会看到,这将变得非常重要!
当您花费时间了解您的交易策略的结果时,就可以使用Matplotlib快速绘制所有的这些(短期和长期移动平均线以及买入和卖出信号):
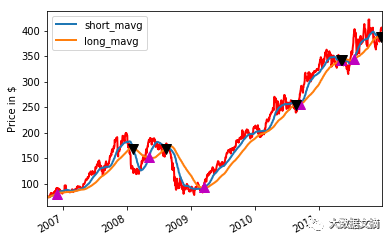
您可以在这里(https://www.datacamp.com/community/tutorials/finance-python-trading)找到这个图表的代码。
这结果很酷,不是吗?
现在你已经掌握了你的交易策略,下一步对它进行回溯测试并计算其业绩是一个很好的想法。但是,在深入了解这一点之前,你可能需要稍微了解下回溯测试(backtesting)的缺陷,在回测器(backtester)中需要哪些组件以及你可以使用哪些Python工具来回测你的简单算法。
若你已经具备了这些知识,你可以继续开始运用你的回测器(backtester)。
回溯测试除了“测试交易策略”之外,还对相关历史数据的策略进行了测试,来确保你在采取行动之前,这是一项切实可行的策略。通过回溯测试,交易员可以在一段时间内模拟和分析具体策略的交易风险和盈利能力。但是,当你做回溯测试时,请明智的记住这其中会存在一些开始时可能并不明显的陷阱。
例如,存在一些外部事件,如市场制度转变,这些通常是监管变化或宏观经济事件,绝对会影响你的回溯测试。还有流动性方面的限制,如禁止卖空,可能会严重影响到你的回溯测是。
接下来,你可能会提醒自己一些其他陷阱,在你比如,过度拟合一个模型(优化偏差)时,在你因认为这样更好(介入)而忽略策略规则,或者在你意外地将信息引入到过去的数据(前视偏误)时。
当你真正去做自己的策略并回溯测试它们的时候,你会发现教程提到的这些陷阱只占需要考虑的很小一部分。
除了陷阱之外,了解回测器通常由四个基本组成部分组成是很有帮助的。它们通常情况下都会出现于回测器中。因此,一个回测器包括以下内容:
除了这四个组成部分之外,还有更多你可以添加到你的回测器中,这取决于策略的复杂性。你完全可以不局限于这四个组成部分。但是,在这个初学者教程中,你只需要关注将这些基本的组成部分在代码中运行。
如上所述,一个回测器由一个策略、一个数据处理程序,一个投资组合和一个执行处理程序组成。你已经实现了上述策略,并且你也有了可以访问数据处理程序的入口. 通过运用pandas-datareader 或者Pandas库将保存在Excel里面的数据导入到Python。接下来需要执行的组件则是执行处理程序和投资组合。
但是,由于你刚刚开始,你不会专注于实现执行处理程序。取而代之的是,你将在下面看到如何开始创建一个可以生产订单并管理损益的投资组合:
首先,你将创建一个initial_capital 变量来设置初始资本值和新的DataFrame positions。你再一次地从另外的DataFrame复制索引(index)。在此处,是signals DataFrame。因为你想要考虑生成信号的时间范围。
接下来,你在DataFrame中创建了一个名为AAPL的新列。在信号为1的时候,短移动平均线跨越长移动平均线(大于最短移动平均窗口),你将购买100股。信号为0的时候,由于操作100*signals['signal']的结果,最终结果将为0。
创建一个新的DataFrame portfolio 来存储敞口仓位的市值。
接下来,你创建一个DataFrame来储存仓位(股票数量)的差异
你的portfolio还包含了一个cash列,这是你剩下可以花费的资金:
它是通过你的初始资金减去持有量(你用于购买股票的钱)计算的。
你还将在portfolio DataFrame中添加一个total列,其中包含你的现金和你股票拥有价值之和
最后,你还将添加一个returns列到你的投资组合里,你将在其中储存回报收益。
代码可以在这里(https://www.datacamp.com/community/tutorials/finance-python-trading)被找到。
作为你的回溯测试的最后一个练习,通过Matplotlib的帮助可视化投资组合的价值或者显示多年来的portfolio['total'] 和你回溯测试的结果:
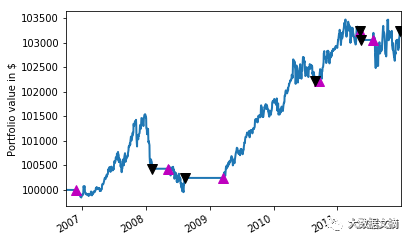
在这里(https://www.datacamp.com/community/tutorials/finance-python-trading#gs.Splq1kQ)找到代码。
请注意,对于本教程,回测器的Pandas代码以及交易策略以你可以轻松地用交互式来浏览的方式组成。在现实生活的应用程序中,你可能会选择一个包含类并更加面向对象的设计,其中包含所有的逻辑。你可以在这里找到带有面向设计的与移动平均交叉策略相同的示例或者查看此演示文稿。
你现在看到如何用Python流行的数据操作包Pandas来实现一个回溯测试器。但是,你也可以看到,很容易犯错,而且这可能不是每次使用最万无一失的选项:因为你需要从头开始构建大部分组成部分,即使你已经利用Pandas来获取结果。
这就是为什么使用一个回溯测试平台是很常见的,例如为你的回溯器选择Quantopian。Quantopian是一个免费的,以社区为中心,用于建立和执行交易策略的托管平台。它由一个名为zipline用于算法交易的Python库支持。你可以在本地调用库,但为了这个初学者教程的目的,你将用Quantopian(https://www.datacamp.com/community/)来编译和回测你的算法。在你进行此操作之前,请确保你首先进行注册了并登录。
接下来,你可以很简单地开始。点击“新算法”(New Algorithm)来开始编写你的交易算法,或选择一个已经被编码的例子,让你更好地了解你正在处理的事情 :)

让我们从简单开始并制作一个新的算法,但仍然遵循移动平均交叉的简单示例,这是你能在ziplineQuickstart guides(http://www.zipline.io/)中找到的标准示例。碰巧这个例子与上一节中实现的简单交易策略非常相似。但是,你看到的下面代码块中以及上面截图中的结构与本教程中迄今为止所看到的结构有一些不同,即你有两个开始工作的定义,及initialize() 和handle_data()。
在这里(https://www.datacamp.com/community/tutorials/finance-python-trading)找到代码。
当程序启动时,第一个函数被调用并执行一次启动逻辑。作为一个参数,initialize() 函数接受一个context,用于储存在回溯测试或实时交易期间的状态,并且可以在算法的不同部分中被引用,如下面的代码所示;你会看到context在第一个移动平均窗口的定义中返回。你会看到你通过符号来制定查找安全的结果(在这种情况下,股票),(AAPL在这种情况下)并指定到context.security。
handle_data() 函数在模拟或现场交易中每分钟被调用一次,已决定每分钟防止什么订单(如果有的话)。该函数需要context 和data 作为输入:context与上文刚刚读到的相同,而data是储存多个API函数的对象,例如current() 来检索给定资产给定领域的最新值或者history() 来获取历史定价或交易量数据的追踪窗口。这些API函数不在下面的代码中返回也不在本教程的范围内。
请注意 你在Quantopian控制台敲入的代码只能在平台运行而不能在本地Jupyter Notebook中,比如!你会看到data对象允许你检索price, 用于forward-filled,通过得到最近的已知价格,如果有的话。如果没有,将返回一个NaN值。
你在上面代码块中看到的另一个储存你的投资组合重要信息的对象是portfolio。正如你在context.portfolio.positions代码中看到的,该对象储存在context中也可以作为用户提供给你的核心函数访问。
注意 你刚刚读到的positions,是用来储存仓位对象并包括股数和支付的价格等信息。此外,你能看到 portfolio 还有cash property来获取你投资组合中的现金数额,而positions对象也有amount property来查看某一仓位的全部股数。
order_target() 放置一个订单来调整目标股数的仓位。如果资产中没有仓位,则设置一个完整目标数的订单。如果资产中有仓位,则设置一个目标股数或合约与当有持有量差额的订单。放置负面目标订单将导致一个做空仓位等同于特定的负数。
建议:如果你对函数或对象有任何疑问,请确保查看Quantopian Help page(https://www.quantopian.com/help),其中包含有关本教程中简要介绍的所有内容(以及更多)。
当你使用initialize() 和handle_data() 函数(或复制粘贴上述代码)到界面左侧的控制台中创建策略时,只需按“构建算法”(Build Algorithm)按钮构建代码并且运行回溯测试。如果你按“运行完全的回测”(Run Full Backtest)按钮,则会运行完整的回溯测试,这与你在构建算法时运行的基本相同,但你将能够更详细地查看更多内容。回溯测试,无论是“简单”还是完整版,运行都可能需要一段时间,请确保注意页面顶部的进度条!
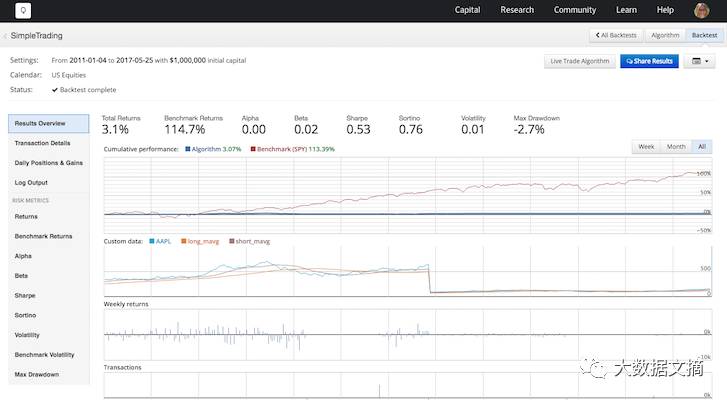
你可以在这里(https://www.quantopian.com/tutorials/getting-started)找到更多关于如何开始Quantopian的信息。
请注意Quantopian是开始使用zipline的简洁方式,但是你通常会移动在本地库里使用它,比如,你的Jupyter notebook里。
你已经成功地做了一个交易算法,并通过Pandas,Zipline和Quantopian进行回溯测试。可以说你已经被普及了如何用Python进行交易。但是,当你完成了交易策略的编写并回溯测试它,你的工作还没有结束;你可能希望改进你的策略。这里有一个或多个算法来持续地改进模型,例如KMeans,K近邻(KNN),分类或递归树和遗传算法。这将是以后DataCamp教程的话题。
除了你可以使用其他算法之外,你还可以观察到你可以通过使用投资组合来改善策略。只将一个公司或符号并入你的策略,通常不会有太多改进。你还会在评估你的移动平均交叉策略看到改进提醒。其他你可以添加或采取不同的做法是使用风险管理框架或使用事件驱动的回溯测试来帮助减轻你之前阅读到的前瞻性偏差。还有许多其他可以改善你策略的方式,但现在,这是一个很好的开始!
改进你的策略并不意味着你已经完成了。你可以轻松使用Pandas来计算一些指标,来进一步判断你的简单交易策略。在本节中,你将了解夏普比率,最大跌幅和复合年增长率(GAGR)。
在这里(https://www.datacamp.com/community/tutorials/finance-python-trading)获取更多阅读和训练。
除了这两个指标外,你还可以考虑许多其他因素,如回报分配,贸易水平指标…
再进一步!
干的漂亮,你已经通过了这个Python金融介绍教程!你已经学会了很多基础知识,但还有更多的需要你去发现!
查看Yves Hilpisch的Python For Finance书,这本书适合一些有金融背景,但是不太了解Python的人。Michael Heydt的“Mastering Pandas for Data Science”也值得推荐给想要开始在金融领域运用Python的人。也请确保浏览Quantstart’s articles(https://www.quantstart.com/articles)和this complete series on Python programmingfor finance(https://pythonprogramming.net/python-programming-creating-automated-trading-strategy/)作为算法交易的入门教程。
如果你对如何运用R进行你的金融实践之旅,可以考虑Datacamp的Quantitative Analyst with R (https://www.datacamp.com/tracks/quantitative-analyst-with-r)方向。与此同时,我们将继续发布第二篇关于如何开始Python在金融领域的运用的文章。请查看Jupyter notebook of this tutorial(https://github.com/Kacawi/datacamp-community)。
原文链接:https://medium.com/datacamp/python-for-finance-algorithmic-trading-60fdfb9bb20d
2017年7月《顶级数据团队建设全景报告》下载
关于转载
如需转载,请在开篇显著位置注明作者和出处(转自:大数据文摘 | bigdatadigest),并在文章结尾放置大数据文摘醒目二维码。无原创标识文章请按照转载要求编辑,可直接转载,转载后请将转载链接发送给我们;有原创标识文章,请发送【文章名称-待授权公众号名称及ID】给我们申请白名单授权。未经许可的转载以及改编者,我们将依法追究其法律责任。联系邮箱:[email protected]。
点击图片阅读
MIT想用社交圈美食图训练识菜谱的AI?先过麻婆豆腐这一关!













