某股份制商业银行的PaaS平台是由Wise2C与Rancher合作,基于Rancher做的定制化开发。基于业务场景和银行业的特殊需求,同时为了兼顾能够实现对以后Rancher版本的平滑升级,我们在Rancher之上做了一层逻辑抽象。
整体软件架构如下图所示:
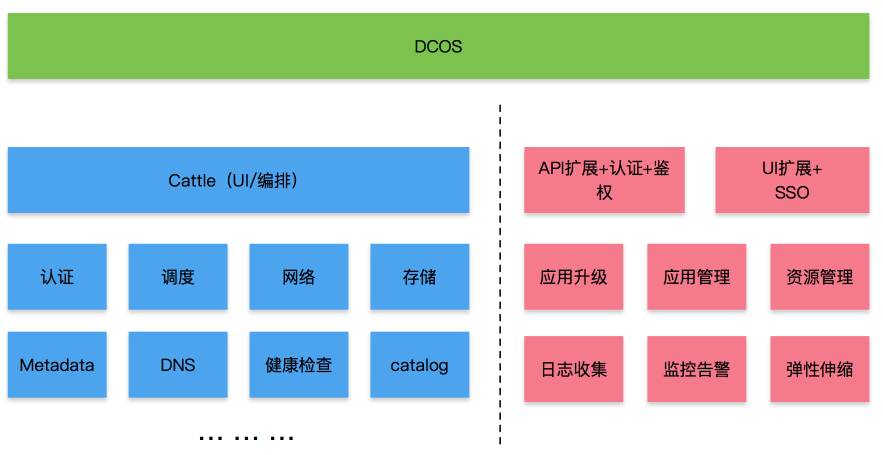
顶层的DCOS作为统一的管理平台,可以通过PaaS以及IaaS提供的API实现对云平台的集中管控。左侧蓝色部分是原生Rancher,DCOS与红色定制化部分通过API来访问Rancher。由于未对Rancher做任何改动,可以做到对Rancher版本大于1.2的平滑升级。
红色部分为定制化逻辑抽象部分,归纳起来可以按照功能职责大致分为以下微服务(后面会详细介绍):
-
鉴权认证
-
资源管理
-
应用编排
-
弹性伸缩
-
日志收集
-
监控告警
-
镜像仓库
这些微服务在部署时按照Rancher将infrastructure stack部署到环境中的思路,使用一个独立的Rancher环境来部署这些微服务,部署拓扑结构如下图所示:
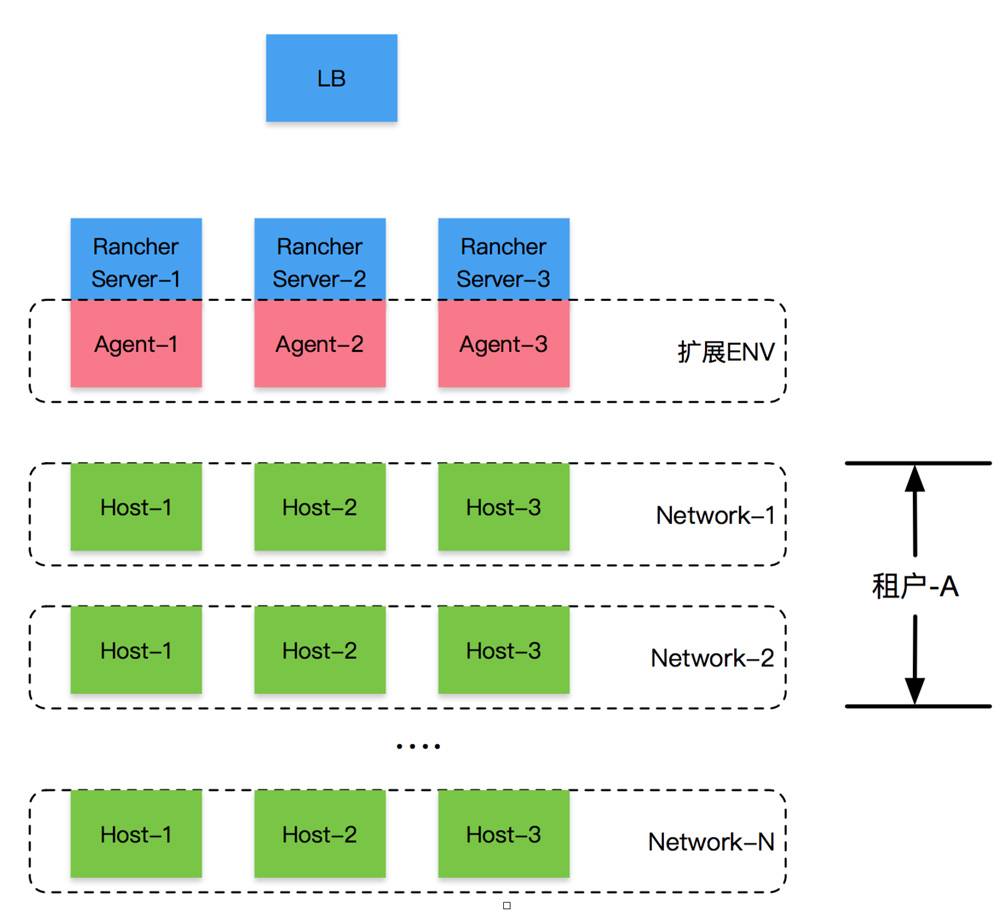
图中每一个虚线框对应Rancher中的一个环境;“扩展ENV”这个环境直接使用Rancher server的主机作为Agent,上面运行定制化的微服务。其他环境分别对应到某个租户的特定网络,单个网络内部流量不使用Rancher原生的overlay,而采用Wise2C实现的扁平化网络,网络之间流量由外部防火墙控制。
PaaS平台的角色与权限模型沿用了Rancher的一部分概念,又引入了自己的内容。主要差异在于两方面:
-
PaaS平台引入了对镜像仓库的管理,这在Rancher中是没有的;即角色的权限,除包含操作Rancher外,还能够操作镜像仓库。镜像仓库与PaaS的权限模型是一致的;
-
另外,客户引入了租户的概念,这点与Rancher中不同,租户是可以跨越多个Rancher的环境的;
Rancher权限模型
PaaS平台权限模型
-
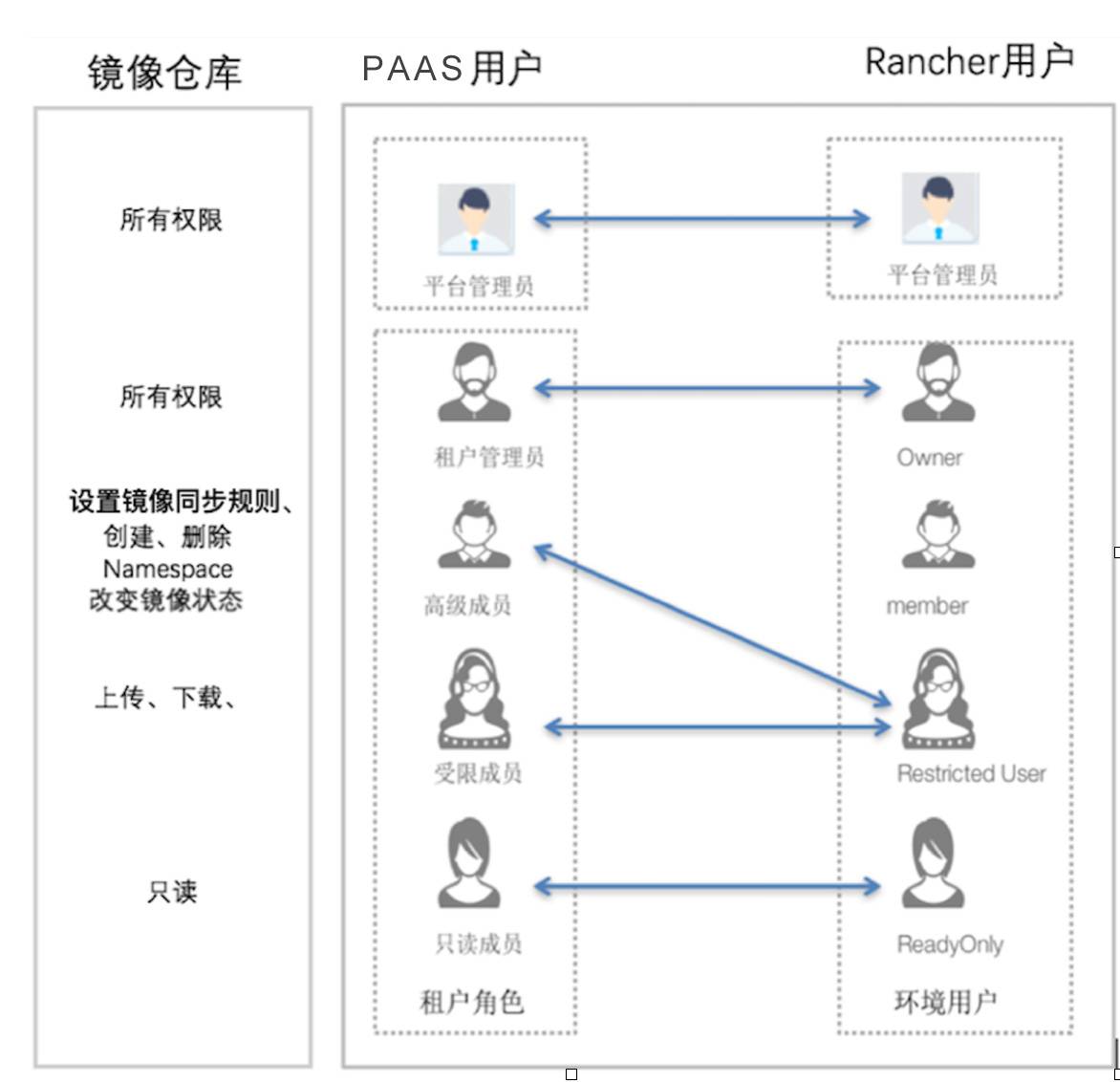
平台管理员:
等同于Rancher的平台管理员权限再加上对镜像仓库管理的所有权限;
-
租户内部角色:
租户管理员,拥有管理租户资源以及对租户内部用户进行授权的所有权限,再加上对镜像仓库管理的所有权限。
高级成员,在PaaS平台内拥有对租户内用户授权以及操作基础资源外的所有权限,在镜像仓库内,拥有对镜像仓库设置镜像同步规则、创建、删除镜像仓库Namespace、改变镜像状态等权限。
受限成员,在PaaS平台内拥有对租户内用户授权以及操作基础资源外的所有权限,在镜像仓库所属Namespace内,拥有上传、下载镜像的权限。
Read Only,在PaaS平台内,拥有查看租户类资源的权限,在镜像仓库所属Namespace内,拥有查看镜像仓库资源的权限。
具体映射关系如下图所示:
鉴权部分的软件设计如下所示:
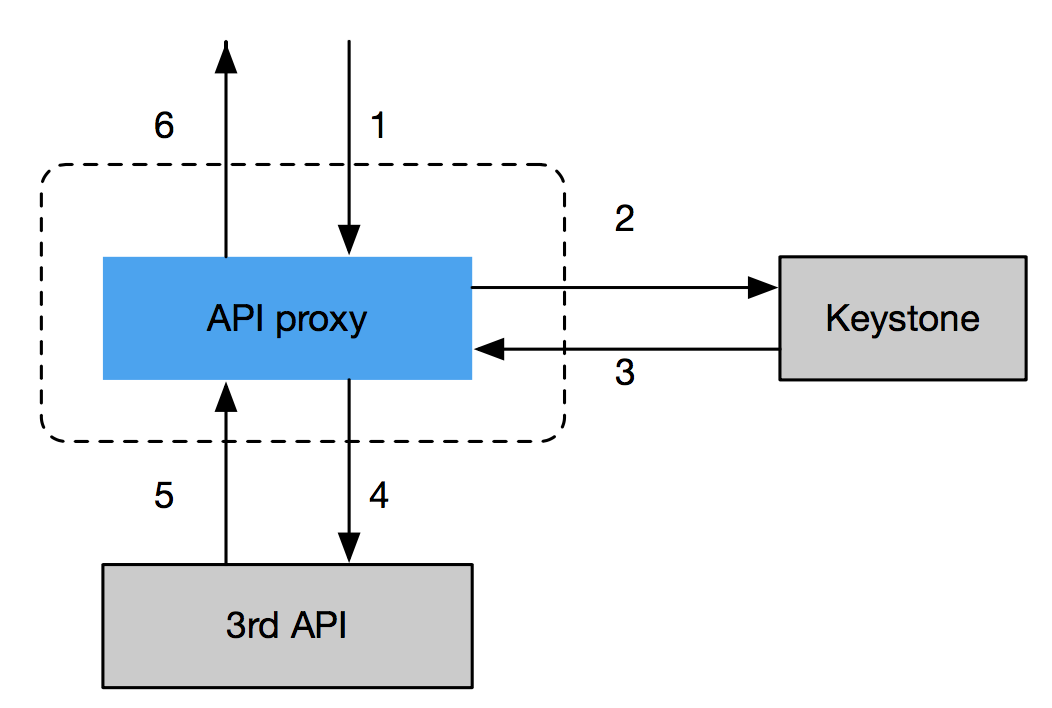
所有对PaaS访问的API请求均经由API proxy做鉴权控制之后代理到系统内部具体的微服务上。PaaS不直接参与租户的增删查改,API proxy通过与PaaS外部的Keystone通信来获取用户角色以及租户信息。
网络部分
-
由于金融行业对网络安全性方面的要求比较苛刻,而Rancher所能够提供的均是基于某个环境内部的overlay网络。Overlay必然会导致很多报文无法被安全设备透明的过滤,这是行业内无法接受的;因此,必须采用扁平网络。
-
处于安全的考虑,会出现同一个stack内部的多个service需要分别部署到不同的网络分区的需求,采用当前Rancher的managed网络显然无法满足需求;因此,必须支持多网络。
对于扁平网络的支持,我在之前的文章(在Rancher 1.2中实现基于CNI的扁平网络)中有详细的介绍,主要是使用ebtable直接在linux bridge上对流量做控制,从而避免使用overlay;这样,外部安全设备能够透明的看到各个容器之间的流量。
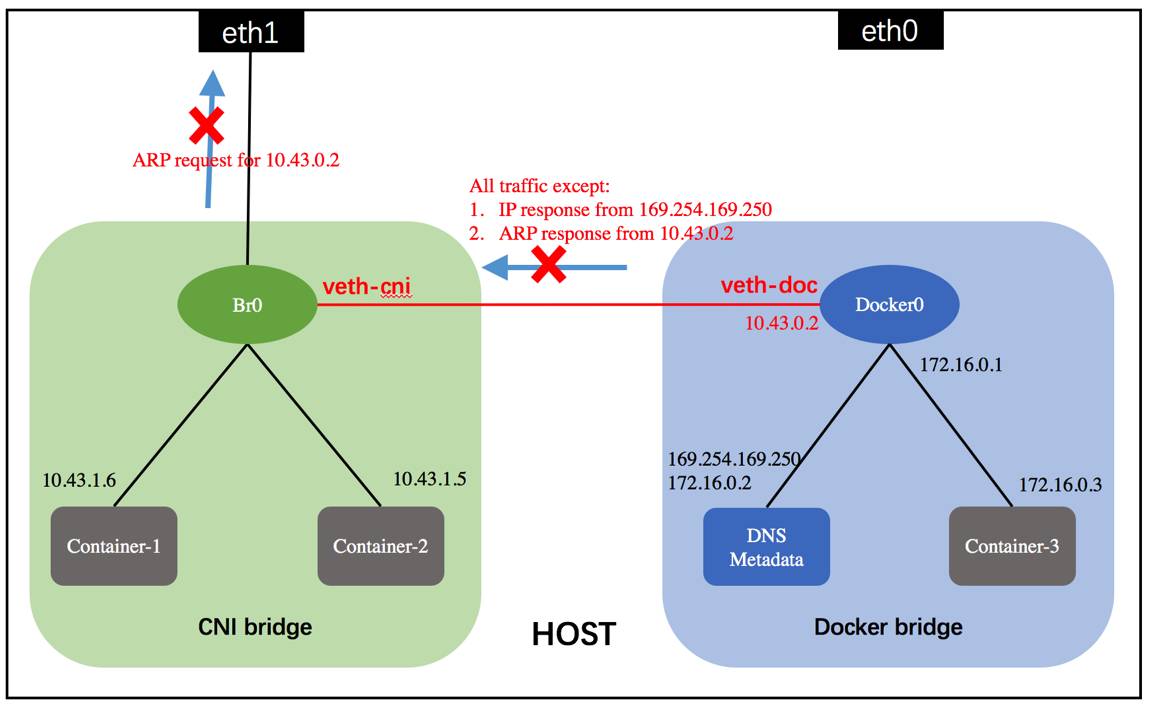
对于多网络的支持,我们是通过在Rancher之上实现一层抽象逻辑来实现的。整个模型演变为一个网络映射为Rancher的一个环境(环境内部运行一个扁平网络)。这部分主要涉及对平台中所有网络的管理,以及维护租户与网络之间的映射关系。
下面举一个例子来描述该流程:
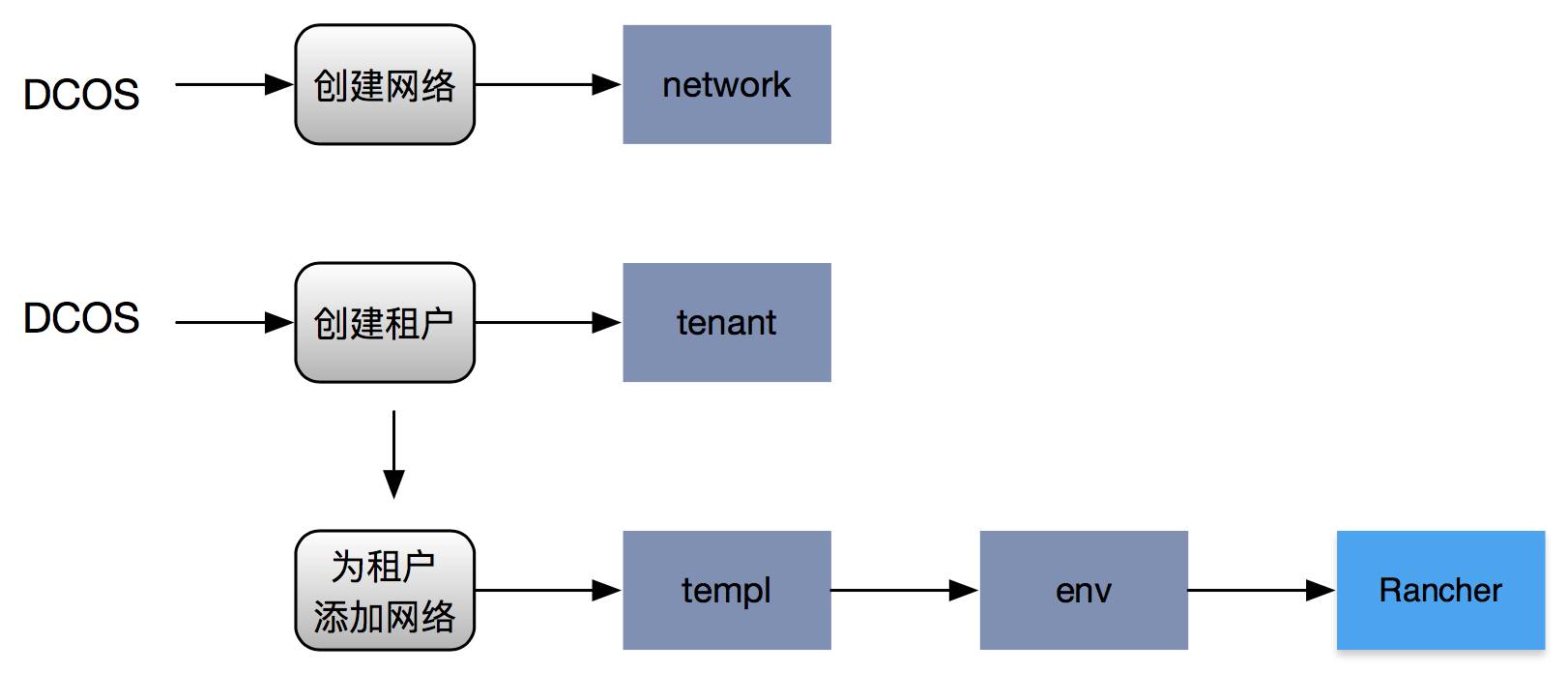
平台管理员在PaaS上创建一个网络,指定网络的参数(子网掩码、网关、所属安全域、所属隔离域等),这些数据会保存到数据库;
平台管理员根据需要为租户分配第一个网络;此时,抽象层需要真正在Rancher上创建出网络所对应的环境;以及创建监控、日志、以及定制化系统所需的system级别的应用堆栈;
当平台管理员为租户分配第二个以上的网络时,抽象层还需要将该Rancher环境与租户其他网络对应的Rancher环境之间建立env link关系,否则跨Rancher环境的应用堆栈各service之间无法使用Rancher DNS进行互访。
存储部分
客户PaaS在存储部分最终选定NFS作为其存储方案,前期也有讨论过使用ceph等,这部分我在之前的文章(探讨容器中使用块存储)中也有专门分析过为什么不选用那种方案。
由于单个租户可以拥有多个网络(也就是多个Rancher环境),而在Rancher中Rancher-NFS driver所创建volume是基于环境层面的。为了能够将该volume映射到租户层面,我们在抽象层中做了这层映射操作。
具体流程如下
平台管理员在PaaS中指定参数创建出一个NFS server;同网络一样,此时只是将数据保存到数据库;
平台管理员为租户分配NFS server,此时抽象层真正操作租户网络所对应的多个Rancher环境,在逐个环境内添加用于提供Rancher-NFS driver的system stack;
假设租户内用户创建、删除、更新volume;同上,抽象层需要在逐个租户网络对应的Rancher环境内操作volume。
之所以要这样抽象的原因在于客户存在跨网络部署应用栈的需求,因此,存储必须基于租户的粒度,实现跨Rancher环境共享。除此之外,对NFS server的管理方面,客户方面也有自己特殊的要求:
物理存储是按照性能分等级的,同一个租户应该可以同时拥有金牌、银牌、铜牌的NFS server。基于业务的级别,可以为不同级别的微服务指定使用不同等级的NFS server。
因此,与当前Rancher对存储的使用方式不同体现在:同一个租户可以关联多个NFS server,租户内用户在创建volume的时候,可以指定NFS server。
在应用编排方面,基于金融行业的特殊安全需求,客户要求应用堆栈能够基于微服务的安全等级来跨网络部署同一个应用堆栈,即应用堆栈中的多个微服务可能跨域多个不同网络。
为了实现跨网络部署微服务,除了对基础资源(网络和存储)模型进行抽象之外,整个应用堆栈的部署流程也需要做相应的调整;
另外,对应用堆栈的描述不再使用rancher的catalog,而是基于一套开源的Tosca模板标准;这样做的目的是方便与OpenStack以及其他平台贯通,方面以后使用同一个模板来描述整个IaaS和PaaS的编排情况;
对应用堆栈以及内部微服务的更新,要求提供统一的接口,均通过下发新的Tosca模板更新应用栈的方式来实现。
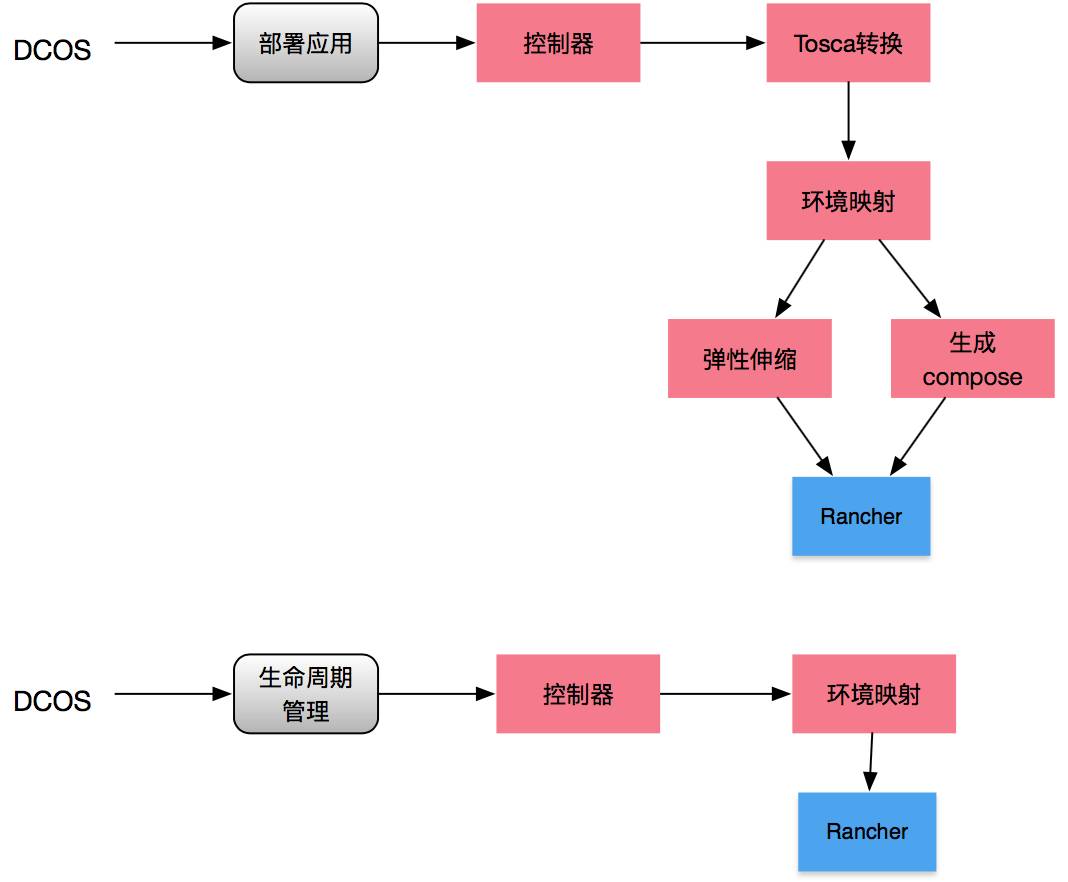
在解决应用堆栈的跨网络(Rancher环境)部署以及基于Tosca的编排方面,我们在抽象层中操作流程如下:
接受用户输入的Tosca模板,然后交由translator模块做模板语法的check以及翻译,最终输出能够分别部署到各个Rancher环境的rancher-compose文件以及其他附加信息;
orchestration模块需要对translator的返回信息进行资源层面的检查,比如是否该租户拥有应用堆栈部署所需的网络(Rancher环境)等;
基于Translator的返回信息,按照各个网络之间微服务的依赖关系,决定各个rancher-compose的部署先后顺序,然后开始往网络中(Rancher环境中)部署没有存在依赖的rancher-compose;
基于Rancher环境中应用堆栈的部署情况,按照依赖顺序,逐个部署后续的rancher-compose;
在确保当前应用堆栈在所有Rancher环境中的rancher-compose都部署完成后,将该应用栈的弹性伸缩规则下发到弹性伸缩模块。
自动弹性伸缩是客户基于其业务场景而定制化的需求,大致如下:
首先弹性伸缩的策略是基于时间段的,即按照一天为周期,可以设置在一天的某个时间段内采用哪一种弹性伸缩策略;
弹性伸缩的策略包括三种:
-
基于微服务下所有容器的CPU利用率的平均值;
-
基于微服务下所有容器的内存使用率的平均值;
-
基于时间段,只要进入该时间区间,直接将容器数量伸或缩为某个最大或者最小值;在从该时间区间离去时,恢复容器数;





