
是什么将“统计”从“机器学习”中分离出来的?
这是一个被讨论过无数次的问题。关于这个问题的文章有很多,人们对其好坏莫衷一是。但是我发现,在“统计”和“机器学习”的争论上,人们往往会“只见森林,不见树木”。
Aatash Shah曾在他的文章中作过这样的定义:
“机器学习”是一种能够直接从数据中学习,而无需依赖规则编程的算法。
“建立统计模型”的意思是以数学方程式来表示数据变量间的关系。
Shah更多是从“机器学习”和“统计模型”的不同目的出发,对两者进行定义的。他把“机器学习”看成一种实践活动,把“统计模型”则视为抽象理论。(我在这里讲到的“统计模型”事实上就是“统计”。)但实际上,“统计”与“机器学习”的关系要复杂得多,仅凭定义概念来分析这两者的关系是远远不够的。
对于这一关系的哲学性思考和研究,很快就演变成了下面这些问题:
“机器学习”是建立在“统计”的基础之上的吗?
“机器学习”是不是一组传统的统计数据?
这两个概念间是否存在共通之处?有没有一个相对统一的概念?
我认为以这样的方式建构和设计的、所谓的高水平方法,其实是错误的,也是非常浪费时间的。
那么在这种情况下,“回归分析”究竟是不是“机器学习”的一种特殊形式呢?
Gregory Piatetsky-Shapiro是KDnuggets公司总裁,关于这个问题,他的观点很好地反驳,并且打破了“回归可能过于简单,以至于不能称之为机器学习”的这一说法。
在一些机器学习研究专家看来,传统的“线性回归”可能过于简单,不能被称为真正的“机器学习”,而只能算是“统计”。但我认为“机器学习”和“统计”之间的界限其实是非常模糊和任意的。比如说,C4.5决策树算法也不是很复杂,但它却被划分为了“机器学习”。
其实,很多更高级、更先进的算法都产生于线性回归,比如“脊回归”、“最小角度回归”和LASSO,而且这些算法大多都被机器学习专家使用过。所以,想要更好地理解这些算法,你必须要先了解基本的“线性回归”。
因此,“线性回归”应该是所有机器学习研究者必备工具之一。
Diego Kuonen和 CStat PStat CSci都是瑞士日内瓦大学“数据科学”的教授,他们分别是“数据咨询所”的CEO和CAO。他们针对这个问题提出了以下见解:
每一个有监督的分析模型(来自统计、数据科学或是机器学习)都会作出一种假设,即模型输出的分布是如何依赖模型输入的。如果分析模型没有作出任何假设,那么除了那些观察到的数据之外,就没有任何可供理性分析的根据了。
因此,把结论仅建立在一个“有效模型”(“有效模型”指的就是那些假设经过了验证的模型)的基础之上才是正确的做法。
为了实现理解数据的终极目标,我们需要使用两种工具——“统计模型”和“机器学习模型”。Diego似乎不太关心使用的是哪种工具,而是关注这个工具使用得是否恰当、有效模型是否建立,以及最终的数据理解是不是增加了。如果最终的结论是建立在无效模型之上的,那么关于统计数据与机器学习间关系的争论就是毫无意义的。
我个人对这些问题的思考已经持续了好多年。当我最初意识到“线性回归”、“决策树”这些简单的概念也能够被视为“机器学习”时,我感到非常震惊。因为在那之前的学习中,从来没有人对我提起过“机器学习”一词。我以为,所有跟我处于同样专业水平的人都会有如此的反应。
认真思考了“数据研究”和“机器学习”之间的关系之后,我认为数据研究实际上是一个研究过程,而机器学习是推动这一研究进行的工具。那么给“统计”下一个现代化的定义即——“统计”一门是从数据中学习的,能够测量、控制和沟通不确定性的科学。比起这些复杂的概念,我更乐于将“统计研究”的定义简化为“大规模的高速统计数据分析”。
同样简单地理解,机器学习有三个组成部分:第一,数据;第二,模型或者估计函数;第三,需要降到最低的成本或损失。机器学习的整个raison detre过程实际上是其运用类似的统计问题来优化损失函数的过程。
那么这时,我们再回到最初的问题——“线性回归”,也就是“回归分析”最基本的形式,是否满足了这些要求呢?
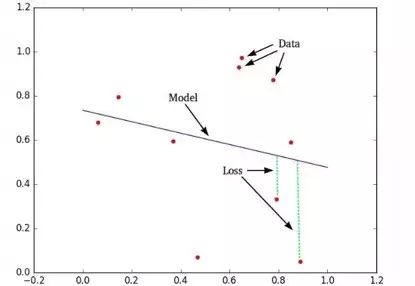
当然了,这个问题还没有完全解决。假设这样一个情景:我有十个数据,绘制了前面九个数据结果,我让第十个数据重新返回测试,然后亲自解这个方程,并手绘测试结果——这样算是机器学习吗?如果不算(很明显不算是机器学习),那么究竟怎样才算是“机器学习”呢?
与上述观点不同的是,Mike Yeomans曾经在他的文章中提到,我们应该把机器学习简单地看作是统计数据的一个分支。Kuonen对这个观点表示了赞同,他同时还指出,尽管可能有人会说“数据研究其实是大规模、高速度的统计”(Daryl Pregibon, 1999),但他发现了他们的方法存在不同之处。我曾向Cannon Gray的总裁Kevin Gray征求了意见,他将这个话题引入到另一个问题中,思考着这个话题的讨论是否有必要。
在此,我要感谢所有对这篇文章作出过贡献的人,特别要感谢Diego Kuonen教授在写作中的投入和反馈。
媒体合作请联系:
邮箱:[email protected]









