![]()
#长按上图识别二维码,参与OSC源创会年终盛典#
Elasticsearch
是一款开源的搜索引擎,由于其高性能和分布式系统架构而备受关注。本文将讨论其关键特性,并手把手教你如何用它创建 Node.js 搜索引擎。
Elasticsearch 底层使用
Apache Lucene
库,Apache Lucene 自身是一款高性能、基于文本的搜索引擎库。 Elasticsearch 并不以提供数据存储和检索等类数据库功能为核心目标,相反,它以搜索引擎(服务器端)为目标,意在提供数据索引、数据检索、和数据实时分析功能
Elasticsearch 采用分布式架构,因而通过新增节点、或者部署到系统已有节点上即可实现水平扩展。Elasticsearch 可以在数以百计的服务器上处理 PB级别的数据。水平扩展同时也意味着高可用性,如果有节点异常,数据可重新被调度执行。
一旦数据导入完成,即可被检索。Elasticsearch 提供无模式、JSON 格式文件存储、数据结构和类型自动检检测等功能。
Elasticsearch 同时采用完全 API 驱动,这意味着:几乎所有的操作都可在 HTTP 上通过使用符合 JSON 数据格式的Restful API 完成。Elasticsearch 提供多种程序语言的客户端 lib,包括 Node.js。
Elasticsearch 对软硬件要求比较灵活。虽然官方建议线上环境采用 64GB 内存,和尽可能多 CPU 系统配置,但其在一个资源受限的系统中依然可以很好地运行(前提是你的数据集不大)。如本文中的示例,2GB 内存,单核 cpu 系统即可。
Elasticsearch 支持主流操作系统,如 Linux、Mac os 和 Windows,只需安装最新版的 Java 运行时环境(参考 Elasticsearch 安装章节)。对于本文中的示例,还需要安装
Node.js
(v0.11.0 之后的版本都可) 和
npm
。
![]()
Elasticsearch使用自己的术语,在某些情况下和典型的数据库系统中使用的术语不同。下面列出了Elasticsearch中常用的一些术语及其含义。
索引:
在Elasticsearch环境中,该术语有两个含义。第一个含义是添加数据的操作。当添加数据时,文本会被拆分成分词(token)(例如:单词),每个分词都会被索引。然而,一个索引也指的是所有索引数据的存储位置。通常,当我们导入数据时,数据会被索引成一个index。每次需要对数据执行任何操作时,都必须指定它的索引名。
类型
:Elasticsearch在一个索引中对文档提供了更详细的分类,称为类型。一个索引中的每个文档还必须有一个类型。例如,我们可以定义一个图书馆(library)索引,然后再将数据索引成多种类型,比如,文章(article)、书(book)、报告(report)和演示(presentation)。由于索引几乎有固定的开销,所以建议使用较少的索引和较多的类型,而不是较多的索引和较少的类型。
Search:
这个术语的意思也许你也能想得到。你可以使用不同的类型索引查找数据。Elasticsearch 提供了许多搜索查询的类型,例如:术语,短语,范围,模糊,甚至地理数据的查询。
Filter:
Elasticsearch 允许你为了深入缩小查询结果而基于不同的条件过滤查询结果,如果你对一组文档增加一个新的搜索查询,这也许会改变基于关联的顺序,但是如果你把相同的查询做为过滤,顺序保持不变。
Aggregations:
提供给你一些汇总数据的不同统计类型,例如:最小,最大,平均,和,柱状图,等等。
Suggestions:
Elasticsearch 为输入文本提供了不同的建议类型。这些建议可以是术语或者基于短语,甚至是完整的句子。
Elasticsearch 受Apache 2许可证保护,可以被下载,使用,免费修改。安装Elasticsearch 之前你需要先确保在你的电脑上安装了Java Runtime Environment (JRE) ,Elasticsearch 是使用java实现的并且依赖java库运行。你可以使用下面的命令行来检测你是否安装了java
![]()
推荐使用java最新的稳定版本(写这篇文章的时候是1.8)。你可以在
这里
找到在你系统上安装java的指导手册。
接下来是下载最新版本的Elasticsearch (写这篇文章的时候是2.3.5),去
下载页
下载ZIP 文件。Elasticsearch 不需要安装,一个zip文件就包含了可在所有支持的系统上运行的文件。解压下载的文件,就完成了。有几种其他的方式运行Elasticsearch ,比如:获得TAR 文件或者为不同Linux发行版本的包。
如果你使用的是Mac操作系统并且安装了
Homebrew
,你就可以使用这行命令安装Elasticsearch brew install elasticsearch.Homebrew 会自动添加executables 到你的系统并且安装所需的服务。它也可以使用一行命令帮你更新应用:brew upgrade elasticsearch.
想在Windows上运行Elasticsearch ,可以在解压的文件夹里,通过命令行运行bin\elasticsearch.bat 。对于其他系统,可以从终端运行 ./bin/elasticsearch.这时候,Elasticsearch 就应该可以在你的系统上运行了。
就像我之前提到的,你可以使用Elasticsearch的几乎所有的操作,都可以通过RESTful APIs完成。Elasticsearch 默认使用9200 端口。为了确保你正确的运行了Elasticsearch。在你的浏览器中打开http://localhost:9200/ ,将会显示一些关于你运行的实例的基本信息。
Elasticsearch不须图形用户界面,只通过REST APIs就提供了几乎所有的功能。然而如果我不介绍怎么通过APIs和 Node.js执行所有所需的操作,你可以通过几个提供了索引和数据的可视化信息GUI工具来完成,这些工具甚至含有一些高水平的分析。
Kibana
, 是同一家公司开发的工具, 它提供了数据的实时概要,并提供了一些可视化定制和分析选项。Kibana 是免费的。
还有一些是社区开发的工具,如
elasticsearch-head
,
Elasticsearch GUI
, 甚至谷歌浏览器的扩展组件
ElasticSearch Toolbox
.这些工具可以帮你在浏览器中查看你的索引和数据,甚至可以试运行不同的搜索和汇总查询。所有这些工具提供了安装和使用的攻略。
弹性搜索为Node.js提供一个官方模块,称为elasticsearch。首先,你需要添加模块到你的工程目录下,并且保存依赖以备以后使用。
![]()
然后,你可以在脚本里导入模块,如下所示:
![]()
最终,你需要创建客户端来处理与弹性搜索的通讯。在这种情况下,我假设你正在运行弹性搜索的本地机器IP地址是127.0.0.1,端口是9200(默认设置)。
![]()
日志选项确保所有错误被打印出来。在本篇文章末处,我将使用相同的esClient对象与Elasticsearch进行通讯。这里提供Node模块的复杂文档说明。
注意:这篇导读的所有源代码都可以在GitHub下载查看。最简单的查看方式是在你的PC机上克隆仓库,并且从那里运行示例代码:
![]()
在本教程中,我将使用 1000 篇学术论文里的内容,这些内容是根据随机算法逐一生成的,并以 JSON 格式提供,其中的数据格式如下所示:
![]()
JSON 格式中的每个字段如字面意思,无需多余解释,但值得注意的是:由于包含随机生成的文章的全部的内容(大概有100~200个段落),所以并未展示。
虽然 Elasticsearch 提供了
索引(indexing)
,
更新(updating)
、
删除(deleting)
单个数据的方法,但我们采用
批量(bulk)
接口导入数据,因为批量接口在大型数据集上执行操作的效率更高。
![]()
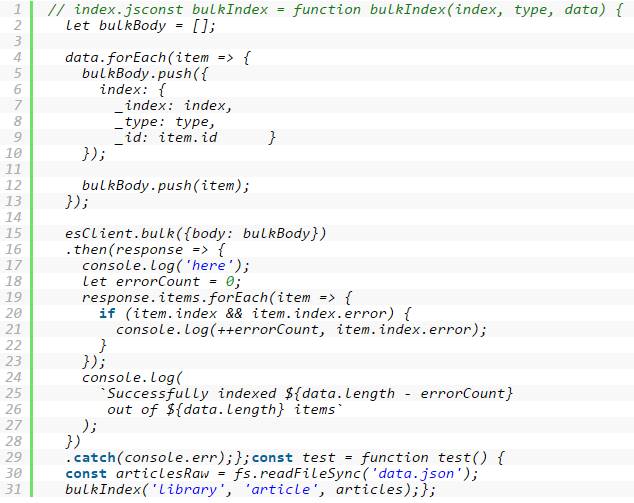
这里,我们调用函数bulkIndex建立索引,并传入 3 个参数,分别是:索引名 library,类型名library,JSON 数据格式变量 articles。bulkIndex函数自身则通过调用esClient对象的bulk接口实现,bulk 方法包含一个body属性的对象参数,并且每个body属性值是一个包含 2 种操作实体的数组对象。第一个实体是 JSON 格式的操作类型对象,该对象中的index属性决定了操作的类型(本例子是文件索引)、索引名、文件ID。第二个实体则是文件对象本身。
注意,后续可采用同样的方式,为其他类型文件(如书籍或者报告)添加索引。我们还可以有选择的每个文件分配一个唯一的ID,如果不体统唯一的ID,Elasticsearch 将主动为每个文件分配一个随机的唯一ID。
假设你已经从代码库中下载了 Elasticsearch 项目代码,在项目根目录下执行如下命令,即可将数据导入至Elasticsearch中:
![]()
Elasticsearch 最大的特性是接近实时检索,这意味着,一旦文档索引建立完成,1 秒内就可被检索(见
这里
)。索引一旦建立完成,则可通过运行 indice.js 检查索引信息的准确性(
源码链接
):
![]()
client 中的cat 对象方法提供当前运行实例的各种信息。其中的 indices 方法列出所有的索引信息,包括每个索引的健康状态、以及占用的磁盘大小。 而其中的 v 选项为 cat方法新增头部响应。
当运行上面代码段,您会发现,集群的健康状态被不同的颜色标示。其中,红色表示为正常运行的有问题集群;黄色表示集群可运行,但存在告警;绿色表示集群正常运行。在本地运行上面的代码段,您极有可能(取决于您的配置)看到集群的健康状态颜色是黄色,这是因为默认的集群设置包含 5 个节点,但本地运行只有 1 个实例正常运行。鉴于本教程的目的仅局限于 Elasticsearch 指导学习,黄色即可。但在线上环境中,你必须确保集群的健康状态颜色是绿色的。
![]()
如前所述, Elasticsearch 无模式(schema-free),这意味着,在数据导入之前,您无需定义数据的结构(类似于SQL数据库需要预先定义表结构),Elasticsearch 会主动检测。尽管 Elasticsearch 被定义为无模式,但数据结构上仍有些限制。
Elasticsearch 以映射的方式引用数据结构。当数据索引建立完成后,如果映射不存在,Elasticsearch 会依次检索 JSON 数据的每个字段,然后基于被字段的类型(type)自动生成映射(mapping)。如果存在该字段的映射,则会确保按照同样的映射规则新增数据。否则直接报错。
比如:如果{"key1": 12} 已经存在,Elasticsearch 自动将字段 key1 映射为长整型。现在如果你尝试通过{"key1": "value1", "key2": "value2"} 检索, 则会直接报错,因为系统预期字段 key1 为长整型。同时,如果通过 {"key1": 13, "key2": "value2"} 检索则不会报错,并为字段 key2 新增 string 类型。
映射不能超出文本的范围,大都数情况下,系统自动生成的映射都可正常运行。
一旦完成数据索引,我们就可以开始实现搜索引擎。Elasticsearch提供了一个直观的基于JSON的全搜索查询的结构-Query DSL,定义查询。有许多有用的搜索查询类型,但是在这篇文章中,我们将只看到几个通用的类型。关于Query DSL的完整文章可以在
这里
看到。
请记住,我提供了每个展示例子的源码的连接。设置完你的环境和索引测试数据后,你可以下载源码,然后运行在你的机器上运行任何例子。可以通过命令行运行节点filename.js。
为了执行我们的搜索,我们将使用客户端提供的多种搜索方法。最简单的查询是match_all,它可以返回一个或多个索引的所有的记录。下面的例子显示了我们怎么样获取在一个索引中获取所有存储的记录(
源码