23年9月来自腾讯实验室、TTI和几所大学的大语言模型幻觉综述“Siren’s Song in the AI Ocean: A Survey on Hallucination in Large Language Models“。
摘要
:虽然大语言模型(LLM)在一系列下游任务中表现出非凡的能力,但一个重要的问题围绕着出现幻觉的倾向:LLM偶尔会生成与用户输入不同的内容,与先前生成的文本相矛盾,或与既定的世界知识不一致。这种现象对LLM在现实世界中的可靠性提出了实质性挑战。本文调查最近在检测、解释和缓解幻觉方面的努力,重点是LLM带来的独特挑战。文中提出LLM幻觉现象的分类法和评估基准,分析旨在减轻LLM幻觉的现有方法,并确定未来研究的潜在方向。
由于LLM的多功能性,将LLMs背景下的幻觉分类如下:
-
• 输入冲突幻觉,LLM生成的内容偏离用户提供的源输入;
-
•上下文冲突幻觉,LLM生成的内容与先前生成的信息本身冲突;
-
• 事实冲突的幻觉,即LLM生成的内容不忠实于建立的世界知识。
如图所示定义的三种LLM幻觉。对于输入冲突幻觉,LLM在总结时会把人名(Hill⇒Lucas)说错。对于上下文冲突幻觉,LLM前期讨论的是Silver,但后来变成了Stern,结果产生了矛盾。对于事实冲突幻觉,LLM说Afonso II的母亲是卡斯蒂利亚的女王Urraca,而正确答案是巴塞罗那的Dulce Berenguer。

如图是三种LLM相应中出现的幻觉例子:
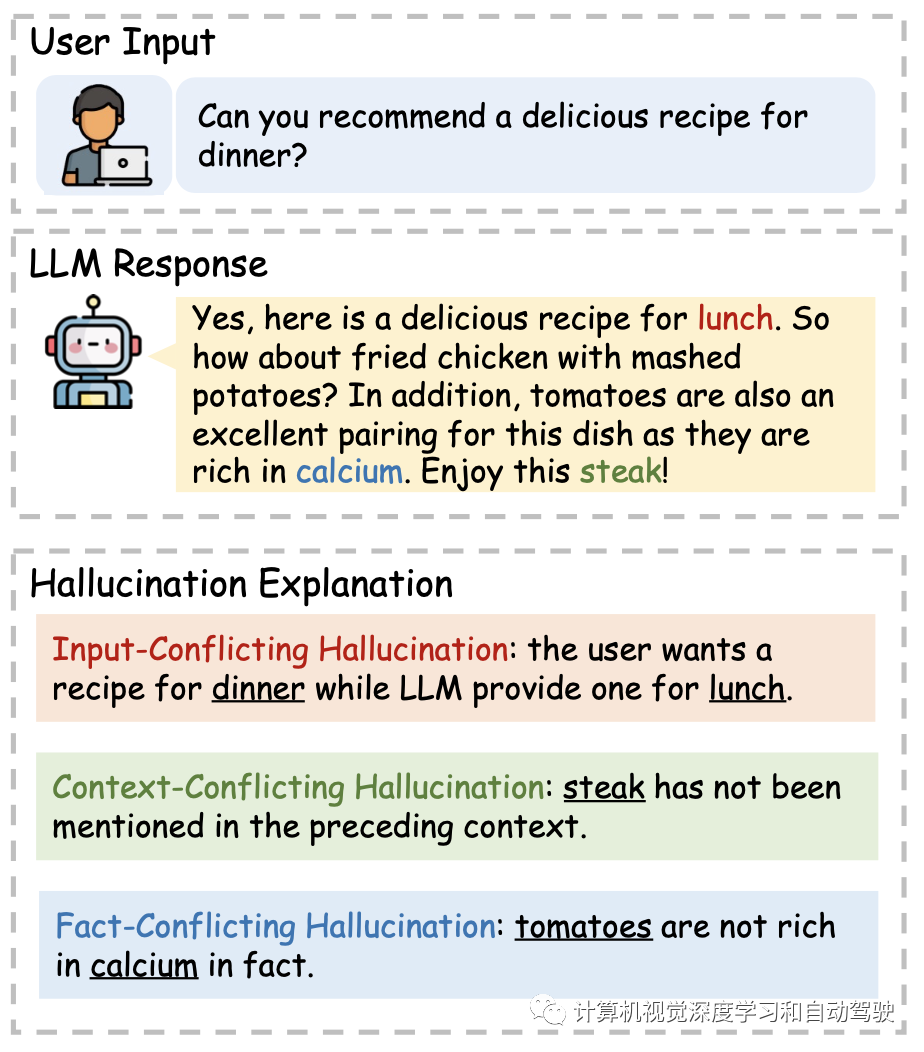
添加图片注释,不超过 140 字(可选)
如图是本文的总体结构:首先将 LLM 幻觉分为三种不同的类型,然后介绍相应的评估基准。随后,探索幻觉的来源并讨论 LLM 整个生命周期(预训练→SFT→RLHF→推理)中的缓解策略。

除了幻觉之外,LLM 还存在其他问题。
如表提供了示例,帮助读者区分它们和幻觉。

-
歧义。当 LLM 的回答含糊不清时,就会出现这种类型的问题,从而产生多种解释。答案可能不一定是错误的,但它未能为用户的问题提供有用的答案(Tamkin,2022)。表中的第一个示例说明了这个问题。期望的答案是“巴黎”,但 LLM 给出了模棱两可的回答。
-
不完整。当生成的响应不完整或不完整时,就会出现不完整问题。如表中的第二个示例所示,LLM 仅告知用户更换轮胎四步流程中的前两个步骤,导致解释不完整。
-
偏见。LLM 中的偏见涉及生成的文本中不公平或偏见态度的表现。这些偏见可能源自训练数据,这些数据通常包括历史文本、文学、社交媒体内容和其他来源。这些来源可能本质上反映社会偏见、性别偏见、刻板印象或歧视性信念 (Navigli et al., 2023)。如表中的第三个示例所示,LLM 将教师描绘成女性,这是一种性别偏见。
-
信息不足。这类问题是指 LLM 倾向于逃避回答某些问题或提供具体信息,即使他们应该能够这样做。例如,由于奖励模型的不完善,RLHF 可能导致 LLM 过度优化,从而可能导致信息不足的状态 (Gao et al., 2022)。表中给出了一个示例,其中 LLM 拒绝响应用户查询。
现有的基准主要根据 LLM 的两种不同
能力
来评估幻觉:生成事实陈述的能力,或区分事实陈述与非事实陈述的能力。
现有的基准测试在各种应用
任务
中评估 LLM 幻觉。首先,某些基准测试(Lin,2021;Li,2023a)在问答背景下探讨幻觉问题,评估 LLM 对知识密集型问题提供真实答案的能力。其次,FActScore(Min,2023)和 HaluEval(Li,2023a)使用任务指令(例如传记介绍指令和 Alpaca 项目的 52K 指令(Taori,2023))来提示 LLM 生成响应。然后这些响应的真实性被评估。第三,一项研究(Lee et al., 2022; Muhlgay et al., 2023)直接提示 LLM 给出前缀来完成文本,并在生成信息性和事实性陈述时诊断潜在的幻觉。例如,FACTOR(Muhlgay et al., 2023)考虑了 Wikipedia 文档中的上下文前缀,而 FactualityPrompt(Lee et al., 2022)专门为事实性或非事实性陈述设计前缀以引发幻觉。
如表是可用于评估 LLM 幻觉的代表性基准包括 TruthfulQA (Lin et al., 2021)、FactualityPrompt (Lee et al., 2022)、FActScore (Min et al., 2023)、KoLA-KC (Yu et al., 2023a)、HaluEval (Li et al., 2023a) 和 FACTOR (Muhlgay et al., 2023)。请注意,KoLA (Yu et al., 2023a) 旨在对 LLM 的世界知识进行基准测试,其中知识创造 (KC) 任务可用于评估幻觉。这些基准都侧重于事实性方面,但在以下方面存在分歧:“Evaluation”表示这些基准如何评估幻觉,要么将幻觉作为 LLM 生成的生成质量指标(Generation,简称 Gen),要么评估 LLM 是否能够区分事实和非事实陈述(Discrimination,简称 Dis);“Task Format”反映了提示语言模型的不同方法,例如知识密集型的问答(QA)、任务指令(TI)和用于文本补全(TC)的上下文前缀。

如表所示评估幻觉的两种方法(生成与辨别)说明性示例。

如表所示现有基准评估幻觉中任务格式的说明性示例。

上述大多数基准测试都涉及人工注释者来创建数据集或进行质量保证。
TruthfulQA(Lin,2021)精心设计了问题以引出模仿性谎言,即在训练分布上可能性很高的虚假陈述。
然后,聘请人工注释者进一步验证黄金答案的一致性。
FActScore(Min,2023)进行了手工注释流程,将长格式模型生成转换为原子语句的片段。
HaluEval(Li,2023a)采用了两种构造方法。
对于自动生成,设计提示来查询 ChatGPT 以采样多样的幻觉并自动过滤高质量的。
对于人工注释,聘请人工注释者来注释模型响应中幻觉的存在并列出相应的范围。
FACTOR (Muhlgay,2023) 首先使用外部 LLM 生成非事实补全。
然后,手工验证自动创建的数据集是否符合预定义的要求,即它们应该是非事实的、流畅的并且与事实补全相似。
为了构建知识创造任务,(Yu 2023a) 构建了一个注释平台以促进细粒度事件注释。
关于幻觉的来源:
1)LLM缺乏相关知识或错误知识内在化。在预训练阶段,LLM从大量的训练数据中积累了大量的知识,然后将其存储在其模型参数中。当被要求回答问题或完成任务时,如果LLM缺乏相关知识或从培训语料库中内在化了错误知识,通常会表现出幻觉。Li(2022c)发现LLM有时会将虚假相关性(例如位置接近或高度共存的关联)误解为事实知识。具体来说,McKenna (2023 )在自然语言推理 (NLI) 任务的背景下调查了幻觉概率,发现 LLM 幻觉与训练数据的分布之间存在很强的相关性。例如,观察到LLM偏向于肯定(affirming)测试样本,其中假设在训练数据中得到检验。此外,Dziri (2022 )认为,幻觉也存在于人类生成的语料库中,可以反映为过时的(Liska 2022;Luu 2022 )、有偏见的(Chang 2019 ; Garrido-Muñoz 2021 )、或捏造的(Penedo 2023 )解释。因此,LLM倾向于复制甚至放大这种幻觉行为。而且Zheng(2023c)确定了与知识记忆相关的另外两种能力,使LLM能够提供真实的答案:知识回忆和知识推理。这两种能力的缺陷都可能导致幻觉。
2)LLM有时会高估他们的能力。已经有一些研究,目的是了解语言模型是否可以评估其响应的准确性并识别其知识边界。Kadavath (2022 )进行的实验证明了LLM评估自己回答的正确性(自我评估)并确定他们是否知道提供给定问题答案的能力。然而,对于非常大的LLM,正确和错误答案的分布熵可能是相似的,这表明LLM在生成不正确的答案时与生成正确的答案时同样有信心。Yin (2023 )还评估了流行的LLM识别无法回答或不可知问题的能力。他们的实证研究表明,即使是最先进的LLM,GPT4(OpenAI,2023b)与人类相比,也显示出性能差距。Ren (2023 )注意到准确性和置信度之间存在相关性,但这种置信度通常超过LLM的实际能力,即过度自信。一般来说,LLM对事实知识边界的理解可能不准确,而且经常表现出过度自信。这种过度自信会误导LLM以毫无根据的确定性捏造答案。
3)有问题的对齐过程可能会误导LLM产生幻觉。LLM通常在预训练后取消对齐过程,其中可以在有关挑选的指令跟随示例接受进一步训练,使其响应与人类偏好保持一致。然而,当LLM接受预训练阶段没有获得前提性知识的指令训练时,这实际上是一个错位过程,鼓励LLM产生幻觉(Goldberg2023;Schulman2023 )。另一个潜在的问题是阿谀奉承(sycophancy),LLM 可能会产生有利于用户观点的响应,而不是提供正确或真实的答案,这可能会导致幻觉(Perez 2022; Rad-hakrishnan 2023 ;Wei2023b)。
4)LLM采用的生成策略具有潜在风险。当今最先进的LLM按顺序生成响应,一次输出一个token。Zhang(2023a)发现LLM有时会过度承诺他们早期的错误,即使他们认识到自己是不正确的。换句话说,LLM可能更喜欢滚雪球般(snowballing)的幻觉来实现自我一致性,而不是从错误中恢复过来。这种现象被称为幻觉滚雪球。Azaria & Mitchell(2023 )还认为,局部优化(token预测)并不一定能确保全局优化(序列预测),早期的局部预测可能会导致 LLM 陷入难以形成正确响应的境地。Lee (2022 )强调,基于采样的生成策略(例如 top-p 和 top-k)引入的随机性也可能是幻觉的潜在来源。










