
[ 导读 ]
本讲座选自国际数据管理协会中国分会主席
胡本立
于近日在
“数据与认知—数据后面的科学”
高端学术研讨会上所做的题为
《数据在人-机完全不同工作机制下如何协同处理的一些思考》
的演讲。
结合这次会议的主题,我想回归基础谈下我对现在我们几乎每天和到处在讲的‘数据’(包括大数据)究竟是什么的看法,它的产生(自然界的和人的),人对它的理解和使用,和它与人认知的关系,提出一些相关的观点,与大家交流讨论。

结合这次会议的主题,我想回归基础谈下我对现在我们几乎每天和到处在讲的‘数据’(包括大数据)究竟是什么的看法,它的产生(自然界的和人的),人对它的理解和使用,和它与人认知的关系,提出一些相关的观点,与大家交流讨论。
1. 随着近年来大数据、人工智能、认知科学、脑神经科学等领域的进展,现在看到的,听到的,触到的,讲的,写的,画的都是数据,数据被大大地广义化了。随着数据的广义化,我们对‘数据’究竟是什么的理解,和对它应如何处理,管理和治理等,也在变化。
2. 看下下面这张图
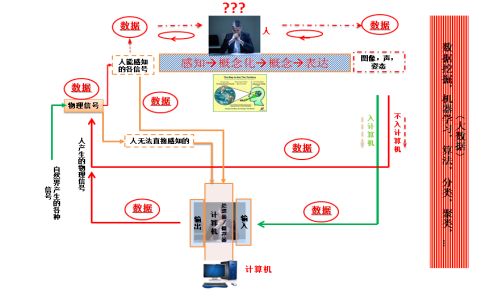
这图概括地描述了作为物理信号的数据在人-机间不断循环的过程,对人来讲数据就是生理上的刺激,然后经过感知、认知成为概念,产生思维,然后在需要表达时,通过手写,口说,姿态等形式或形态产生了新的物理信号,不断循环。可以说就是这人与数据循环互动的认知过程使我们不断认识和改变了我们的世界。
从数据源来说,数据有自然界产生的和人产生的。对它们的处理和所面临的挑战有所不同。对人产生的数据,不可避免多少包含了人的因数。要解决数据管理的深层次困难,如一直在讲的数据孤岛和跨领域数据难以共享等问题,我们仍面临与人认知有关的基础性挑战,需要对数据究竟是什么,它后面的科学即人与数据互动的认知过程,有进一步的了解和认识。
数据不断被产生和使用的循环存在在几个不同的世界中,如人脑内和脑外的世界。人脑内的又可分为物理的和主观的世界。人脑外的数据,不管是自然界产生的还是人产生的,都是物理的。不过对人产生的数据来讲,虽它们本身也是物理的客观存在,但这不等于产生它的过程和对它的理解都是客观的,相同的,最简单的如看到一只现实世界中的狗和看到‘狗’这字,这对所有人来讲都是二个各不同的认知过程,另外对不同人由于他们对狗的不同经验或经历,对‘狗’的理解也会不完全相同。
请看下图:
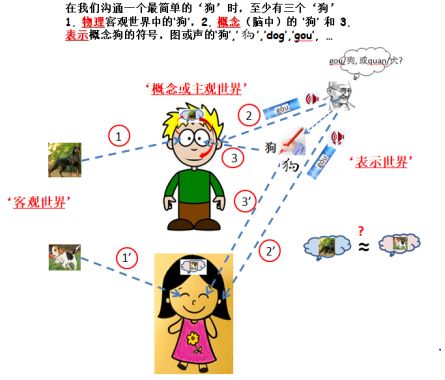
这图里有三个‘狗’;一个是在物理客观世界中存在的狗,狗产生了人能感知的光或声等信号,属强客观数据; 一个是人脑中对狗形成的记忆,概念和相关思考;一个是人用来表示狗的符号或图(如‘狗’,‘
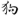 ’, ‘
’, ‘
 ’)、声音(gou,dog)等,第三个也是物理的,但是人产生的,虽与第一个有映射关系但不同。
’)、声音(gou,dog)等,第三个也是物理的,但是人产生的,虽与第一个有映射关系但不同。
接下来请大家进一步思考上图中那男孩与女孩对狗的记忆,概念,经验,和以后对狗的表示和描述会是完全一样的吗?如不完全一样他们在什么情况下对狗的沟通不会有问题,什么时候会有困难?为什么。
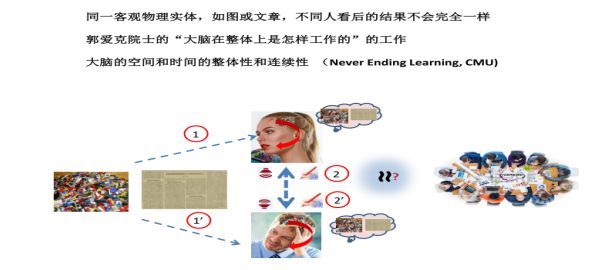
大脑对数据的记忆和处理在空间和时间上是整体的,连续的和可塑的。郭院士早些在他的主题演讲,“大脑在整体上是怎样工作的”,已从多方面给我们做了全面的介绍和解释。现在的概念,思考和表示与过去的经历、知识甚至意识有着复杂时空和整体上的联系和连续性。人对于概念的表示,如同一个词,不同人对它的理解不会完全一样,甚至会完全不同,就是这个原因。这是很困难的数据管理问题,机器不大可能来模拟和帮助解决。理论上讲如机器真能‘学习’和模拟好某个人的话,它得与这人自出身起就开始一起‘学习’同样的数据。卡內基梅隆大學计算机系有个人工智能项目称Never-Ending Learning。
理解了这些就能理解为什么一个群体对各种问题要达成完全共识是个很困难的问题,这需要不断的沟通和不断的求同存异。
3.数据的交叉和数据共享
近年来越来越多的学科需要交叉发展的趋势明显,许多发明或创新也常发生在学科交叉的领域。控制论提出者维纳觉得“科学边界的交叉区域为合格的研究人员提供了最丰富的机会”,同时,他指出了交叉带来的问题和困难,如那些跨学科术语上的混乱,很像我们今天所面临的现状。这过程不大可能避免,只能通过稍有序些的沟通来发现区别和达成需要的新的共识。

目前我们在讨论不同领域间的数据交换和共享时往往谈的只是数据本身的交换和共享。但需理解这只是一部分,除了数据本身外还需同时交换对交换数据的定义,甚至产生的场景,二者缺一不可。更完整地讲,不管意识了没,这还涉及了交换双方脑中的概念思维和对它们的语言表示的复杂认知过程。
上面提了人产生的数据只是脑中概念的脑外表示,在数据的交换(共享)过程中接受方能接受到的,往往仅是这些数据本身。要接受方与提供方对交换数据有一致的理解首先需要提供方对相关概念尽可能准确的表达或表示,同时还要看交互双方对所交换数据的应用场景是否一样或类同,这需要双方在所交换的数据外有进一步的沟通和确认。
要双方对交换数据有相同的认识要比我们现在一般认为的数据共享要复杂得多,我们希望通过这次研讨对这全过程有个跨学科的初步交流和认识。
4. 数据的关联,和关联的交叉
先谈下数据关联技术的演进 - 从主要关注数据关联如何被计算机储存和检索到更注重对数据关联的语义表示(模型),从关系型数据库,数据仓库到知识图谱,从结构化数据到非结构化数据等。这些技术的进展虽还没达到能用自然语言来描述和表达关联的丰富程度,它们与人的思考和表达习惯越来越接近。人的语言有它的丰富性但同时也有它的不确定性和含糊性,这只有人能较好的理解和处理,机器很难。
人对抽象概念的关联,尤其是跨领域的认知关联,的能力远不是机器所能达到或取代的。我这里引用杨振宁教授在他的一次发言 - “20世纪数学与物理的分与合”作为例子 - “吴大峻和我合作一篇文章,用物理学的语言,解释电磁学与数学家们的纤维丛理论的关系,文章中我们列出了一个表,是个“字典”。表中左边是物理规范常用术语,右边是纤维丛术语。”

杨和吴把物理电磁学中的概念表示与数学纤维丛中的概念表示交叉关联,但从上图中可看到这种对映关联不是简单和表面上数据间的直接对映,而是经过人脑及其复杂、高度抽象的认知关联,把物理学和数学表面上看来完全不同的概念表示关联了起来。这是人厉害的能力和地方,包括如顿悟,类似的例子科学史中不少,尽管对它们发生的机制和过程还很不了解。这虽是个著名科学家间很抽象和跨度很大关联的例子,我们每个普通人在不同程度上都有与机器很不同的关联能力。
对在数据时代的任何学科来讲,数据科学/管理与认知科学是带有基础性的二门学科。首先所有学科和行业都理解数据对它们的重要,它们的进展和发明都有赖高质量和大量的数据。数据管理不但需要理解如何更好地与各领域和业务的结合,也要为跨领域和行业的数据交叉关联提供相关的方法论,技术,工具和服务,这需要对数据科学/管理与认知科学,和它们间的关系,有一定基本的了解。我这里带来了二本书,一本是数据管理领域的,是国际数据管理协会(DAta MAnagement Association International, 简称 DAMA)刚出第二版的‘数据管理知识体系’(第一版已翻成中文出版)总结了在数据管理领域多年来累积的知识和经验。


另一本,是认知科学领域的,是蔡署山教授编著出版的‘人类的心智与认知:当代认知科学重大理论与应用研究’.






