用 10 周时间,让你从 TensorFlow 基础入门,到搭建 CNN、自编码、RNN、GAN 等模型,并最终掌握开发的实战技能。4 月线上开课,
www.mooc.ai
现已开放预约。
雷锋网按:
网络直播行业经历了过去两年的井喷式爆发后,到现在依旧保持着持续火热的态势。但这一市场火爆的背后也一直暴露了一些问题,低俗内容屡见不鲜。显然,要解决这一问题就必须要有比人工鉴黄效率更高的手段,用人工智能技术来鉴黄就是现在直播平台通用的手段。
虽然不少企业都把目光聚焦在视频鉴黄上,但音频审核也是人工智能鉴黄技术的一部分,二者缺一不可。那在大家熟悉的视频鉴黄之外,音频检测究竟能解决哪些问题?这一技术是如何进行鉴黄的呢?
本期雷锋网硬创公开课,我们邀请了极限元智能科技联合创始人马骥为大家解读关于音频审核背后的技术。
嘉宾介绍

马骥:极限元智能科技联合创始人
,曾先后就职于中科院软件研究所、华为技术有限公司,获得多项关于语音及音频领域的专利,资深软件开发工程师和网络安全解决方案专家,擅长从用户角度分析需求,提供有效的技术解决方案,具有丰富的商业交流和项目管理经验。
以下内容整理自本期公开课,雷锋网做了不改变原意的编辑:
一、音视频审核的需求现状
音视频审核主要针对互联网传播的信息进行审核,审核的内容有有害信息(涉黄、涉暴)、敏感信息。
以直播平台为例,2016年,是互联网直播平台爆发的一年,除了各式各样的直播形式。与此同时,也出现了大量的在线实时信息,这其中是有害信息,涉黄是最为严重的一个现象。今年,相关部门已经针对这些乱象加大了打击力度,因此基于互联网直播平台的有害信息检测成为重中之重。
以图像识别技术为基础如何进行鉴黄?在直播的时候,每个直播间会间隔一秒或几秒采集一个关键帧,关键帧会发送到图像识别引擎,引擎根据图像的颜色、纹理等等特征来对敏感图像进行过滤,这一过程会检测肢体轮廓等关键特征信息,然后对检测图像特征与特征库模型里面的特征相似度进行匹配,给予待测图像色情、正常、性感等不同维度的权重值,以权重值最高的作为判定结果输出。
基于图像识别得视频涉黄检测准确率可以达到99%以上,可以为视频直播平台节省70%以上的工作量。
还有一些是语音为主的直播节目,比如谈话聊天、脱口秀、在线广播等。视频检测所使用到的图像技术就很难在这些应用场景发挥作用,所以音频检测需要有针对性的技术手段。
除了刚刚提到的几个音频检测应用场景之外,例如网络音视频资源审核,例如微信发布语音视频信息,平台后台会对这些数据进行审核;另外公安技侦通过技术手段来侦查网络、电话犯罪行为;第三个是呼叫中心,传统呼叫中心会产生大量的电话录音,很多行业会对这些录音进行录音质检,从这些录音中提取业务开展的情况;最后一个是电信安全,主要是以关键词检索的手段来防止电信诈骗。
二、音频检测采用的技术手段
音频可以分为有内容和无内容两种:说话内容相关的包括说了什么?(涉政、涉黄、涉赌还是广告信息),另外还可以从说话内容来判断语种以及说话人的辨识;此外还有与说话内容无关的信息,例如特定录音片段、歌曲旋律、环境音等等。
针对不同的数据类型有不同的检测技术。针对说话内容有语音识别、关键词检索等;针对语种的判别有语种识别的技术;针对说话人的识别有声纹识别技术;针对说话内容无关的通常采用音频比对的技术来进行检测。
语音识别的关键技术——声学模型
语音识别的声学模型主要有以下两种:混合声学模型和端到端的声学模型。
混合声学模型通常是隐马尔科夫模型结合混合高斯、深度神经网络、深度循环神经网络以及深度卷积神经网络的一个模型。
端到端声学模型目前有两大类,一是连接时序分类—长短时记忆模型,二是注意力模型。
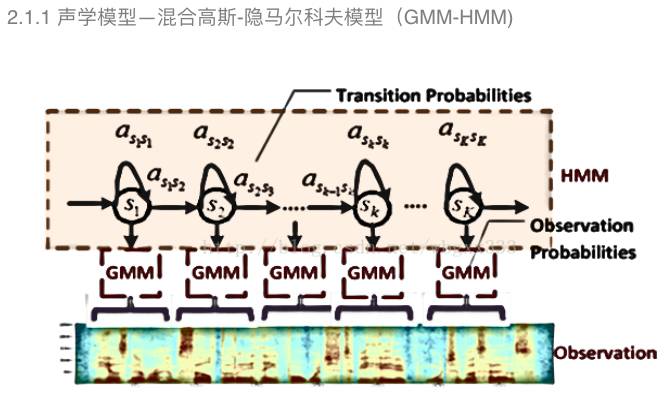
混合高斯—隐马尔科夫模型是根据语音的短时平稳性采用采用隐马尔科夫模型对三因子进行建模。图中显示的是,输入语音参数通过混合高斯模型计算每一个隐马尔科夫模型状态的后验概率,然后隐马尔可夫模型转移概率来描述状态之间的转移。
混合高斯—隐马尔科夫模型是出现最早应用最久远的模型。
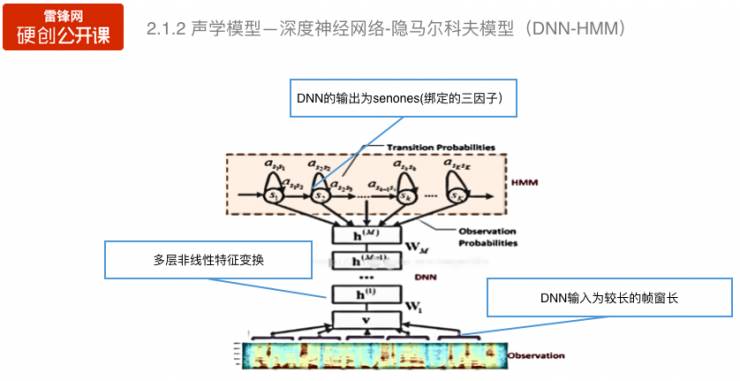
混合神经网络—隐马尔科夫模型是将混合高斯模型用深度神经网络进行替代,但是保留了隐马尔科夫的结构,对于输入端的扩帧和深度神经网络的非线性变换,识别率可以得到很大的提升。
前面的深度神经网络对历史信息的建模只是通过在输入端扩帧实现的,但对历史信息的建模作用是有限的。
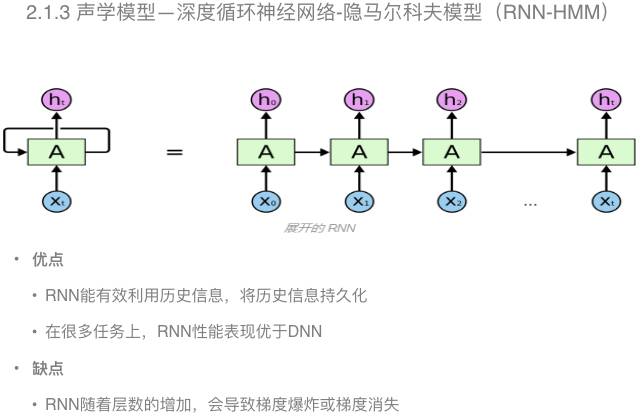
在深度循环神经网络中,对输入的历史信息可以进行有效的建模,可以做大限度的保留历史信息。根据现有的实验结果来看,在很多任务上,深度循环神经网络性能表现要由于深度神经网络。
当然,深度循环神经网络也存在一些缺点。例如,在训练的时候,会出现梯度爆炸和梯度消失的问题。
那么如何有限解决梯度爆炸和梯度消失的问题呢?学者又引入了一种长短时记忆模型。
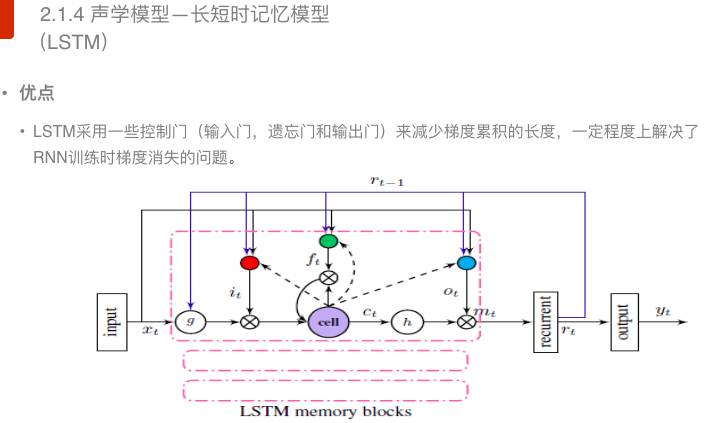
长短时记忆模型采用控制门(包括输入门、遗忘门和输出门)将梯度累积变成梯度累加,在一定程度上可以解决深度循环神经网络训练时梯度消失的问题。
上面提到的深度循环神经网络能够有效地对历史信息进行建模,但是它存在计算量太大的问题,特别是为了减少这种梯度消失又引入了长短时记忆模型之后,计算的信息量有加剧。应对这一难题,业界又引入了深度卷积神经网络模型。
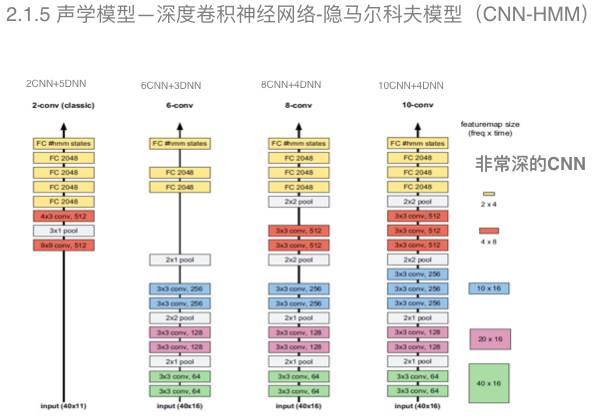
这种模型在图像识别领域和语音识别领域都得到了显著的效果。
在语音识别领域,我们可以从图中可以看出,一共有四种深度神经网络的模型结构,随着深度的增加可以有效地提升声学模型的构建能力。
前面提到的都是基于混合模型,以隐马尔科夫模型来构建转换概率的模型。
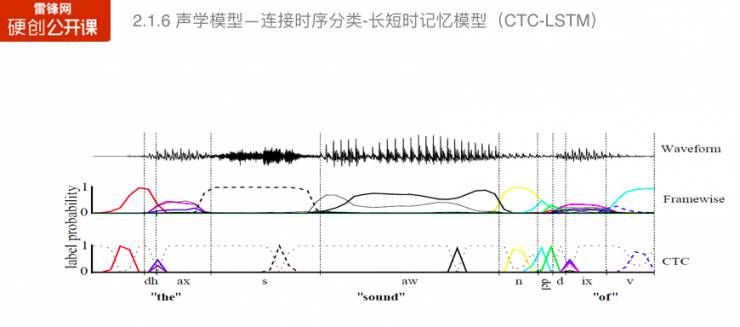
在训练过程中,如果要用到高斯混合模型进行强制对齐结果的训练。针对这个问题,也有学则提出了不需要强制对齐的训练方法,例如连接时序分类(CTC),这种方法可以有效加速解码速度。
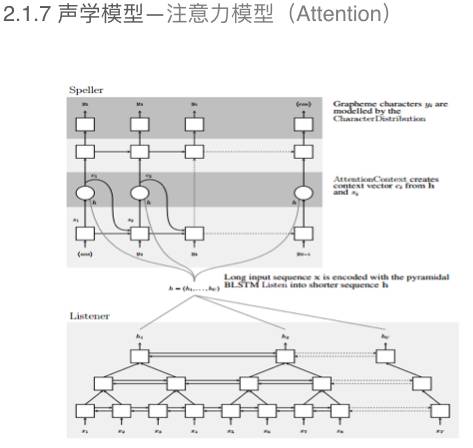
另外一种不需要强制对齐的训练方法是注意力模型的训练方法(如上图)。
语言模型
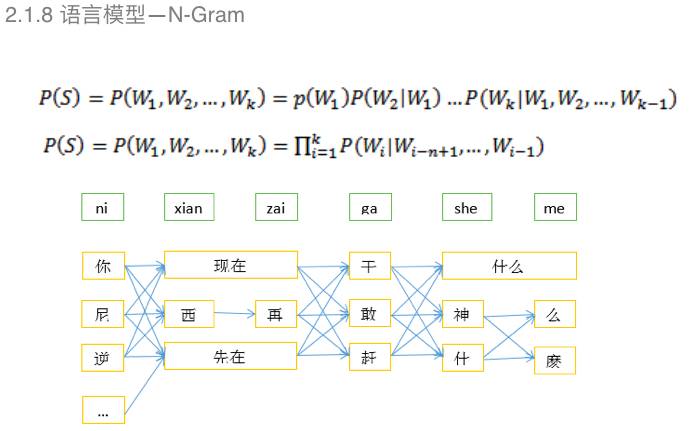
基于N-Gram的特点是每个词出现的概率,之和前面第N-1个词有关,整句话出现的概率是每个词出现的概率的乘积。
N-Gram有一个缺点,由于数据稀缺性需要进行一个平滑算法,然后得到后验概率。
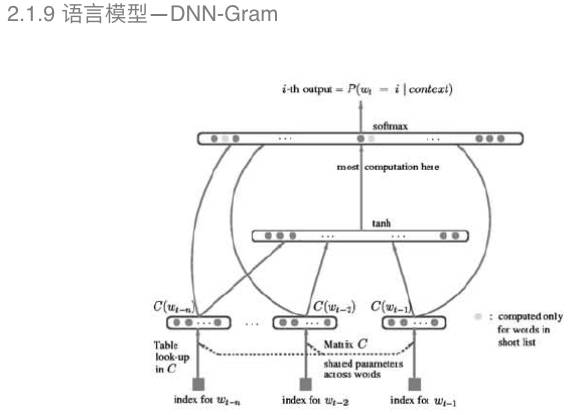
DNN-Gram把深度神经网络引入可以有效地克服平滑算法的误差。例如图中显示的,通过深度神经网络构建语音性不需要平滑算法的处理。
和声学模型一样,构建语言模型也需要对历史信息进行训练建模,在声学模型中提到的深度循环神经网络在这里也有应用。
基于深度神经网络的语言模型每个词出现的概率和N-Gram一样,只是和向前的第N-1个词有关,但实际上,每个词出现的频率和之前所有词都有相关性,因此需要引入历史信息进行训练建模。
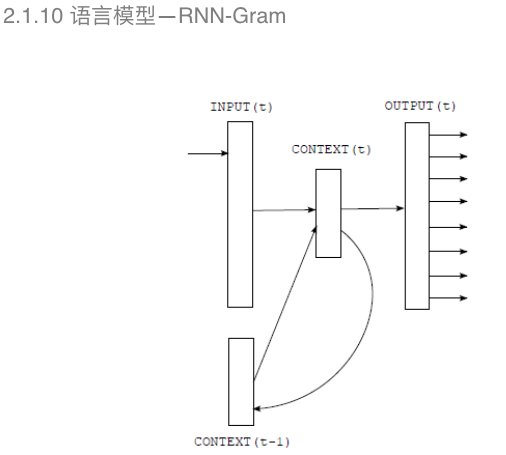
所以在这里加入了RNN-Gram进行语言模型的构建。
近几年,语音识别的声学模型和语言模型都得到了很大的提高。2016年,微软的语音识别团队宣称在swithboard数据集上超过了人类,swithboard数据集是一个以口语为主的训练测试数据集,包含了大量的副语言,所以用这种数据集进行语音识别测试具有一定的挑战性。
不过,语音识别在一些特殊领域的识别效果就大打折扣了。在强干扰环境和特殊领域中,可以通过基于语音识别的关键词检索方法来进行音频信息的检查。
基于语音识别的关键词检索
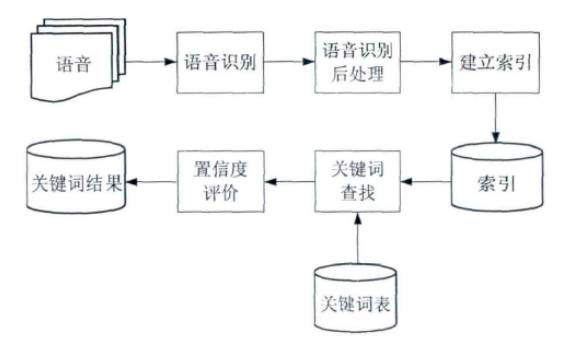
基于语音识别的关键词检索是将语音识别的结构构建成一个索引网络,然后把关键词从索引网络中找出来。从这一流程图中可以看到,首先把语音进行识别处理,从里面提取索引构建索引网络,进行关键词检索的时候,我们会把关键词表在网络中进行频率,找到概率最高的,输出其关键词匹配结果。
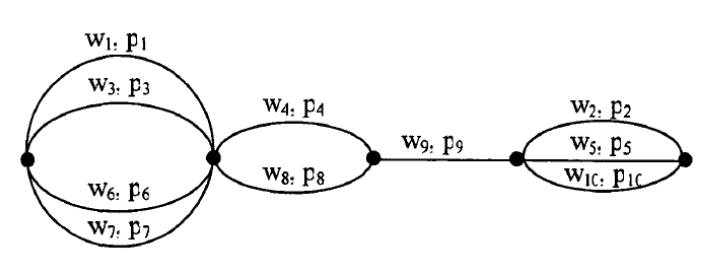
构建检索网络是语音关键词检索的重要环节。在这个图中,在第一个时间段内(w1、w3、w6、w7),这句话被识别成了四个不同的词,语音识别只能给出一条路径,但在语音关键词检索网络中可以从四个结果中进行筛选。
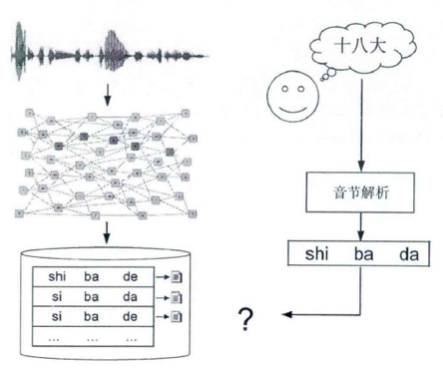
有了检索网络后,接下来的工作就是关键词检索工作。关键词检索是基于音节数据,首先将用户设定的关键词文本解析成音节数据,再从检索网络中找出匹配结果,相比语音识别这种文本结果检索,这种容错性更强,而且关键词检索可以只用在基于CTC,计算量更小,执行效率更高,更适用于海量数据的检索场景。
说话人识别的关键技术
说话人识别也称之为声纹识别,主要目的是对说话人的身份确认和辨识。
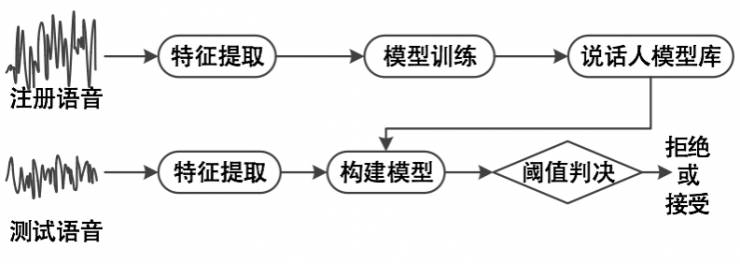
它的流程如下:首先对说话人的训练建模,把注册语音进行特征提取,模型训练之后得到说话人的模型库;在测试的时候,我们需要通过一个很短的音频去提取特征值,然后基于之前构建的模型进行阈值判断,判断出是集合内还是外,最终确认身份。
在这一过程中,注册语音只要10s左右的语音,测试只要2-5s的语音。
MFCC(梅尔频率倒谱系数),梅尔频率是基于人耳听觉特性提取出来的,和赫兹频率呈现一个非线性对应关系。梅尔频率倒谱系数是利用好梅尔频率和赫兹频谱关系计算得出的赫兹频谱特征,其主要应用于语音数据的特征提取。
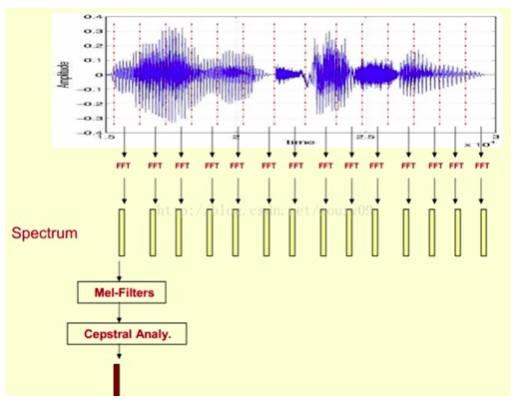
这张图显示的就是MFCC的提取过程,输入语音进行傅里叶变换,从中得到频谱,然后通过梅尔滤波器进行倒谱分析,再得到MFCC系数。
MFCC是浅层的特征,只要通过语音参数的分析就可以得到,但是说话人之间不同的特征还体现在其它特点上,仅通过MFCC是无法捕捉到的。





