5月18日,由CSDN出品的
2017中国云计算技术大会
(简称CCTC,Cloud Computing Technology Conference)在北京盛大召开,第四范式机器学习算法研发工程师涂威威出席人工智能专场并作主题演讲。
作为第四范式•先知平台核心机器学习框架GDBT的设计者,涂威威在大规模分布式机器学习系统架构、机器学习算法设计和应用等方面有深厚积累。演讲中,涂威威表示,现在有越来越多的企业开始利用机器学习技术,把数据转换成智能决策引擎。企业机器学习应用系统中的核心模型训练系统有着什么样的设计和优化的考虑?与教科书中的机器学习应用相比,企业实际的机器学习应用中有哪些容易被人忽略的陷阱?涂威威对此作了经验分享,同时给出了一些可供参考的解决方案。
工业界大规模分布式
机器学习计算框架的设计经验
机器学习的经典定义,是利用经验(数据)来改善系统性能。在应用过程中,首先要明确机器学习目标的定义,也就是用机器学习来做什么事情。以谷歌提升搜索广告业务收入为例,谷歌首先对提升收入的目标进行拆解,广告收入=平均单次点击价格点击率广告展现量,其中“广告展现量”被硬性控制(考虑到政策法规和用户体验),“单次点击价格”受广告主主动出价影响,与上面两者不同,“点击率”的目标明确,搜索引擎记录了大量的展现点击日志,而广告候选集很大,不同广告的点击率差别很大,谷歌广告平台有控制广告展现的自主权,因此对于谷歌提升搜索广告收入的问题而言,机器学习最适合用来优化“广告点击率”。
在确定了机器学习具体的优化目标是广告点击率之后,谷歌机器学习系统会循环执行四个系统:数据收集→数据预处理→模型训练→模型服务(模型服务产生的数据会被下一个循环的数据收集系统收集)。在这四个系统中,与机器学习算法最相关的就是模型训练系统。
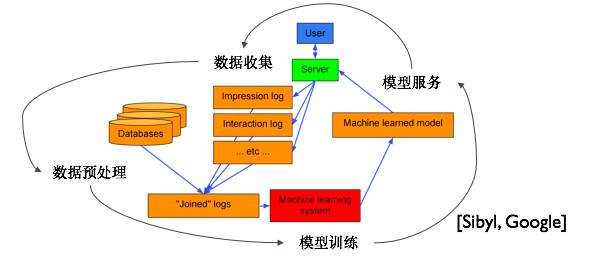
在涂威威看来,计算框架设计上,没有普适的最好框架,只有最适合实际计算问题的框架。
针对机器学习的兼顾开发效率和执行效率的
大规模分布式并行计算框架
在工业应用中,有效数据、特征维度正在迅速攀升。在数据量方面,以往一个机器学习任务仅有几万个数据,如今一个业务的数据量已很容易达到千亿级别。在特征维度方面,传统的机器学习采用“抓大放小”的方式—只使用高频宏观特征,忽略包含大量信息的低频微观特征—进行训练,但随着算法、计算能力、数据收集能力的不断增强,更多的低频微观特征被加入到机器学习训练中,使模型的效果更加出色。

特征频率分布
机器学习技术也在工业应用中不断发展,最早期的机器学习工业应用只利用宏观特征、简单模型,到后来发展为两个不同的流派:以微软、雅虎为代表的只利用宏观特征但使用复杂模型流派,以谷歌为代表的使用简单模型但利用微观特征流派,到现在,利用更多微观特征以及复杂模型去更精细地刻画复杂关系已是大势所趋。这便对模型训练提出了更高的要求。
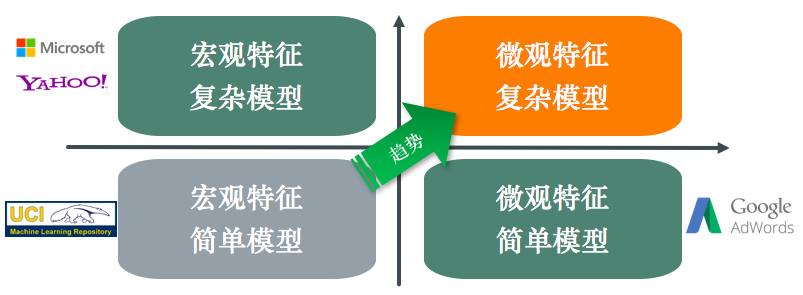
其一,训练系统需要分布式并行。由于功率墙(Power Wall,芯片密度不能无限增长)和延迟墙(Latency Wall,光速限制,芯片规模和时钟频率不能无限增长)的限制,摩尔定律正在慢慢失效,目前,提升计算能力的方式主要是依靠并行计算,从早期的以降低执行延迟为主到现在的以提升吞吐量为主。在模型训练的高性能计算要求下,单机在IO、存储、计算方面的能力力不从心,机器学习模型训练系统需要分布式并行化。当然我们也需要牢记Amdahl定律。
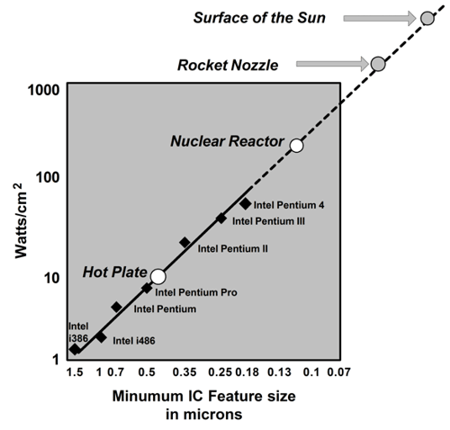
Power Wall,功耗随着集成电路密度指数提升
其二,训练框架需要高开发效率。机器学习领域里,一个著名的定理叫No Free Lunch[Wolpert and Macready 1997],是指任意算法(包括随机算法)在所有问题上的期望性能一样,不存在通用的算法,因此需要针对不同的实际问题,研发出不同的机器学习算法。这就需要机器学习计算框架的开发效率非常高。
典型的机器学习建模过程
其三,训练系统需要高执行效率。在面对实际问题时,需要对数据、特征表达、模型、模型参数等进行多种尝试,且每一次尝试,都需要单独做模型训练。所以,模型训练是整个机器学习建模过程中被重复执行最多的模块,执行效率也就成为了重中之重。
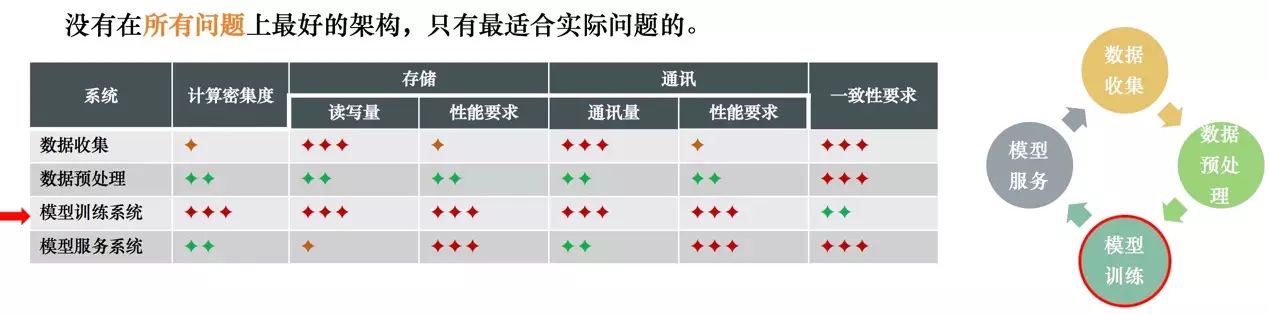
机器学习核心系统对计算资源的需求对比
其四,底层框架的No Free Lunch。对于不同的计算问题,计算的模式和对各种计算资源的需求都是不一样的,因此没有在所有问题上最好的架构,只有最适合实际问题的架构。针对机器学习任务的特性进行框架设计才能更有效地解决大规模机器学习模型训练的计算问题。
开发效率的优化
在提高开发效率上,这里分享计算和编程模式的选择、编程语言的选择两个方面。
并行计算范式分为两种,一种是基于共享内存的并行计算范式,不同的计算节点共享同一块内存,这里底层需要处理访存冲突等问题,这种模式一般被用在小规模处理器的情况,比如单机多处理器;另外一种是基于消息传递的并行计算范式,每个计算节点使用自己的内存,计算节点之间通过消息传递的模式进行并行计算。在实际的分布式并行系统中,多机器之间一般基于消息传递,单机内部一般基于共享内存(也有一些系统基于消息传递)。
机器学习的分布式模式,又分为数据分布式和模型分布式。数据分布式是指将训练数据切成很多份,不同的机器处理一部分数据。但对于一些较大的模型,单机可能没有办法完成整个模型的运算,于是把模型切成很多份,不同机器计算模型的不同部分。在实际应用过程中,根据不同的场景需要,二者一般是并存的。

数据分布式和模型分布式
机器学习模型训练中常见的
分布式并行计算模型
最常见的就是分布式数据流计算模型。数据流模型是一种数据驱动的并行计算执行模型。数据流计算逻辑基于数据流图表达。 用户通过描述一个计算流图来完成计算,对计算流图中的计算节点进行定义,用户一般不需要指定具体执行流程。数据流图内部不同数据的计算一般是异步完成的,其中的计算节点只要上游ready就可以执行计算逻辑。
目前主流的ETL(Extract-Transform-Load)数据处理框架比如Hadoop、Spark、Flink等都是基于数据流计算模型。但是机器学习计算任务有一个共享的不断被擦写的中间状态:模型参数,计算过程会不断的读写中间状态。数据流的计算模型在执行过程中一般是异步的,所以很难对共享中间状态——模型参数,进行很好的一致性控制。所以基于数据流计算模型的一致性模型一般都是同步的,在数据流内部保证强一致性,但是基于同步的系统执行性能取决于最慢的计算节点,计算效率比较低。
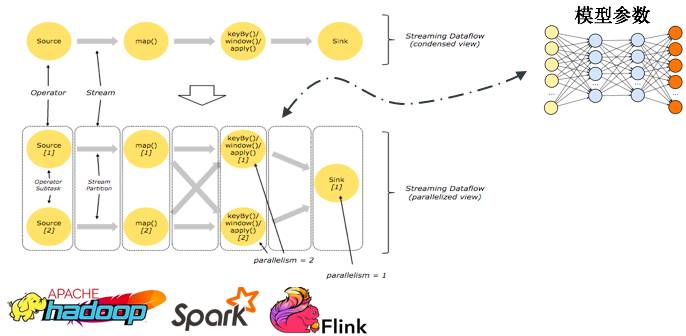
数据流计算模型中的模型参数困惑
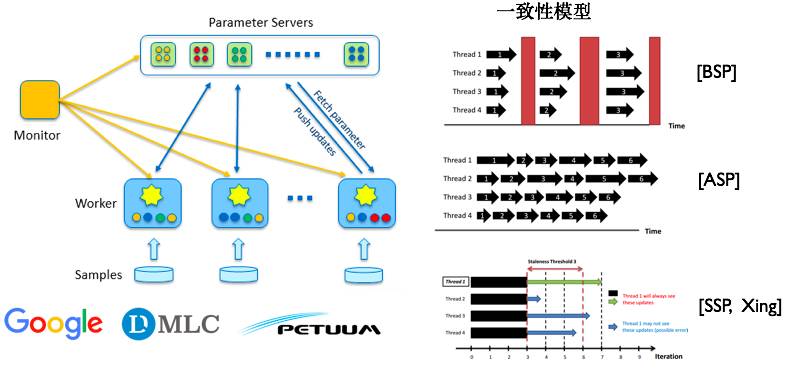
另一个常见的分布式并行计算模型就是基于参数服务器的分布式计算模型。参数服务器就是对机器学习模型训练计算中的共享状态——模型参数管理的一种直观的抽象,对模型参数的读写由统一的参数服务器管理,参数服务器本质上就是一个支持多种一致性模型的高性能Key-Value存储服务。
基于参数服务器可以实现不同的一致性模型,一个极端就是BSP(Bulk Synchronous Parallel,同步并行),所有的计算节点在计算过程中都获取一致的模型参数,对于算法实现而言有一致性的保障,但是代价是同步造成的资源浪费;另一个极端是ASP(Asynchronous Parallel,异步并行),所有的计算节点在计算过程中彼此之间的模型参数没有任何的一致性保证,计算节点之间完全异步执行,这种一致性模型计算效率很高,但是模型参数没有一致性保证,不同节点获取到的是不同版本的模型,训练过程不稳定,影响算法效果.
CMU的Erix Xing教授提出了介于BSP和ASP两者之间的SSP(Stale Synchronous Parallel),通过限制最大不一致的参数版本数来控制整体的同步节奏,这样既能缓解由于同步带来的执行效率问题,又使得算法相对于ASP在收敛性质上有更好的保证。基于不同的一致性模型可以很好地在运行速度和算法效果上进行权衡。
其实,数据流计算模型和参数服务器计算模型刻画了机器学习模型训练计算过程的不同方面,机器学习的样本数据的流动用数据流来描述就很自然,模型训练过程中的中间状态可以被参数服务器计算模型自然的描述。因此,这两者进行结合是整体的发展趋势:在数据流中对参数服务器进行读写操作,比如Intel就开发了Spark上的参数服务器。
但是数据流计算模型和参数服务器计算模型的一致性模型不尽相同,参数服务器的一致性模型比如BSP或者SSP都会打破数据流原有的异步计算逻辑。参数服务器和数据流结合的灾备策略和一致性管理策略需要仔细的设计才能很好地统一和融合。
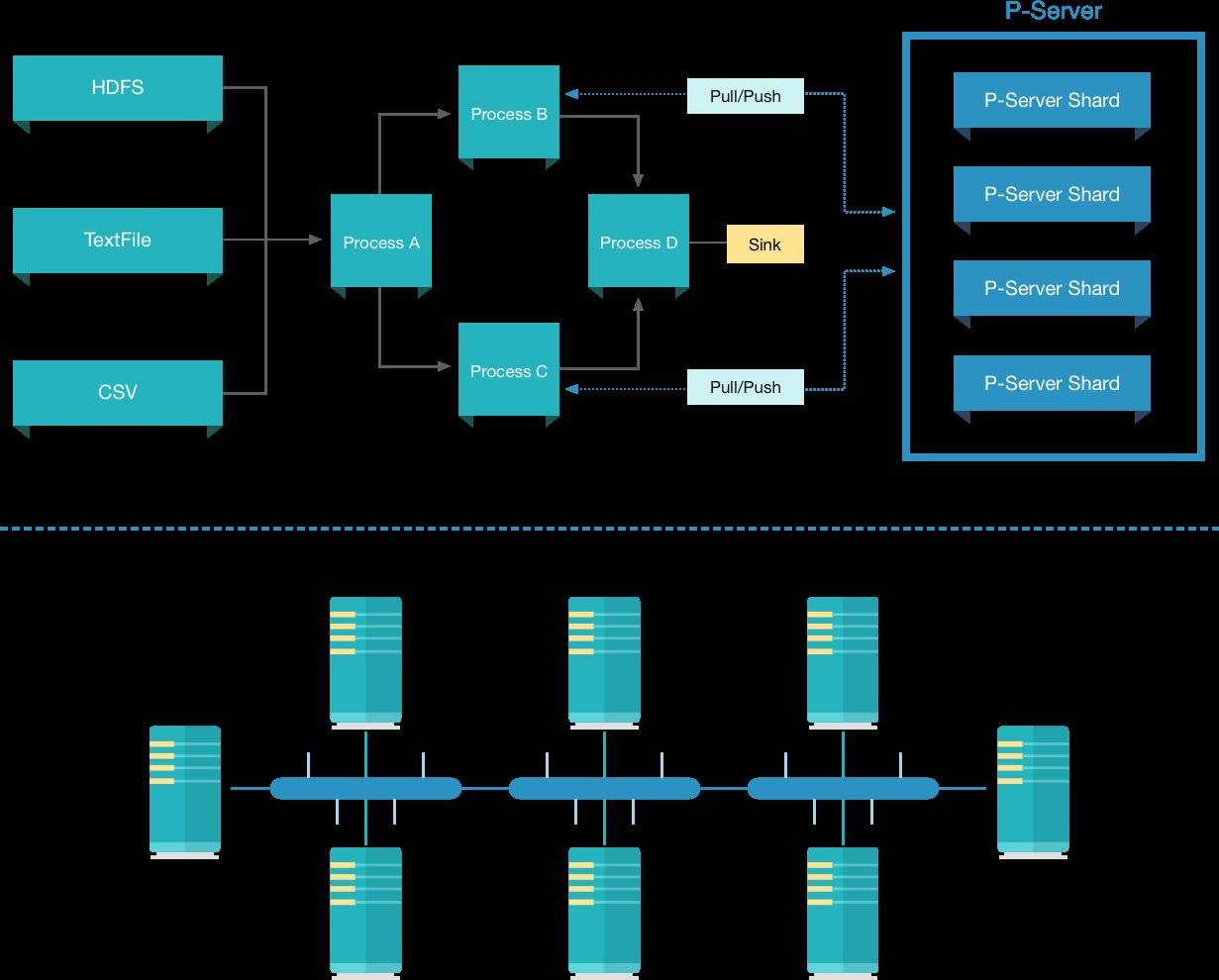
数据流和参数服务器结合的架构
编程模型和编程语言的选择
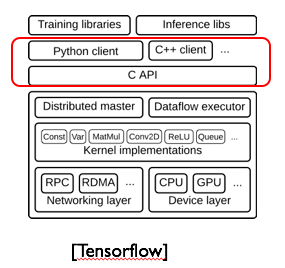
编程范式可以分为两种,命令式与声明式。命令式编程通过显式指定具体执行流程来进行编程,常见的命令式语言是C/C++等;与命令式编程不同,声明式编程不显示指定具体执行流程,只定义描述计算任务目标,将具体执行交由底层计算框架决定。命令式编程由于显式指定具体执行流程会显得更加灵活,而声明式编程底层计算框架可以针对执行流程进行更深入的优化从而可能会更加高效。在实际的机器学习模型训练计算框架中,两者其实一般是并存的,比如MxNet、Tensorflow等。

求和运算的命令式实现和声明式实现比较
为了兼顾运行效率和易用性,机器学习模型训练计算框架的编程语言的选择一般采用前后端分离的方式:以C/C++、Java/Scala等作为后端以保证系统运行效率,使用Python、R等作为前端以提供更为易用的编程接口。对于后端语言的选择上,主流的就是Java和C++,这两者各有优劣:
-
在生态上,Java由于易于开发使得其生态要远远好于C++,很多大数据计算框架都基于Java或者类Java语言开发;
-
在可移植性上,由于JVM屏蔽了很多底层差异性,所以Java要优于C++;
-
在内存管理上,基于GC的Java在大数据、同步分布式并行的情况下,效率要远低于优化过的C++的效率,因为大数据情况下,GC的概率会很高,而一旦一台服务器开始GC其计算能力将受很大影响,整体集群尤其在同步情况下的计算效率也会大打折扣,而机器数增加的情况下,在一定时刻触发GC的概率也会大大增加;
-
在语言抽象上,C++的模板机制在编译时刻进行展开,可以做更多的编译优化,在实际执行时除了产生的程序文件更大一些之外,整体执行效率非常高,而与之对应的Java泛型采用类型擦除方式实现,在实际运行时做数据类型cast,会带来很多额外的开销,使得其整体执行效率受到很大影响。
在实际机器学习模型训练系统的设计上,具体的选择取决于框架设计者的偏好和实际问题(比如系统部署要求、开发代价等)的需求。
执行效率的优化
执行效率优化方面主要举例分享计算、存储、通讯、容错四个方面的优化。
在计算方面,最重要的优化点就是均衡。均衡不仅包括不同的机器、不同的计算线程之间的负载均衡,还包括算术逻辑运算资源、存储资源、通讯资源等等各种与计算有关资源之间的均衡,其最终目的是最大化所有计算资源的利用率。在实际的优化过程中,需要仔细地对程序进行Profiling,然后找出可能的性能瓶颈,针对性能瓶颈进行优化,解决瓶颈问题,但是这时候性能瓶颈可能会转移,就要继续迭代:Profiling→发现瓶颈→解决瓶颈。
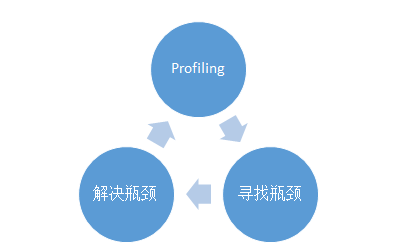
典型的计算性能优化循环
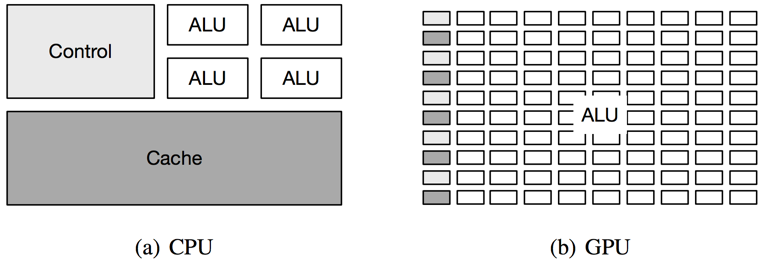
CPU和GPU的架构对比
分布式计算是有代价的,比如序列化代价、网络通讯代价等等,并不是所有的任务都需要分布式执行,有些情况下任务或者任务的某些部分可以很好地被单机执行,不要为了分布式而分布式。为了得到更好的计算性能,需要对单机和分布式进行分离优化。
CPU、GPU、FPGA等不同硬件有各自的优势,比如CPU适合复杂指令,有分支预测,大缓存,适合任务并行;GPU有大量的算术逻辑运算单元,但缓存较小,没有分支预测,适合粗粒度数据并行,但不适合复杂指令执行,可以用来加速比如矩阵运算等粗粒度并行的计算任务;FPGA对于特定的计算任务,比如深度学习预测,经过优化后有着介于CPU和GPU之间的峰值,同时功耗远低于GPU芯片。针对机器学习任务需要进行合理的任务调度,充分发挥不同计算硬件的优势,提升计算硬件的利用率。
近些年CPU、GPU等计算硬件的效率提升速度远高于主存性能的提升速度,所以计算和存储上的性能差距在不断扩大,形成了“存储墙”(Memory Wall),因此在很多问题上,存储优化更为重要。在存储方面,从CPU的寄存器到L1、L2等高速缓存,再到CPU本地内存,再到其他CPU内存,还有外存等有着复杂的存储结构和不同的存储硬件,访问效率也有着量级的差距。Jeff Dean建议编程人员牢记不同存储硬件的性能数据。

存储层级架构、性能数据和存储墙
针对存储的层次结构和各个层级存储硬件的性能特性,可以采取数据本地化及访存模式等存储优化的策略。因为机器学习是迭代的,可以将一些训练数据或者一些中间计算结果放在本地,再次训练时,无需请求远端的数据;另外在单机情况下,也可以尝试不同的内存分配策略,调整计算模式,增强数据本地化。
在访存模式优化方面,也可以进行很多优化:数据访问重新排序,比如GPU中纹理渲染和矩阵乘法运算中常见的Z秩序曲线优化;调整数据布局,比如可以采用更紧致的数据结构,提升顺序访存的缓存命中率,同时,在多线程场景下,尽量避免线程之间频繁竞争申请释放内存,会竞争同一把锁。除此之外还可以将冷热数据进行分离,提升缓存命中率;数据预取,比如可以用另外一根线程提前预取数据到更快的存储中,提升后续计算的访存效率。
通信是分布式机器学习计算系统中至关重要的部分。通讯包括点对点通讯和组通讯(如AllReduce、AllGather等)。可通过软件优化、硬件优化的形式提高执行效率。
在软件优化方面,可以通过比如序列化框架优化、通讯压缩、应用层优化的方式进行优化:
-
通讯依赖于序列化,通用序列化框架比如ProtoBuffer、Thrift等,为了通用性、一些前后兼容性和跨语言考虑等会牺牲一定的效率,针对特定的通讯场景可以设计更加简单的序列化框架,提升序列化效率。
-
在带宽成为瓶颈时,可以考虑使用CPU兑换带宽的方式,比如利用压缩技术来降低带宽压力。
-
更重要的优化来自于考虑应用层通讯模式,可以做更多的优化:比如参数服务器的客户端,可以将同一台机器中多个线程的请求进行请求合并,因为同一次机器学习训练过程中,不同线程之间大概率会有很多重复的模型参数请求;或者根据参数服务器不同的一致性模型,可以做请求缓存,提升查询效率,降低带宽;或者对于不同的网络拓扑,可以采取不同的组通讯实现方式。
除了软件优化之外,通讯架构需要充分利用硬件特性,利用硬件来提升网络吞吐、降低网络延迟,比如可以配置多网卡建立冗余链路提升网络吞吐,或者部署 Infiniband提升网络吞吐、降低网络延迟等。
在容错方面,对于不同的系统,容错策略之间核心的区别就在于选择最适合的Tradeoff。这里的Tradeoff是指每次失败后恢复任务所需要付出的代价和为了降低这个代价所付出的overhead之间的权衡。在选择机器学习模型训练系统的容错策略时,需要考虑机器学习模型训练任务的特点:首先机器学习模型训练是一个迭代式的计算任务,中间状态较多;其次机器学习模型训练系统中模型参数是最重要的状态;最后,机器学习模型训练不一定需要强一致性。
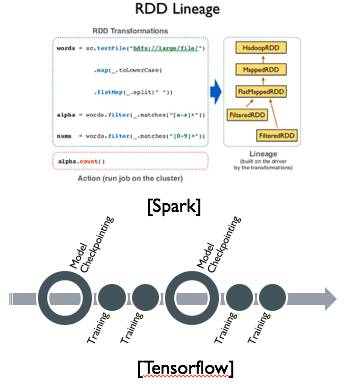
在业界常见的有Data Lineage和Checkpointing两种机器学习训练任务灾备方案。Data Lineage通过记录数据的来源,简化了对数据来源的追踪,一旦数据发生错误或者丢失,可以根据Data Lineage找到之前的数据利用重复计算进行数据恢复,常见的开源项目Spark就使用这种灾备方案。
Data Lineage的粒度可大可小,同时需要一个比较可靠的维护Data Lineage的服务,总体overhead较大,对于机器学习模型训练中的共享状态——模型参数不一定是很好的灾备方式,因为模型参数是共享的有着非常多的中间状态,每个中间状态都依赖于之前版本的模型参数和中间所有数据的计算;与Data Lineage不同,机器学习模型训练系统中的Checkpointing策略,一般会重点关注对机器学习模型参数的灾备,由于机器学习是迭代式的,可以利用这一点,在满足机器学习一致性模型的情况下,在单次或多次迭代之间或者迭代内对机器学习模型参数以及训练进度进行灾备.
这样在发生故障的情况下,可以从上一次迭代的模型checkpoint开始,进行下一轮迭代。相比于Data Lineage,机器学习模型训练系统对模型参数和模型训练进度进行Checkpointing灾备是更加自然和合适的,所以目前主流的专门针对机器学习设计的计算框架比如Tensorflow、Mxnet等都是采用Checkpointing灾备策略。
除了上述的容错方式之外,还可以使用传统灾备常用的部署冗余系统来进行灾备,根据灾备系统的在线情况,可以分为冷、温和热备份方式,实际应用中可以根据实际的资源和计算性能要求选择最合适实际问题的冗余容错方式。
机器学习实际应用的常见陷阱
在实际的机器学习应用中,经常会遇到一些容易被忽视的陷阱。这里举例分享一些常见的陷阱:一致性、开放世界、依赖管理、可理解性/可调试性。









