使用上一节的模型,在 MNIST 数据集上只有 92% 正确率,实在太糟糕。在这个小节里,我们用一个稍微复杂的模型:卷积神经网络来改善效果,这会达到大概99.2%的准确率。虽然不是最高,但是还是比较让人满意。
权重初始化
为了创建这个模型,我们需要创建大量的权重和偏置项。这个模型中的权重在初始化时应该加入少量的噪声来打破对称性以及避免 0 梯度。由于我们使用的是 ReLU 神经元,因此比较好的做法是用一个较小的正数来初始化偏置项,以避免神经元节点输出恒为 0 的问题(dead neurons)。为了不在建立模型的时候反复做初始化操作,我们定义两个函数用于初始化。
def weight_variable(shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)
这里定义了 weight_variable() 和 bias_variable() 方法,参数都是 shape,即张量的维度信息。weight_variable() 方法用于生成权重信息,中首先调用了 truncated_normal() 方法可以产生一个正态分布,第一个参数是 shape,它还支持 stddev 参数表示标准差、mean 表示均值,然后调用 Variable 将其赋值为可以变量。bias_variable() 方法用于生成偏置项,首先利用 constant() 方法定义了常量,然后调用 Variable 将其赋值为变量。
卷积和池化
TensorFlow 在卷积和池化上有很强的灵活性。我们怎么处理边界?步长应该设多大?在这个实例里,我们会一直使用 vanilla 版本。我们的卷积使用1步长(stride size),0边距(padding size)的模板,保证输出和输入是同一个大小。我们的池化用简单传统的2x2大小的模板做 max pooling。为了代码更简洁,我们把这部分抽象成一个函数。
def conv2d(x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
这里使用到了 conv2d() 和 max_pool() 方法分别做卷积和池化,下面详细介绍下这两个方法的用法。
tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, name=None)
tf.nn.conv2d 是 TensorFlow 里面实现卷积的函数,这是搭建卷积神经网络比较核心的一个方法,非常重要。
参数介绍如下:
input,指需要做卷积的输入图像,它要求是一个 Tensor,具有 [batch, in_height, in_width, in_channels] 这样的 shape,具体含义是 [训练时一个batch的图片数量, 图片高度, 图片宽度, 图像通道数],注意这是一个 4 维的 Tensor,要求类型为 float32 和 float64 其中之一。
filter,相当于 CNN 中的卷积核,它要求是一个 Tensor,具有 [filter_height, filter_width, in_channels, out_channels] 这样的shape,具体含义是 [卷积核的高度,卷积核的宽度,图像通道数,卷积核个数],要求类型与参数 input 相同,有一个地方需要注意,第三维 in_channels,就是参数 input 的第四维。
strides,卷积时在图像每一维的步长,这是一个一维的向量,长度 4。
padding,string 类型的量,只能是 SAME、VALID 其中之一,这个值决定了不同的卷积方式。
use_cudnn_on_gpu,布尔类型,是否使用 cudnn 加速,默认为true
实例如下:
import tensorflow as tf
input = tf.Variable(tf.random_normal([1, 3, 3, 5]))
filter = tf.Variable(tf.random_normal([1, 1, 5, 2]))
op = tf.nn.conv2d(input, filter, strides=[1, 1, 1, 1], padding='VALID')
sess = tf.InteractiveSession()
tf.global_variables_initializer().run()
print(sess.run(op))
结果如下:
[[[[-0.2160702 -0.95424265]
[ 0.40636641 0.35668218]
[ 0.9549607 1.72823894]]
[[ 1.94165611 3.4524672 ]
[ 0.69917625 -0.05939089]
[ 1.65653169 3.90102482]]
[[-1.41352415 -1.53854179]
[-0.83363831 -1.76933742]
[ 0.62390143 0.18021652]]]]
可以看到 input 为 [1, 3, 3, 5],filter 为 [1, 1, 5, 2] 时,生成的结果维度为 [1, 3, 3, 2]。
tf.nn.max_pool(value, ksize, strides, padding, name=None)
是CNN当中的最大值池化操作,其实用法和卷积很类似。
参数介绍如下:
value,需要池化的输入,一般池化层接在卷积层后面,所以输入通常是 feature map,依然是 [batch, height, width, channels] 这样的shape。
ksize,池化窗口的大小,取一个四维向量,一般是 [1, height, width, 1],因为我们不想在 batch 和 channels 上做池化,所以这两个维度设为了1。
strides,和卷积类似,窗口在每一个维度上滑动的步长,一般也是 [1, stride,stride, 1]。
padding,和卷积类似,可以取 VALID、SAME,返回一个 Tensor,类型不变,shape 仍然是 [batch, height, width, channels] 这种形式。
示例如下:
假设有这样一张图,双通道 第一个通道:
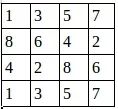
第二个通道:
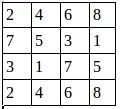
用程序去做最大值池化,代码如下:
import tensorflow as tf
a = tf.constant([
[[1.0, 2.0, 3.0, 4.0],
[5.0, 6.0, 7.0, 8.0],
[8.0, 7.0, 6.0, 5.0],
[4.0, 3.0, 2.0, 1.0]],
[[4.0, 3.0, 2.0, 1.0],
[8.0, 7.0, 6.0, 5.0],
[1.0, 2.0, 3.0, 4.0],
[5.0, 6.0, 7.0, 8.0]]
])
a = tf.reshape(a, [1, 4, 4, 2])
pooling = tf.nn.max_pool(a, ksize=[1, 2, 2, 1], strides=[1, 1, 1, 1], padding='VALID')
with tf.Session() as sess:
image = sess.run(a)
print(image)
result = sess.run(pooling)
print(result)
运行结果:
[[[[ 1. 2.]
[ 3. 4.]
[ 5. 6.]
[ 7. 8.]]
[[ 8. 7.]
[ 6. 5.]
[ 4. 3.]
[ 2. 1.]]
[[ 4. 3.]
[ 2. 1.]
[ 8. 7.]
[ 6. 5.]]
[[ 1. 2.]
[ 3. 4.]
[ 5. 6.]
[ 7. 8.]]]]
[[[[ 8. 7.]
[ 6. 6.]
[ 7. 8.]]
[[ 8. 7.]
[ 8. 7.]
[ 8. 7.]]
[[ 4. 4.]
[ 8. 7.]
[ 8. 8.]]]]
池化结果:
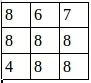
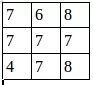
第一层卷积
现在我们可以开始实现第一层了。它由一个卷积接一个 max pooling 完成。卷积在每个 5x5 的 patch 中算出 32 个特征。卷积的权重张量形状是 [5, 5, 1, 32],前两个维度是 patch 的大小,接着是输入的通道数目,最后是输出的通道数目,而对于每一个输出通道都有一个对应的偏置量。
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
为了用这一层,我们把 x 变成一个 4d 向量,其第 2、3 维对应图片的宽、高,最后一维代表图片的颜色通道数,因为是灰度图所以这里的通道数为 1,如果是彩色图,则为 3。
x_image = tf.reshape(x, [-1,28,28,1])
我们把x_image和权值向量进行卷积,加上偏置项,然后应用ReLU激活函数,最后进行 max pooling。
h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
密集连接层
现在,图片尺寸减小到7x7,我们加入一个有1024个神经元的全连接层,用于处理整个图片。我们把池化层输出的张量reshape成一些向量,乘上权重矩阵,加上偏置,然后对其使用ReLU。
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
Dropout
为了减少过拟合,我们在输出层之前加入 dropout。我们用一个 placeholder 来代表一个神经元的输出在 dropout 中保持不变的概率。这样我们可以在训练过程中启用 dropout,在测试过程中关闭 dropout。 TensorFlow 的 tf.nn.dropout 操作除了可以屏蔽神经元的输出外,还会自动处理神经元输出值的 scale,所以用 dropout 的时候可以不用考虑 scale。
keep_prob = tf.placeholder("float")
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
输出层
最后,我们添加一个softmax层,就像前面的单层softmax regression一样。
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
训练和评估模型
这个模型的效果如何呢?
为了进行训练和评估,我们使用与之前简单的单层 SoftMax 神经网络模型几乎相同的一套代码,只是我们会用更加复杂的 ADAM 优化器来做梯度最速下降,在 feed_dict 中加入额外的参数 keep_prob 来控制 dropout 比例。然后每 100次 迭代输出一次日志。
cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
sess.run(tf.initialize_all_variables())
for i in range(20000):
batch = mnist.train.next_batch(50)
if i%100 == 0:
train_accuracy = accuracy.eval(feed_dict={
x:batch[0], y_: batch[1], keep_prob: 1.0})
print "step %d, training accuracy %g"%(i, train_accuracy)
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
print "test accuracy %g"%accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0})
以上代码,在最终测试集上的准确率大概是99.2%。
运行结果:
step 0, training accuracy 0.08
step 100, training accuracy 0.86
step 200, training accuracy 0.94
step 300, training accuracy 0.94
step 400, training accuracy 0.94
step 500, training accuracy 0.96
step 600, training accuracy 0.92
step 700, training accuracy 0.9
step 800, training accuracy 0.96
step 900, training accuracy 0.96
step 1000, training accuracy 0.94
step 1100, training accuracy 0.94
step 1200, training accuracy 0.92
step 1300, training accuracy 0.98
step 1400, training accuracy 0.98
step 1500, training accuracy 0.98
step 1600, training accuracy 0.98
step 1700, training accuracy 0.94
step 1800, training accuracy 0.98
step 1900, training accuracy 0.94
step 2000, training accuracy 0.98
step 2100, training accuracy 1
...
参考来源:
http://www.tensorfly.cn/tfdoc/tutorials/mnist_pros.html
http://blog.csdn.net/mao_xiao_feng/article/details/53444333
http://blog.csdn.net/mao_xiao_feng/article/details/53453926

Python3网络爬虫精华实战视频教程,大数据时代必备技能,重磅推荐!
现在购买学习,5折优惠!


Python爱好者社区历史文章大合集:
Python爱好者社区历史文章列表(每周append更新一次)
 福利:文末扫码立刻关注公众号,“Python爱好者社区”,开始学习Python课程:
福利:文末扫码立刻关注公众号,“Python爱好者社区”,开始学习Python课程:
关注后在公众号内回复“课程”即可获取:
1.崔老师爬虫实战案例免费学习视频。
2.丘老师数据科学入门指导免费学习视频。
3.陈老师数据分析报告制作免费学习视频。
4.玩转大数据分析!Spark2.X+Python 精华实战课程免费学习视频。
5.丘老师Python网络爬虫实战免费学习视频。












