量化投资和数据挖掘
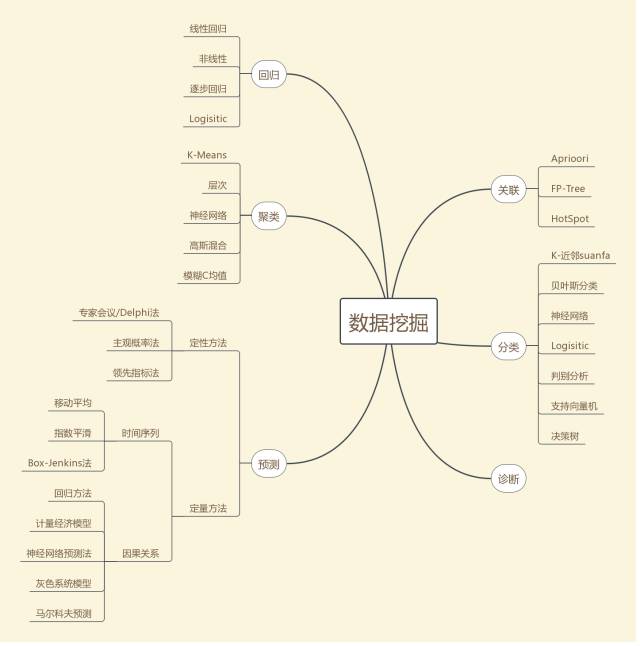
数据挖掘和传统数据分析(查询,报表,OLAP)的本质区别在于其在没有明确假设的前提下去挖掘信息,发现知识。在发现知识的过程中需要用到数据库、统计学、应用数学、机器学习、可视化、信息科学、程序开发及其他学科的内容。数据挖掘的核心在于对输入和输出数据进行训练,得到模型,使模型能够最大程度上刻画数据从输入到输出之间的关系。然后利用该模型,对于新的输入预测其输出。目前数据挖掘技术主要应用在宏观经济分析,股票估值,量化选股,量化择时,算法交易等方面。数据挖掘的内容主要集中在六个方面, 关联、回归、分类、聚类、预测和诊断。
啤酒和尿布是典型的关联关系。若两个或多个变量的取值之间存在规律性,就称为关联。关联可以分为简单关联,时序关联和因果关联。
回归是确定两种或两种变量之间相互定量关系的一种统计方法,是数据挖掘中最为基础的方法,也是应用领域和场景最多的方法。
分类问题,在人们的日常生活中也经常会遇到,如垃圾分类投放,分类收纳衣物等等。数据挖掘中的分类问题也是类似,根据事物的数据层面特征将其归于不同的类别。
聚类分析,是根据“物以类聚”的原理,将事物归于不同的类或者簇中的一个过程,使得同一簇中的对象具有尽可能大的相似性,而不同簇中的对象具有尽可能大的相异性。和分类问题的不同在于聚类问题事先不知道类别,而分类问题事先已经定义好了类别。
预测基于历史数据建立模型,用来推算将来。
诊断的对象是离散点或称为孤立点。离散点代表了异常状态,包含了非常重要的信息,可以被用来发现欺诈行为,定位病灶等。
对于这六个方面内容的典型算法归纳如下,由于诊断主要基于其他5个方面的问题,在此并未列出其涉及的具体算法。
数据挖掘的过程主要包含六个阶段,如下图所示。实施数据挖掘的第一步是确定目标,要确定数据挖掘的目标,就必须了解数据和相关业务。数据挖掘的基础是数据,因此数据准备是数据挖掘中耗时最多的环节,包含数据选择,质量分析,预处理三个子环节。数据探索是对数据的初步研究,可以从描述统计,可视化等方面展开。模型建立是数据挖掘的核心,在这一步要确定具体的数据挖掘算法,训练出模型参数。模型评估阶段需要对数据挖掘过程进行一次全面的回顾,目的在于判断是否还存在一些重要的商业问题仍未得到充分的考虑。模型部署用于体现数据挖掘的成果,将其部署到实际业务系统中,进行知识消化。
梦想引领人生——第二届中国职业交易员大会重磅来袭!
2017年12月8日-10日 上海
咨询电话/微信18516600808

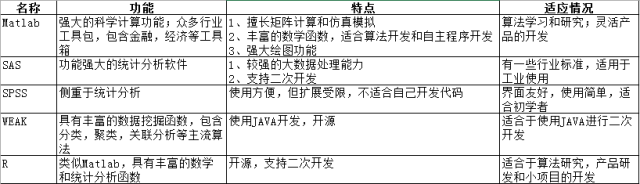
工欲善其事,必先利其器。下面对数据挖掘常用的工具进行一下总结。工具眼花缭乱,各有长短,适合自己的便是最好,在后面的学习研究中,matlab就是我们的绝世好剑。
梦想引领人生——第二届中国职业交易员大会重磅来袭!
2017年12月8日-10日 上海
咨询电话/微信18516600808
初识Matlab
Matlab软件是一种用于数值计算、可视化及编程的高级语言和交互式环境,支持命令行模式,脚本模式和面向对象模型。本例中,我们使用命令行模式来评估单只股票的风险。股票风险度量有各种各样的方法,为简便起见,本例使用最大回撤来定量度量单只股票的风险。
OS: win7 64bits
Matlab: R2012b 64bits
(1). 打开matlab,导入股票数据文件。

(2). 成功导入后,弹出如下窗口,点击“Import Selection", 将数据导入工作区(matlab运行内存)

(3). 回到软件主界面,可以看到工作区(workspace)已经显示了导入表格的字段内容,选中“DateNum”和“Pclose”两个字段,点击“plot”图标,会绘制出股价随时间序列变化的曲线,这个点击动作实际上是在命令行中执行了 plot(DateNum,Pclose);figure(gcf)命令。

(4). 在命令行中执行risk = maxdrawdown(Pclose)得到该只股票收盘价的最大回撤,并赋值给risk,值为0.1155,也就是该只股票从前一高点到最低点的最大跌幅为11.55%。

来源: 金融与计算机
作者:李三木










