
数据挖掘入门与实战 公众号: datadw
RNN
模型作为一个可以学习时间序列的模型被认为是深度学习中比较重要的一类模型。在Tensorflow的官方教程中,有两个与之相关的模型被实现出来。第一个模型是围绕着Zaremba的论文Recurrent
Neural Network
Regularization,以Tensorflow框架为载体进行的实验再现工作。第二个模型则是较为实用的英语法语翻译器。在这篇博客里,我会主要针对第一个模型的代码进行解析。在之后的随笔里我会进而解析英语法语翻译器的机能。
论文以及Tensorflow官方教程介绍:
Zaremba设计了一款带有regularization机制的RNN模型。该模型是基于RNN模型的一个变种,叫做LSTM。论文中,框架被运用在语言模型,语音识别,机器翻译以及图片概括等应用的建设上来验证架构的优越性。作为Tensorflow的官方demo,该模型仅仅被运用在了语言模型的建设上来试图重现论文中的数据。官方已经对他们的模型制作了一部教程,点击这里https://github.com/tensorflow/tensorflow/blob/master/tensorflow/g3doc/tutorials/recurrent/index.md
查看官方教程(英语版)。
代码解析:
代码可以在github找到,这里先放上代码地址。点击这里https://github.com/tensorflow/tensorflow/blob/master/tensorflow/models/rnn/ptb/ptb_word_lm.py查看代码。
代码框架很容易理解,一开始,PTB模型被设计入了一个类。该类的init函数为多层LSTM语言模型的架构,代码如下:

上面的代码注释已就框架进行了解释。但我有意的留下了一个最为关键的部分没有解释,即variable_scope以及reuse_variable函数。该类函数有什么特殊意义呢?我们这里先卖个关子,下面的内容会就这个问题深入探究。
模型建立好后该类还有其他如assign_lr(self,session,lr_value)以及property函数如input_data(self). 这些函数浅显易懂,就不在这里解释了。
之后,官方代码设计了小模型(原论文中没有regularized的模型)外,还原了论文里的中等模型以及大模型。这些模型是基于同样的框架,不过不同在迭代数,神经元数以及dropout概率等地方。另有由于小模型的keep_prob概率被设计为1,将不会运用dropout。
另外,由于系统的运行是在terminal里输入”python 文件名 --参数 参数值“格式,名为get_config()的函数的意义在于把用户输入,如small,换算成运用SmallConfig()类。
最后,我们来看一看main函数以及run_epoch函数。首先来看下run_epoch:

还记得之前卖的关子么?这个重要的variable_scope函数的目的其实是允许我们在保留模型权重的情况下运行多个模型。首先,从RNN的根源上说,因为输入输出有着时间关系,我们的模型在训练时每此迭代都要运用到之前迭代的结果,所以如果我们直接使用(cell_output,
state) = cell(inputs[:, time_step, :], state)我们可能会得到一堆新的RNN模型,而不是我们所期待的前一时刻的RNN模型。再看main函数,当我们训练时,我们需要的是新的模型,所以我们在定义了一个scope名为model的模型时说明了我们不需要使用以存在的参数,因为我们本来的目的就是去训练的。而在我们做validation和test的时候呢?训练新的模型将会非常不妥,所以我们需要运用之前训练好的模型的参数来测试他们的效果,故定义reuse=True。这个概念有需要的朋友可以参考Tensorflow的官方文件对共享变量的描述。
好了,我们了解了这个模型代码的架构以及运行的机制,那么他在实际运行中效果如何呢?让我们来实际测试一番。由于时间问题,我只运行了小模型,也就是不用dropout的模型。运行方式为在ptb_word_lm.py的文件夹下输入python
ptb_word_lm.py --data_path=/tmp/simple-examples/data/ --model
small。这里需要注意的是你需要下载simple-examples.tar.gz包,下载地址点击这里http://www.fit.vutbr.cz/~imikolov/rnnlm/simple-examples.tgz 运行结果如下:
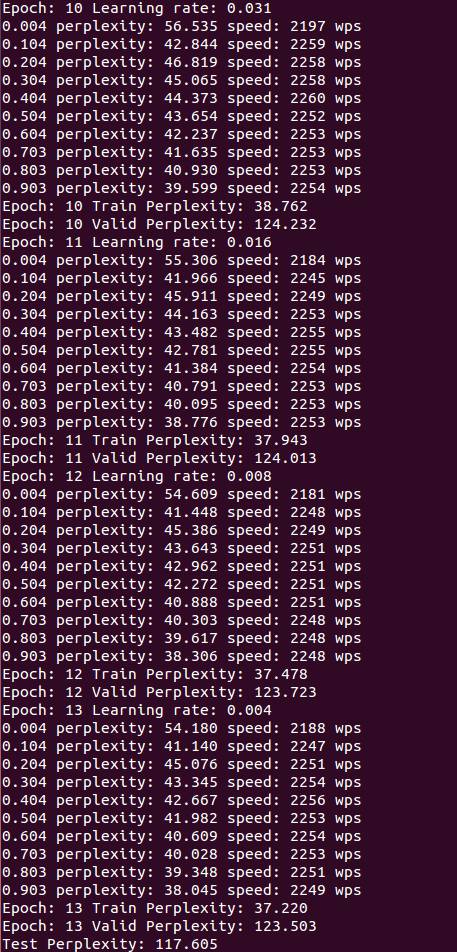
这里简便的放入了最后结果,我们可见,在13个epoch时,我们的测试perplexity为117.605, 对应了论文里non-regularized LSTM的114.5,运行时间约5到6小时。
数据挖掘入门与实战
搜索添加微信公众号:datadw
教你机器学习,教你数据挖掘

长按图片,识别二维码,点关注
公众号: weic2c
据分析入门与实战

长按图片,识别二维码,点关注










