
作者:刘顺祥
个人微信公众号:每天进步一点点2015
前文传送门:
从零开始学Python数据分析【1】--数据类型及结构
从零开始学Python数据分析【2】-- 数值计算及正则表达式
从零开始学Python数据分析【3】-- 控制流与自定义函数
从零开始学Python数据分析【4】-- numpy
上一期我们介绍了数据分析中常用的numpy模块,从数组的创建、元素的获取、数学+统计函数、随机数的生成、到外部文件的读取。这期我们再来介绍另一个重磅的数据分析常用模块--
pandas
。该模块更像是R语言中的向量、数据框的处理,接下来我们就一一介绍里面的小知识点。
序列
序列(Series)可以理解成是R语言中的向量,Python中的列表、元组的高级版本。为什么说是高级版本呢?因为序列与上期介绍的一维数组类似,具有
更好的广播效应
,既可以与一个标量进行运算,又可以进行元素级函数的计算。如下例子所示:
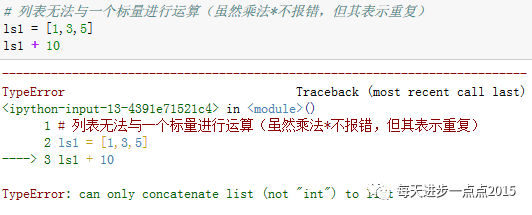
列表与常数10相加,报错,显示无法将列表与整形值
连接,“+”
运算在列表中是连接操作。
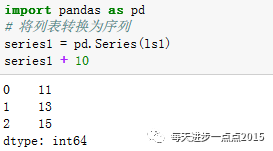
将上面的列表转换成一个序列后,就可以正常的完成运算,这就是序列的广播能力。同样,列表也不能用于元素级的数学函数,对比如下:
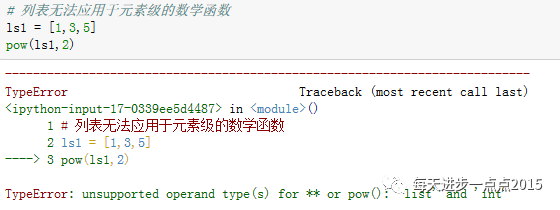
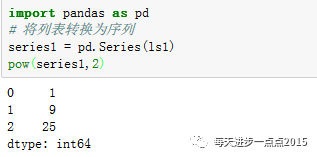
除了上面介绍序列功能,再来说说其他序列常用的场景,如序列的索引、成员关系、排重、排序、计数、抽样、统计运算等。
序列的索引:
由于序列是列表的扩张版,故序列也有一套类似于列表的索引方法,具体如下:
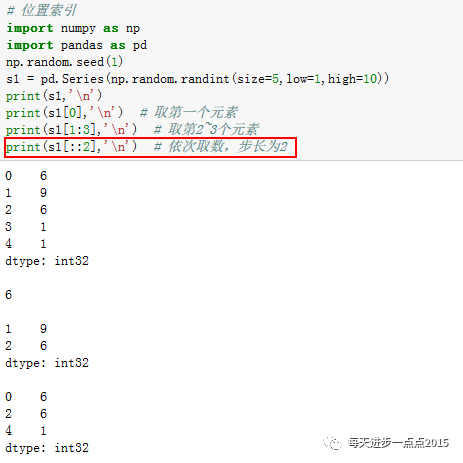
用
倒数的方式取元素,序列就显得不是很方便
了,我们推荐使用非常棒的
iat方法
,该方法不管应用于序列还是数据框都非常优秀,主要体现在简介而高速。

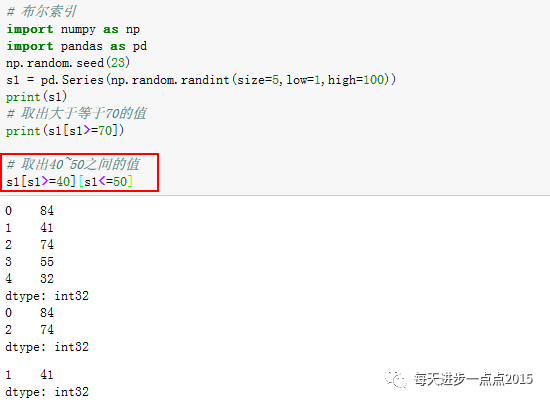
然而,实际工作中很少通过位置索引(下标)的方法获取到序列中的某些元素,例如1000个元素构造的序列,查出属于某个范围值总不能一个个去数吧?序列提供了另一种索引的方法--
布尔索引
。具体用法如下:
我们知道,在R语言中一个向量的
元素是否包含于另一个向量
,可以使用%in%函数进行判断,同理,Python中也有类似的方法。对于一个一维数组,
in1d函数
实现该功能;对于一个序列,
isin方法
可实现该功能。
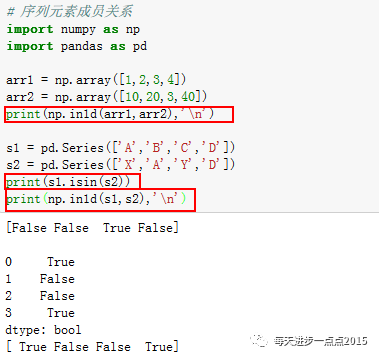
numpy模块中的in1d函数也可以用于序列的成员关系的比较。
如果手中有一离散变量的序列,想查看该序列都有
哪些水平
,以及各个
水平的频次
,该如何操作?
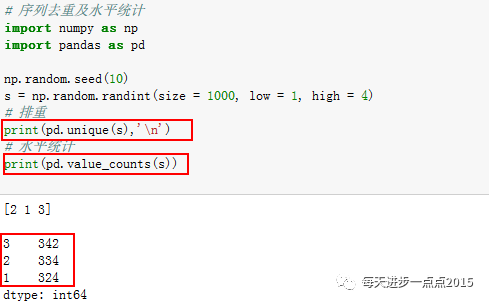
没错,只要借助于
unique函数
(与R语言一样的函数)实现序列的排重,获得不同的水平值;通过使用
value_counts函数
(对应于R语言的table函数)对各个水平进行计数,并按频次降序呈现。
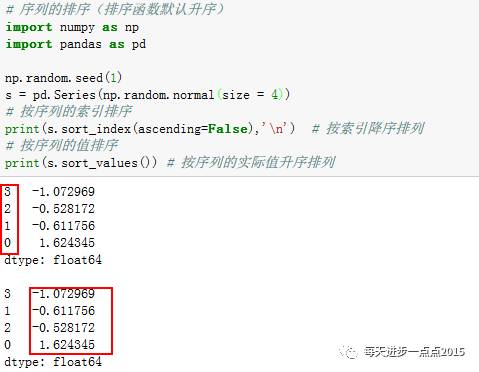
有的时候需要对某个序列进行升序或降序
排序
,虽然这样的场景并不多,但排序在数据框中的应用还是非常常用的,先来看看如何对序列进行排序:
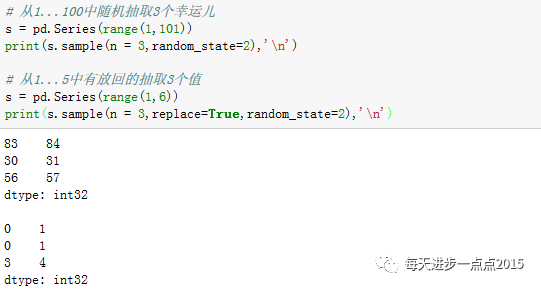
抽样也是数据分析中常用的方法,通过从总体中抽取出一定量的样本来推断总体水平;或者通过抽样将数据拆分成两部分,一部分建模,一部分测试。pandas模块提供了
sample函数
(与R语言的sample函数一致)帮我们完成抽样的任务。
s.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)
n:
指定抽取的样本量;
frac:
指定抽取的样本比例;
replace:
是否有放回抽样,默认无放回;
weights:
指定样本抽中的概率,默认等概论抽样;
random_state:
指定抽样的随机种子;
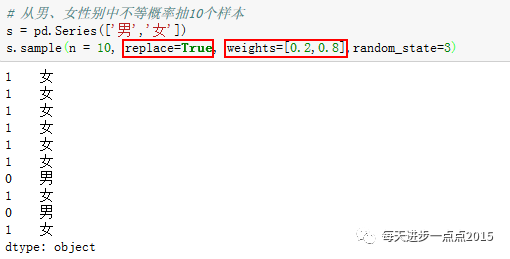
由于总体就是男、女性别两个值,故需要抽出10个样本,必须有放回的抽,而且男女被抽中的概率还不一致,女被抽中的概率是0.8。
统计运算
pandas模块提供了比numpy模块更丰富的统计运算函数,而且还提供了类似于R语言中的summary汇总函数,即
describe函数
。
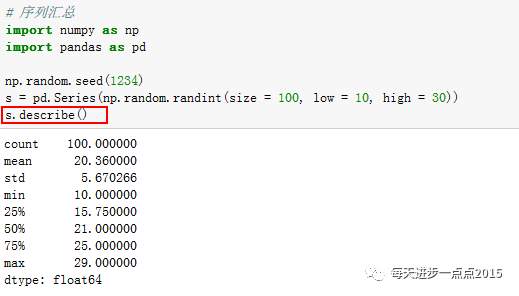
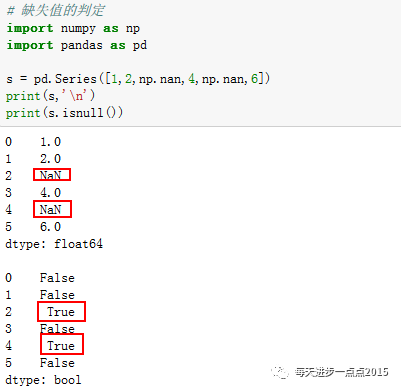
其中count是序列中非缺失元素的个数。哦,对了,如何判断一个序列
元素是否为缺失呢
?可以使用
isnull函数
,等同于R语言中的is.na函数。
除此,我们再来罗列一些常用的统计函数:
s.min()
# 最小值
s.
quantile(q=[0,0.25,0.5,0.75,1])
# 分位数函数
s.median()
# 中位数
s.mode()
# 众数
s.mean()
# 平均值
s.mad()
# 平均绝对误差
s.max # 最大值
s.sum() # 和
s.std() # 标准差
s.var() # 方差
s.skew() # 偏度
s.kurtosis() # 峰度
s.cumsum() # 和的累计,返回序列
s.cumprod() # 乘积的累积,返回序列
s.product() # 序列元素乘积
s.diff() # 序列差异(微分),返回序列
s.abs() # 绝对值,返回序列
s.pct_change() # 百分比变化 ,返回序列
s.corr(s2) # 相关系数
s.ptp() # 极差 R中的range函数
今天我们的内容就介绍到这边,欢迎大家拍砖。下期我们来聊聊pandas模块的数据框DataFrame部分。

Python爱好者社区历史文章大合集
:
Python爱好者社区历史文章列表(每周append更新一次)
 福利:文末扫码立刻关注公众号,
“Python爱好者社区”
,开始学习Python课程:
福利:文末扫码立刻关注公众号,
“Python爱好者社区”
,开始学习Python课程:
关注后在公众号内回复
“
课程
”
即可获取:
1.崔老师
爬虫实战案例
免费学习视频。
2.丘老师
数据科学入门指导
免费学习视频。
3.
陈老师
数据分析报告制作
免费学习视频。
4.
玩转大数据分析!Spark2.X+Python 精华实战课程
免费学习视频。
5.
丘老师
Python网络爬虫实战
免费学习视频。





