来源: mila.umontreal.ca
报道:弗格森、刘小芹、文强
【新智元导读】
深度学习领军人物 Yoshua Bengio 主导的蒙特利尔大学深度学习暑期学校目前“深度学习”部分的报告已经全部结束。 本年度作报告的学术和行业领袖包括有来自DeepMind、谷歌大脑、蒙特利尔大学、牛津大学、麦吉尔大学、多伦多大学等等。覆盖的主题包括:时间递归神经网络、自然语言处理、生成模型、大脑中的深度学习等等。现在全部PPT已经公开,是了解深度学习发展和趋势不可多得的新鲜材料。

蒙特利尔大学的深度学习暑期学校久负盛名,在深度学习领军人物Yoshua Bengio 号召下,每年都聚集了顶尖的深度学习和人工智能方面的学者进行授课。今年的暑期学校更是首次增加了强化学习课程。
深度学习暑期学校
深度神经网络,即学习在多层抽象中表示数据的神经网络,已经极大地提升了语音识别、对象识别、对象检测、预测药物分子活性以及其他许多技术。深度学习通过构建分布式表示(监督学习、无监督学习、强化学习)在大型数据集中发现复杂结构。
深度学习暑期学校(DLSS)面向研究生、工程师和研究人员,要求已经掌握机器学习的一些基本知识(包括深度学习,但不是必须),并希望对这个快速发展的研究领域有更多了解。
今年的 DLSS 由 Graham Taylor,Aaron Courville 和 Yoshua Bengio 组织。
强化学习暑期学校
这是第一届的蒙特利尔大学强化学习暑期学校(RLSS),与 DLSS 是相辅相成的。RLSS 将涵盖强化学习的基础知识,并展示最新的研究趋势和成果,为研究生和该领域的高级研究人员提供互动的机会。
本期强化学习暑期学校面向机器学习及相关领域的研究生。参加者需具有高级计算机科学和数学的先期培训,优先考虑 CIFAR 机器和大脑学习项目研究实验室的学生。
今年的 RLSS 由 Joelle Pineau 和 Doina Precup 组织。
目前,深度学习部分的课程已经结束,官方公开了全部的讲义PPT,今年的深度学习部分的课程内容包括:
-
蒙特利尔大学 Yoshua Bengio 主讲《循环神经网络》 。
-
谷歌的Phil Blunsom 主讲自然语言处理相关内容,分为两部分《自然语言处理、语言建模和机器翻译》和《自然语言的结构和基础》。
-
蒙特利尔大学的Aaron Courville 主讲《生成模型》。
-
谷歌大脑的Hugo Larocelle 主讲《 神经网络》。
-
麦吉尔大学的Doina Precup 主讲 《机器学习导论》。
-
牛津大学的 Mike Osborne主讲《深度学习中的概率数字》。
-
多伦多大学的 Blake Aaron Richards 主讲《大脑中的深度学习》。
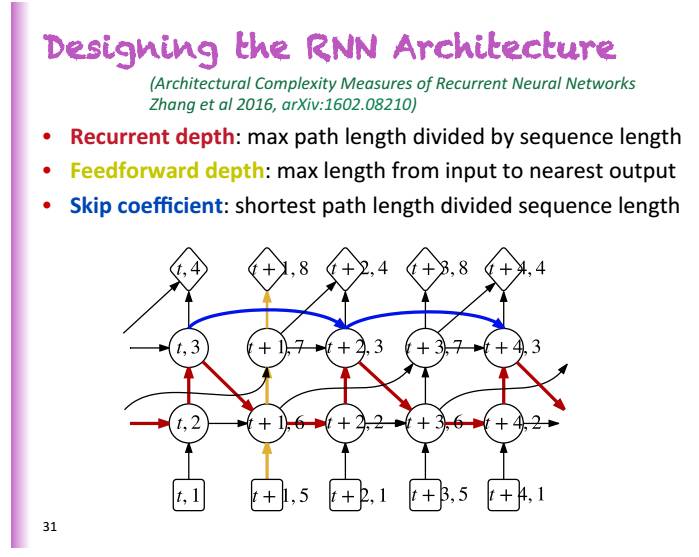
Yoshua Bengio 主讲《时间递归神经网络》 :RNN 的 7个小贴士


Bengio 今年主讲的主题是《时间递归神经网络》。在神经网络中,时间递归神经网络模型通过一个递归的更新,从一个固定大小状态的向量中有选择性地对一个输入序列进行提炼。时间递归神经网络能在每一个时间点上产生一个输出。
一个RNN能表征一个全连接的定向生成模型,即,每一个变量都能从根据前序变量进行预测。
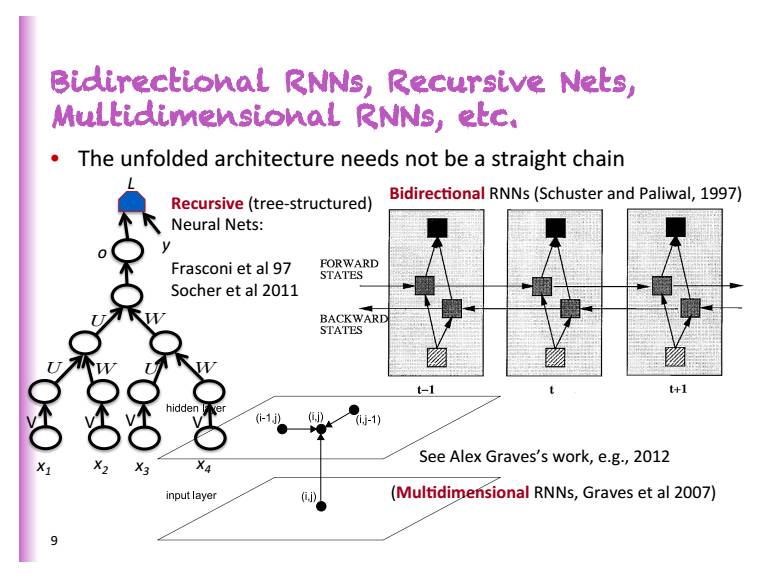
他在演讲中介绍了多种类型的RNN:双向RNN、递归网络,多维RNN 等等,根据演讲PPT,用梯度下降学习长依存性是非常困难的。1991年,Bengio在MIT时,所做的研究中的样本实验,只能做到2个类型的序列。
基于梯度的学习为什么很困难?Bengio认为,与短依存相比,长依存所获得的权重过小,指数级的小。由此,从RNN的例子可以看到,梯度消失在深度网络是非常困难的。所以,为了稳定的存储信息,动态性必须进行收缩。

关于 RNN的 7个小贴士:
-
剪裁梯度(避免梯度的过载)
-
漏洞融合(推动长期的依存性)
-
动能(便宜的第二等级)
-
初始化(在正确的范围开始,以避免过载/消失)
-
稀疏梯度(对称性破坏)
-
梯度传播的正则化(避免梯度消失)
-
门自循环(LSTM&GRU,减少梯度消失)

他在演讲中着重介绍了注意力机制:快速进步的20年:用于记忆权限的注意力机制
神经网络图灵机
记忆网络
使用基于内容的注意力机制来控制记忆的读写权限
注意力机制会输出一个超越记忆位置的Softmax
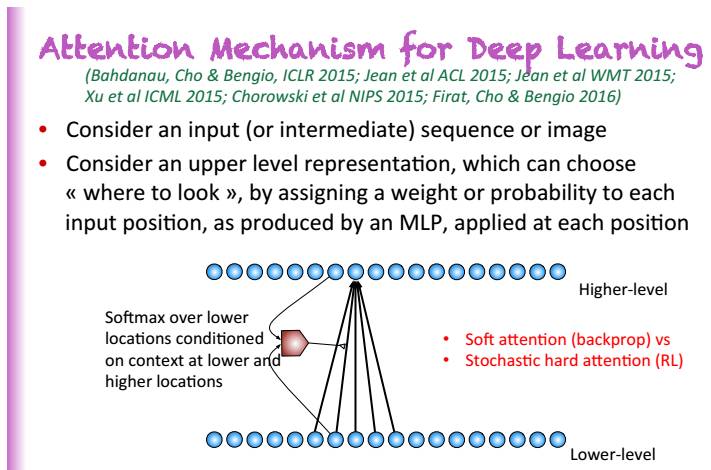
深度学习中的注意力机制示意图
注意力机制现在在端到端的机器翻译中得到应用,并且获得巨大成功。