自 T
ensorFlow 1.0
发布以来,越来越多的机器学习研究者和爱好者加入到这一阵营中,而 TensorFlow 近日官方又发表了该基准。因此本文通过将一系列的图像分类模型放在多个平台上测试,希望得出一些重要结果并为 TensorFlow 社区提供可信的参考。不仅如此,同时在本文最后一节中还将给出测试进行的细节和所使用脚本的链接。
图像分类模型的测试结果
InceptionV3、ResNet-50、ResNet-152、VGG16 和 AlexNet 模型都在 ImageNet 数据集中进行测试。而上述测试则在谷歌计算引擎(Google Compute Engine)、亚马逊弹性计算云(Amazon Elastic Compute Cloud /Amazon EC2)以及 NVIDIA DGX-1 这些平台上一一试验,最后大多数测试分别使用合成数据和真实数据进行训练。使用合成数据进行的测试是通过将 tf.Variable 设置为与 ImageNet 上每个模型的预期数据相同的形(shape)而完成。我们认为,在对平台做基准测试时,包含真实数据测量很重要。在为真实训练准备数据时,这一负载同时测试了底层硬件和框架。我们从合成数据开始,删除作为变量的磁盘输入/输出并设置基线。接着,真实数据用于核实 TensorFlow 输入通道和底层磁盘输入/输出是否使计算单元饱和。
使用 NVIDIA DGX-1 (NVIDIA Tesla P100) 进行训练
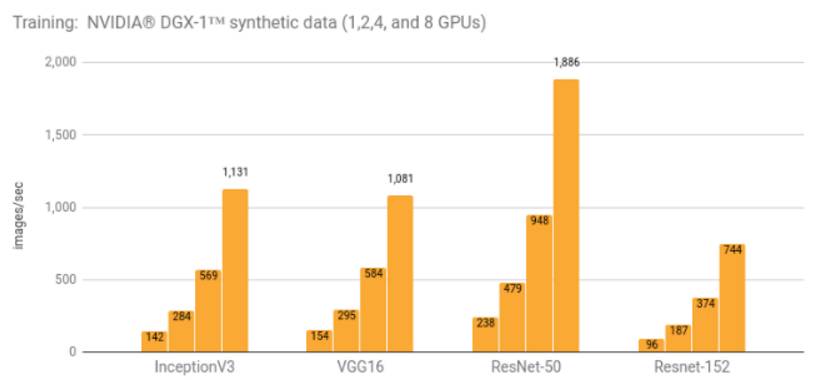
训练细节及额外结果可参阅 NVIDIA DGX-1(NVIDIA Tesla P100)明细(链接:http://suo.im/3JkWvy)
使用 NVIDIA Tesla K80 进行训练
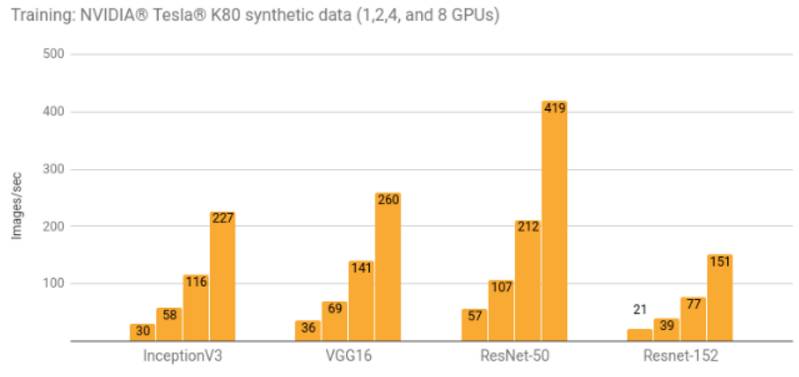
训练细节及额外结果可参阅谷歌计算引擎(NVIDIA Tesla K80)明细(链接:http://suo.im/1utQoq)和 亚马逊弹性计算云训练细节(NVIDIA Tesla K80)(链接:http://suo.im/Y4AWe)。
使用 NVIDIA Tesla K80 进行分布式训练
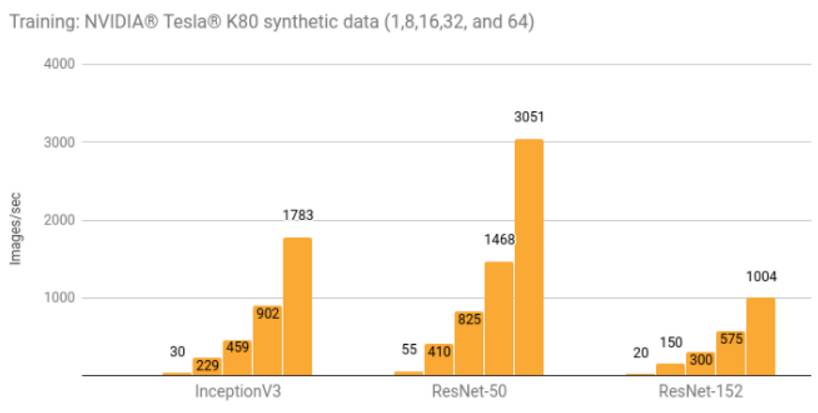
训练细节及额外结果可参阅亚马逊弹性计算云分布式训练明细(链接:http://suo.im/tgzU9)
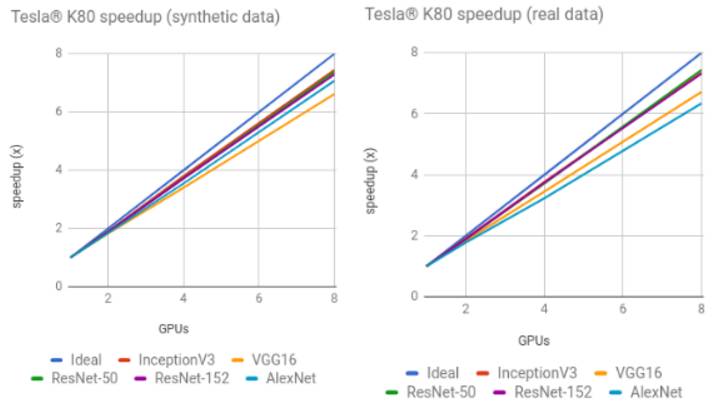
合成数据与真实数据训练的对比
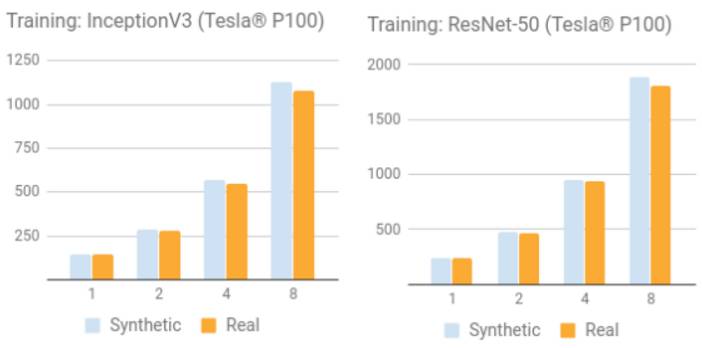
NVIDIA Tesla P100
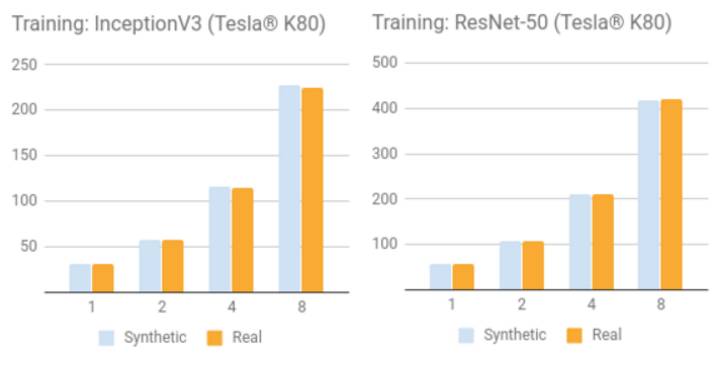
NVIDIA Tesla K80
英伟达 DGX-1 训练的细节 (NVIDIA Tesla P100)
环境
-
实例类型:NVIDIA DGX-1
-
GPU:8x NVIDIA Tesla P100
-
操作系统:Ubuntu 16.04 LTS with tests run via Docker
-
CUDA / cuDNN:8.0 / 5.1
-
TensorFlow GitHub hash:b1e174e
-
构建命令:
bazel build -c opt --copt=-march="haswell" --config=cuda //tensorflow/tools/pip_package:build_pip_package
-
硬盘:本地固态硬盘
-
数据集:ImageNet
每一个模型使用的批量大小和优化器都展示在下表中。除了表格中所列举的批量大小,InceptionV3、ResNet-50、ResNet-152 和 VGG16 还使用批量大小为 32 进行过测试。这些结论显示在「其他结果」部分。

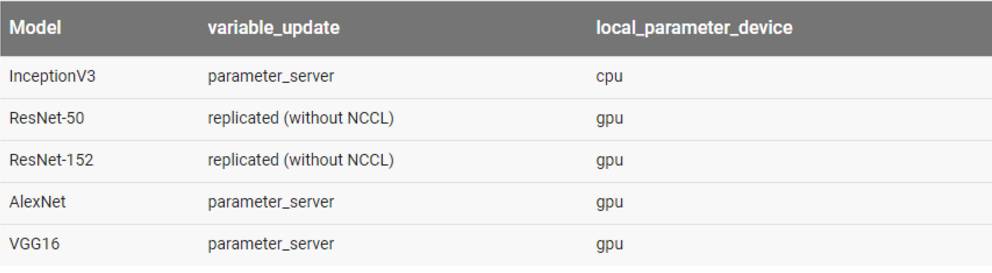
每一个模型所使用的配置为:
结果

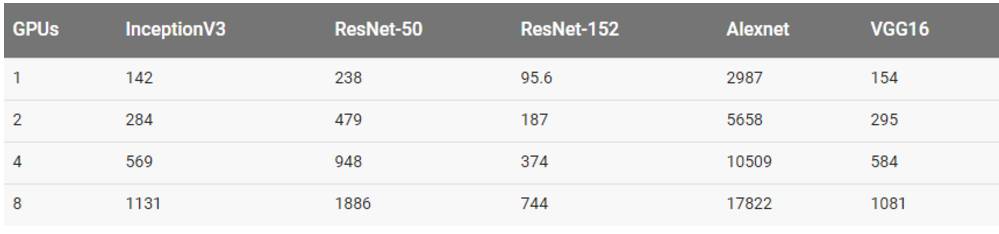
用合成数据集训练
用真实数据集训练
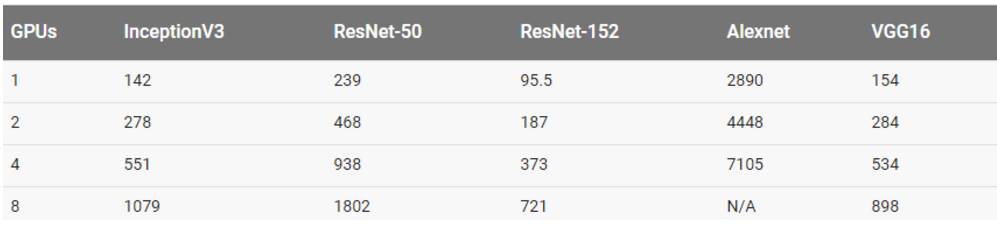
在真实数据和 8 块 GPU 上训练 AlexNet 在上表中是没有数据的,因为其最大溢出了输入管线(input pipeline)。
其他结果
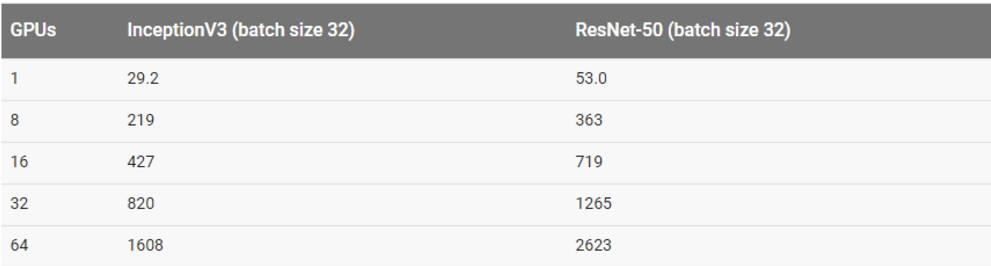
这一部分结果都是在批量大小为 32 的情况下得到的。
用合成数据集训练
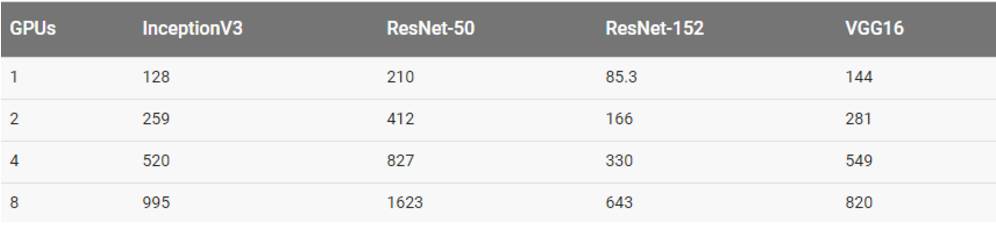
用真实数据集训练
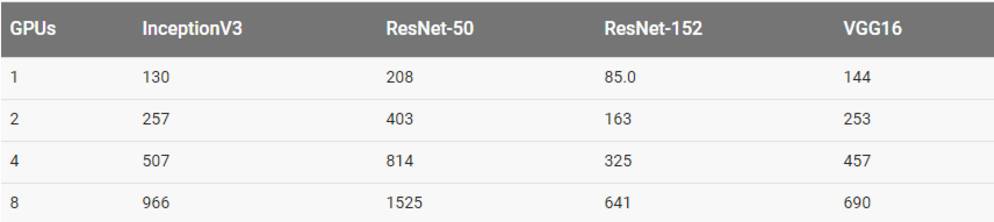
谷歌计算引擎训练的细节(NVIDIA Tesla K80)
环境
-
实例类型:n1-standard-32-k80x8
-
GPU:8x NVIDIA® Tesla® K80
-
操作系统:Ubuntu 16.04 LTS
-
CUDA / cuDNN:8.0 / 5.1
-
TensorFlow GitHub hash:b1e174e
-
构建命令:
bazel build -c opt --copt=-march="haswell" --config=cuda //tensorflow/tools/pip_package:build_pip_package
-
硬盘:1.7 TB Shared SSD persistent disk (800 MB/s)
-
数据集:ImageNet
-
测试日期:2017 年 4 月
每一个模型使用的批量大小和优化器都展示在下表中。除了表格中所列举的批量大小,InceptionV3 和 ResNet-50 还使用批量大小为 32 进行过测试。这些结论显示在「其他结果」部分。

每一个模型所使用的的配置为:
variable_update
等于
parameter_server
、
local_parameter_device
等于
cpu
结果
用合成数据集训练
用真实数据集训练
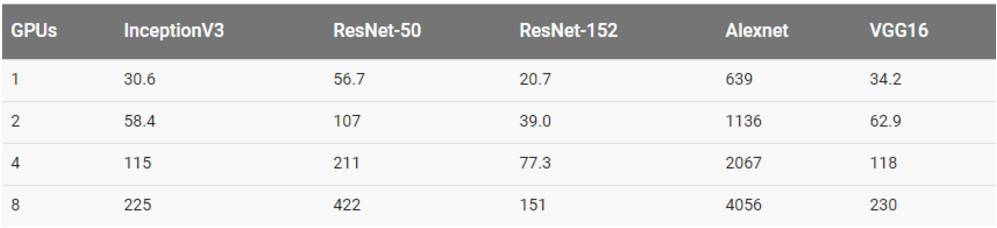
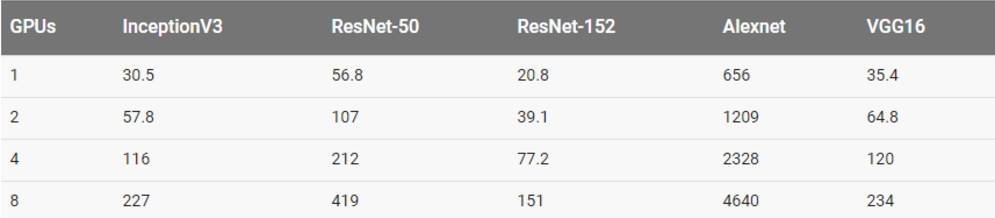
其他结果
用合成数据集训练
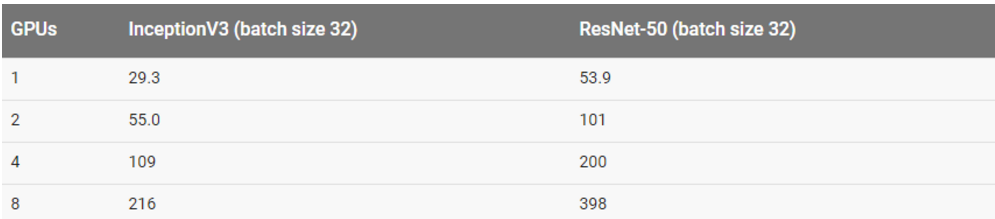
用真实数据集训练
亚马逊 EC2 训练的细节(NVIDIA Tesla K80)
环境
-
实例类型:p2.8xlarge
-
GPU:8x NVIDIA Tesla K80
-
操作系统:Ubuntu 16.04 LTS
-
CUDA / cuDNN:8.0 / 5.1
-
TensorFlow GitHub hash:b1e174e
-
构建命令:
bazel build -c opt --copt=-march="haswell" --config=cuda //tensorflow/tools/pip_package:build_pip_package
-
硬盘:1TB Amazon EFS (burst 100 MiB/sec for 12 hours, continuous 50 MiB/sec)
-
数据集:ImageNet
-
测试日期:2017 年 4 月
每一个模型使用的批量大小和优化器都展示在下表中。除了表格中所列举的批量大小,InceptionV3 和 ResNet-50 还使用批量大小为 32 进行过测试。这些结论显示在「其他结果」部分。

每一个模型所使用的配置:
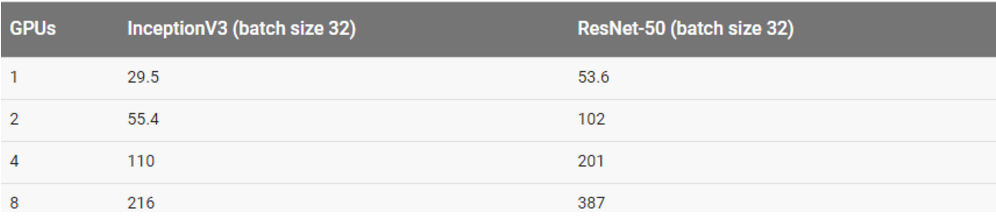
结果
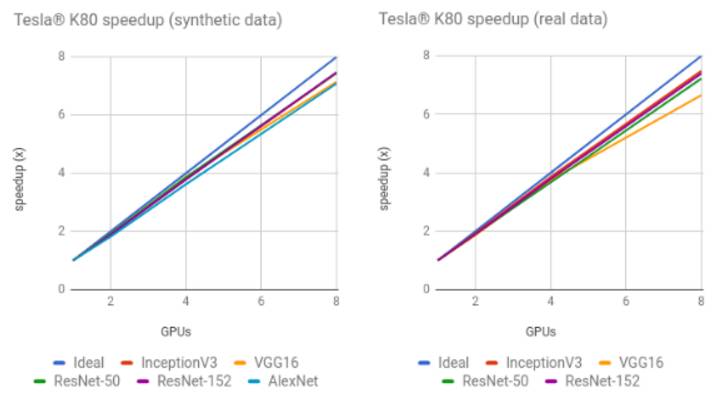
用合成数据集训练
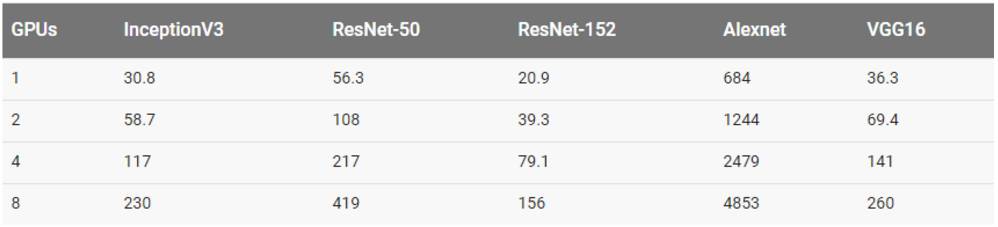
用真实数据集训练
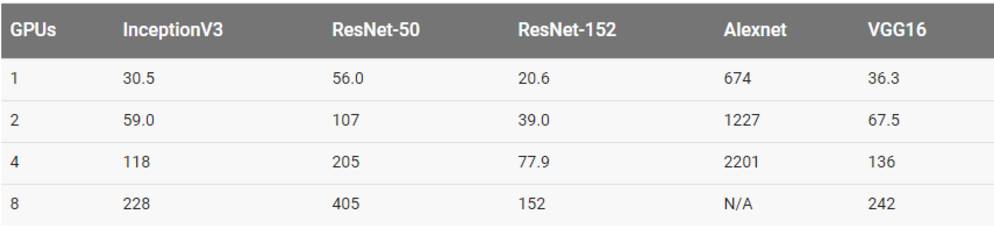
在真实数据和 8 块 GPU 上训练 AlexNet 在上表中是没有数据的,因为我们的 EFS 设置不能提供足够的吞吐量。
其他结果
用合成数据集训练
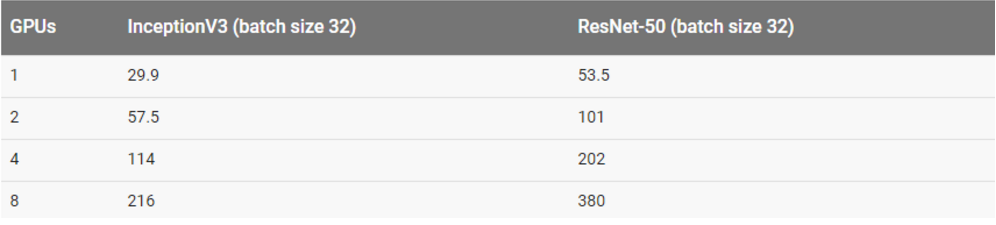
用真实数据集训练
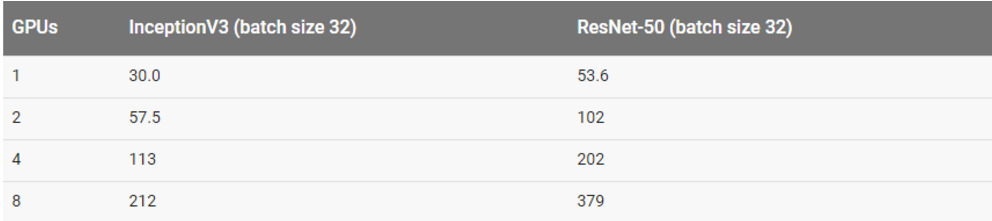
亚马逊 EC2 分布式训练(NVIDIA Tesla K80)的细节
环境
-
实例类型:p2.8xlarge
-
GPU:8x NVIDIA Tesla K80
-
操作系统:Ubuntu 16.04 LTS
-
CUDA / cuDNN:8.0 / 5.1
-
TensorFlow GitHub hash:b1e174e
-
构建命令:
bazel build -c opt --copt=-march="haswell" --config=cuda //tensorflow/tools/pip_package:build_pip_package
-
硬盘:1.0 TB EFS (burst 100 MB/sec for 12 hours, continuous 50 MB/sec)
-
数据集:ImageNet
-
测试日期:2017 年 4 月
每一个模型使用的批量大小和优化器都展示在下表中。除了表格中所列举的批量大小,InceptionV3 和 ResNet-50 还使用批量大小为 32 进行过测试。这些结论显示在「其他结果」部分。

用于每一个模型的配置

为了简化服务器设置,EC2 实例(p2.8xlarge)运行工作服务器时同样运行参数服务器。相同数量的参数服务器和工作服务器用于以下异常情况:
-
InceptionV3:8 个示例/6 个参数服务器
-
ResNet-50:(批大小 32)8 个示例/4 个参数服务器
-
ResNet-152:8 个示例/4 个参数服务器
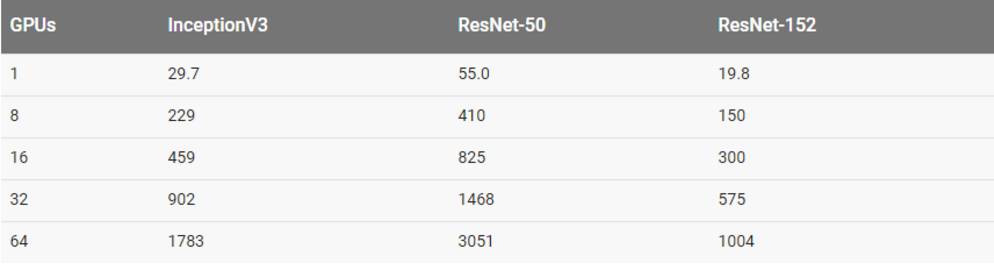
结果
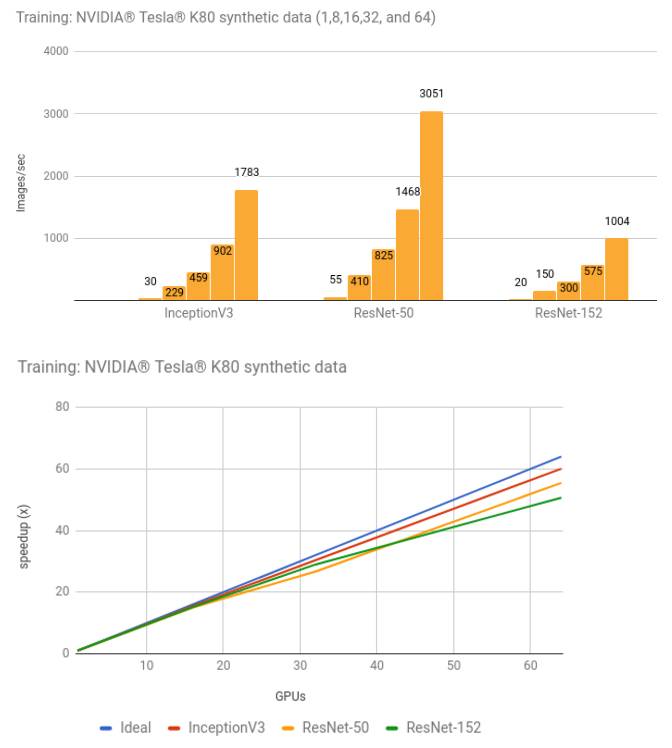
用合成数据训练
其他结果
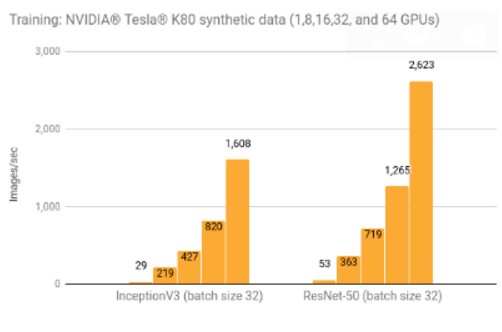
用合成数据训练
方法论
为了生成上述结果,我们将这一脚本(链接:http://suo.im/2OoknL)放入不同平台运行。在博文高性能模型(链接:http://suo.im/muzYm)中详细描述了脚本中的技术,并给出了执行脚本的示例。
为了尽可能创建可重复试验的结果,每个测试运行了 5 次并取平均值。GPU 在给定平台的默认状态中运行。对于 NVIDIA Tesla K80 来说,这意味着减少了 GPU Boost。对于每一次测试,先完成 10 个预热步(steps),再对接下来的 100 个步(steps)取平均值。

原文链接:
https://www.tensorflow.org/performance/benchmarks?from=singlemessage&isappinstalled=0
点击阅读原文,报名参与机器之心 GMIS 2017
↓↓↓