编辑:Gemini
这是极客公园2017 年第一期的活动,来自 Hulu 北京研发中心的研发总监周涵宁 Eric,和我们分享了在视频产品中的推荐系统模型,以及他在 Hulu 的相关技术产品经验。
以下为本次分享的精华摘要:
什么是推荐系统?
最早的视频推荐系统,我们可以追溯到街角的「录像店」——在那里你可以租赁到自己喜欢看的碟。但是有了视频网站后,用户便可以在家通过 APP 打开智能电视,或者直接上网,找到他要看的视频、电影。所以推荐系统首先要让用户「能够」找到他想看的内容,其次,在找的过程中,还要让用户找的更爽。比如有个用户进来看了一堆内容,那么我们把他看的所有的历史行为,嵌入到推荐引擎当中去。这个推荐引擎就会生成个性化的频道,下次这个用户再登录,或者都不用下一次,过 5 分钟之后,他看到的内容就会根据他最近发生的历史行为发生变化,这就是推荐系统的基本逻辑。
刚刚说的这种方法叫基于用户行为的推荐,当然是有一定局限性的。比如你只有一个用户行为的时候,你就不知道他会不会看一个从来没人看过的内容,这其实就是长尾问题。当你可以积累越来越多的用户,用户的历史行为会有助于你对长尾内容的理解。
推荐系统最终可以抽象成一个优化目标的问题。
我们要想一想,这个推荐系统到底在为谁服务?实际上它在为三类不同的利益相关方在服务:
第一个:用户。用户是为了能够更方便找到他想看的东西。
第二个:平台本身。平台希望连接服务提供商、内容提供商和用户,他希望赚钱。
第三个:内容提供商,因为内容提供商如果能有更多露出,他在这个渠道上,就会获得点击量或者/和品牌效应,那么他就可以通过一些方法变现,无论是广告的方法还是在一些离线渠道收买的方法。
所以一个推荐算法要同时服务三个利益各不相同的相关方,这本身导致了一个矛盾性。
协同滤波
最早的算法其实比较简单,叫协同滤波。就是相似的人,我会给他相似的内容,那么怎么定义相似的人呢?那就是他们之前具有相同的行为,但这个地方就变成了一个死循环。
后来有人想到一个方法,就叫协同滤波,就是用一个 interactive 的方法去 train,两边互相学,然后收链,这是一个比较标准的方法。那么在我们的系统里面用了大概接近 7、8 年吧,也比较成功。
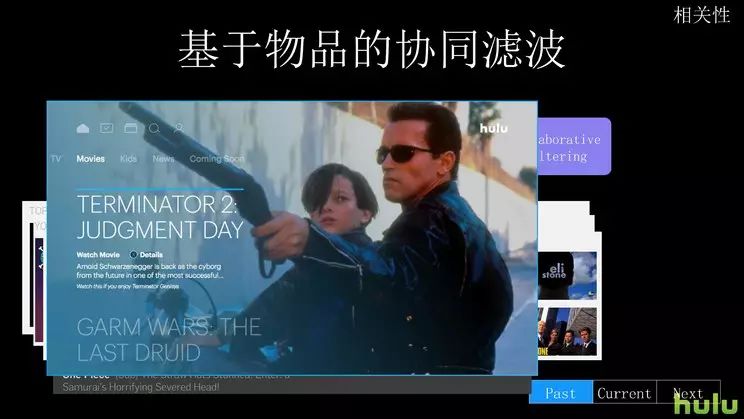
我们每一个展示叫一个 train,比如 Top picks for you 这是一个最标准的 record train,就是推荐 train.
第二个是 you may also like,你可能也会喜欢,这也是一个推荐的 train。
第三个就是一个子类别。一般大的类别就是言情、动作片,其实这个类别我们还分了一些小类别,比如说这个叫做法庭判案,实际上是动作片下面的一个主类别,这个也可以用推荐算法来产生。
这个叫 auto play,现在国内大多数网站都会有的功能,你看完了一个就自动播下一个,这个也是根据推荐算法来产生的
矩阵分解
现在的产品中我们使用的是矩阵分解的方法。
其实从 Netflix 以后大家就已经意识到矩阵分解是一种很有效的建模方式,它的基本原理就是把用户作为一个维度,内容作为一个维度,然后建一个二维的矩阵,把这个二维的矩阵找到一个低维的表示,这可能只有 50 或者 100 维,这个个数还是跟内容一样,所以每个内容有一个 100 维的小的表示,每个用户也有一个 100 维的小的表示。这两个作为一个点击,可以恢复出原来的东西。
为什么这样就能工作呢?详细讲解请见知乎 Live
Nade - 深度学习推荐引擎
我们下一代的推荐引擎是用深度学习的方法,具体的方法叫做 Nade,它其实原来是在文本的 top model 里面的一种方法。我们有一个专家是跟着 Nade 的发明人做博士毕业的,所以他对 Nade 特了解,他来到我们公司之后,就发明了 CF-NADE。这是我们 Hulu 自己发明的一种方法。
其实这个原理也不是很难,就是我们把这个 Nade 看成一个黑箱,基本的想法就是用 Nade 来训练一个用户的表示和一个内容的表示,但是这个表示可以不像矩阵分解那么死,因为它结合的时候不再是一个代数的点程,而是基于一个神经网络的,实际上带来了更多的自由度。
基于内容的推荐
我们现在在做的一个事,是去了解一个视频里每一帧他大概的情感是什么?你要说很复杂的情感现在也很难准确辨别,所以我们做的方法是先做一个 Face Detector,然后再把脸上的表情识别出来,现在也有一些很多现成做表情识别的东西。我们认为表情代表的场景的情感,大家可以看到下面有一些结果。

我们还会借助视频和音频相融合的方式。它有三套方法,一套是基于 CNN 的,一套是基于 RNN 的,还有一套是基于 SVM 的,一共是三套方法,我们会在三套方法中做一些融合。
如何说服用户?
刚刚讲的所有模型,其实最后归根结底是「做展示」,无论是用货架的方法来展示,还是用自动播放的方法来展示。但是这个展示的有效性很大程度上是取决于你有没有打动用户,你要给她一个很好的理由。我们试图给出一些推荐的理由,比如我们给这个用户推了这个剧,我们会说是因为你看过他的前传,这样的话用户会觉得,你确实是有道理的。还有一个是增强用户对系统的信任,如果你的系统是黑盒,扔出来一堆剧说看吧,那估计很难说服用户。
大家可以回想一下,在录像店的体验,如果是那种小店的话,你跟那个店主特别熟,他给你推一个张媛又拍了一个新片你可以看。你会知道,他真的知道你了解你,给你推这个东西,我们想达到的就是让计算机能够被用户所信任。
当然大家可能觉得这个跟人编辑还是有很大的差距,所以我们还在继续努力。这里面也用到一些基本 CNN 的东西。所以深度学习在我看来就是一个工具,你可以用来做很多的事,掌握好这个工具,灵活性更大。
Hulu 的直播新尝试
刚才大部分讲视频点播的场景,其实 HuLu 今年 6 月会做一个新功能:直播,这是一个很大的 feature,我们和美国四大电视台都有合作,直接把直播内容拿过来。每一个都是电视台正在播的节目,它跟歌华有很大的区别,你可以做搜索,你可以根据类别来分,已经完全把频道的概念淡化了,但你还是可以根据频道做一些浏览,并且可直接浏览,比如我想看现在所有的动作片,不管是哪个台播的,都可以直接看到。
我们的愿景是说,到了互联网时代,我们想要把电视台的概念完全透明化。它只是这个时间在播这个内容,对于这些内容应该怎样重新组合,完全应该是我们个性化推荐算法的责任,我们来给每个用户定制一个电视台,这是我们的愿景。
更多关于「直播」这个场景下,需要考虑的因素、需求、以及正在尝试使用的研究方法,可以移步「极客公开课知乎 Live」>>>>
关于冷启动
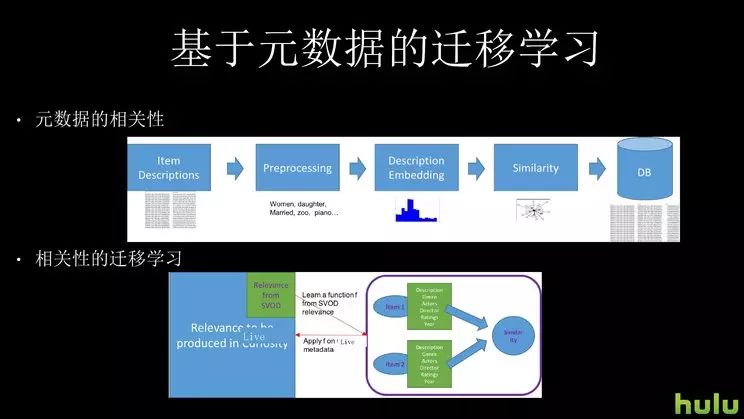
讲到冷启动,我们思路是在点播里,SVOD 是对点播的缩写,LIVE 是直播的缩写。在点播里我们有用户行为,那么根据一定的原数据,我们把用户行为 push 到一个直播的库里。
具体的方法,我们会拿到每个剧的一些描述,包括 title、actor 是谁,我们会把这种描述用 NLP 的方法,也是用词向量的方法,把它变成一个这叫 description embedding,然后可以度量相似度。有了相似度之后,我们可以把一个点播剧和一个直播剧的相似度,做一个关联。
实际上我们刚才讲到的冷启动问题,就是你怎么把用户在一个已知库上的行为,就是绿色的矩阵,扩张到一个不断有新剧出来,蓝色的更大的矩阵?这个矩阵的行和列,就是剧跟剧之间的关系,所以当你的剧集从已知两万剧的小库,变成一个 10 万剧的大库时,你就是要从绿色的矩阵到蓝色的矩阵当中。

我们用的方法就是基于源数据方法,你就可以产生一跳,比如这是一个 LIVE 的剧,这是一个 SWA 的剧,你想他们这些相关性,这一跳用得是原数据的方法得到的,那这个数就不是零了。
然后知道这个数之后,你想知道同样这个剧和另外一个 SWA 里面剧的关系的时候,你可以借助这两个剧在这个矩阵里的关系,就是给他乘一下,然后再乘一下,你就可以到它下一个数。这是一个比较简单的描述,当然具体的做法比这稍微复杂一些。
往期经典文章回顾
高等数学、线性代数、概率论与数理统计、几何学这些知识可以用来干什么?主要应用有哪些?
线性代数的本质--对线性空间、向量和矩阵的直觉描述
理解矩阵背后的现实意义
数学系和物理系学生有什么差别?
线性代数的本质
Leibniz 如何想出微积分?(三)
PCA的数学原理
零除以零在数学中有意义吗?
算法|人人都该了解的十大算法
对傅里叶级数的理解









