
图:pixabay
原文来源
:arXiv
作者:William Fedus、Ian Goodfellow、Andrew M. Dai
「雷克世界」编译:嗯~是阿童木呀
可以这样说,神经文本生成模型通常是自回归语言模型或seq2seq模型。这些模型通过序列性对单词进行采样从而生成文本,且每个单词是以前一个单词为条件产生的,并且是若干种机器翻译和总结基准的最新技术。这些基准通常由验证复杂度(validation perplexity)进行定义的,尽管这不是对生成文本质量的直接度量标准。另外,这些模型通常是通过最大似然法(maximum likelihood)和teacher forcing训练的。这些方法非常适合于优化复杂度,但是由于生成文本是基于那些可能在训练期间从未观察到的单词序列生成的,因此可能导致样本的质量较差。我们提出使用生成对抗网络(GAN)改善样本质量,它能够明确地对生成器进行训练以生成高质量的样本,并在图像生成方面取得了很大的成功。实际上,GAN最初设计的目的是用于输出微分值(differentiable values),所以离散的语言生成对它们来说也是具有挑战性的。我们认为,验证复杂度本身并不能真正代表模型生成的文本的质量。因此,我们引入了一个演员评论家条件生成对抗网络(actor-critic conditional GAN),它填补了根据周围上下文生成的缺失文本。我们进行了大量的定性和定量分析,结果表明,相较于用最大似然法训练的模型,该方法能够产生更真实的有条件和无条件的文本样本。
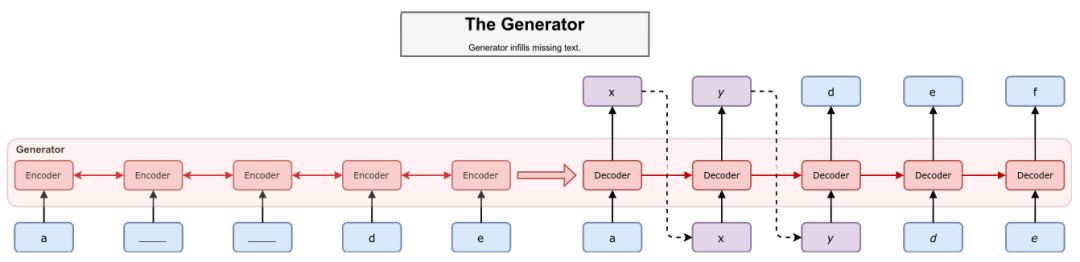
seq2seq 生成器架构。蓝色方块代表已知标记,紫色方块代表已输出的标记。我们通过虚线展示了一个采样过程。编码器在掩码序列中读取,其中,掩码标记用下划线表示,然后解码器通过使用编码器隐藏状态生成缺失标记。在这个例子中,生成器应该按照字母表顺序进行填充(a,b,c,d,e)
循环神经网络(RNNs)是序列以及序列标记任务中最常见的生成模型。它们在语言建模、机器翻译和文本分类任务中显示出了令人印象深刻的结果。文本通常是从这些模型中生成的,通过对基于前一个单词的分布和一个隐藏状态进行采样实现这一点,其中,该这隐藏状态是由截止目前为止所生成的所有单词的表示组成。这些模型通常是由最大似然法以一种被称为teacher forcing的方法进行训练的,其中要将对照单词(round-truth words)反向馈到模型中以便生成句子的后续部分。但是在样本生成过程中,这通常会存在一些问题,即模型经常被迫要以那些在训练时间从未使用过的序列为基准进行相关操作,这往往会导致在RNN隐藏状态中出现一些不可预测的动态。而专家已经提出诸如Professor Forcing和定期采样(Scheduled Sampling)等方法以解决这个问题。这些方法通过使隐藏状态的动态变为可预测的(Professor Forcing),或通过在训练时间随机以采样单词为基准进行相关操作,从而间接地起作用。然而,它们并不直接在RNN的输出上指定一个成本函数以鼓励高采样质量。而我们提出的方法是可以实现这一点的。
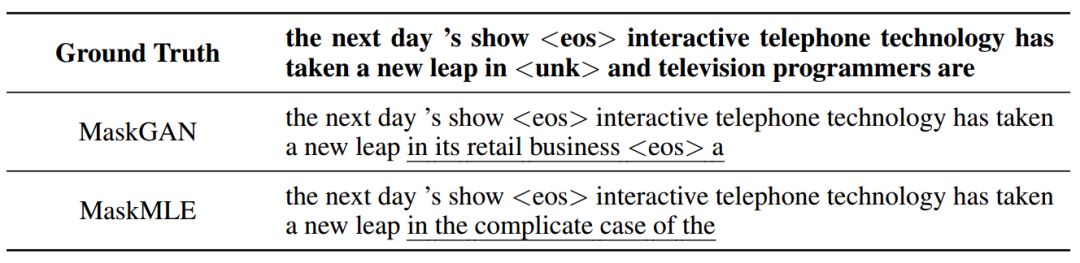
用于 MaskGAN 和 MaskMLE 模型的PTB 数据集中的条件样本
生成对抗网络(GANs)是一个用于在对抗设置中训练生成模型的框架,其中,生成器生成试图欺骗鉴别器的图片,而鉴别器被训练用以进行真实图像和合成图像的区分。相较于其他方法,GAN在生成更为真实的图像方面已经取得了很大的成功,但是它们在文本序列的使用中存在一定的局限性。这是由于文本的离散性,使得在标准GAN训练中,将梯度从鉴别器反向传播回生成器是不可行的。我们通过使用强化学习(RL)对生成器进行训练,同时仍使用最大似然法和随机梯度下降(stochastic gradient descent)对鉴别器进行训练,从而克服了这个问题。另外,GAN也经常面临着诸如训练不稳定和模式下降(Mode dropping)等问题,且这两个问题在文本环境中都加剧了。当生成器几乎没有生成训练集中的某些模式时,就会出现模式下降的问题,例如,使火山的所有生成图像都变为同一火山的多个变体。这变成了文本生成中一个很重要的问题,因为在数据中存在许多复杂的模式,从二元语法(bigram)到短语再到较长的习语等。训练稳定性也是一个问题,因为与图像生成不同的是,文本是自回归生成的,因此只有生成完整的句子后才能从鉴别器中观察到具体的损失。当生成越来越长的句子时,这个问题久会更加复杂化了。

用于MaskGAN模型的PTB中的语言模型(无条件)样本
我们通过在一个填充空白(fill-in-the-blank)或填充(in-filling)任务中训练我们的模型,从而减少这些问题所带来的影响。这与Bowman等人(于2016年)提出的任务相似,但我们所使用的环境具有更强的鲁棒性。在这个任务中,一部分文本被删除或编辑。该模型的目标是填充文本的缺失部分,从而使其与原始数据无法区分。在填充文本的过程中,模型自回归地对截至目前为止已填充的标记(token)进行操作,就如同在标准语言建模中一样,同时基于真实的已知上下文进行操作。如果整个文本的主体都被编辑,那么问题就简化为语言建模了。
在以往的自然语言GAN研究中,人们已经注意到设计每个时间步的误差归因(error attribution)的重要性了。文本填充任务自然而然地将这个问题考虑在内了,因为我们的鉴别器将对每个标记进行评估,并且因此向生成器提供细粒度的监督信号。考虑一下,例如,如果生成器在前 t-1 时间步生成一个与数据分布完美匹配的序列,随后生成了一个异常标记yt(x1:t-1yt)。尽管现在整个序列由于错误标记的原因而明显是合成的,但是对于在异常标记处而非其他处产生很高损失信号的鉴别模型来说,将可能产生一个具有更多信息的错误信号发送给生成器。
可以说,这一研究也为自然语言环境下的条件GAN模型提供了进一步的研究。
我们的研究进一步支持了与训练和推理过程相匹配的情况,以产生更高质量的语言样本。 通过GAN训练,MaskGAN算法直接实现了这一过程,并像人类评估人员的评估那样,进一步提升了生成样本的质量。

Mechanical Turk 平台对在 IMDB 评论中训练的两个模型的盲评估。来自每一个模型的 100 条评价(每条 40 个单词长度)为无条件随机采样。评估者被询问更喜欢每对样本中的哪一个。对每个模型对的比较中进行了 300 次评分
在我们的实验中,我们通常会发现,在那些连续单词块被掩码的地方所进行的训练,往往能够产生更好的样本。一个猜想是,这使得生成器组可以在自由运行模式下探索更长的序列。而相比之下,随机掩码通常具有较短的空白序列需要填充,所以GAN训练的增益并不是很大。我们发现策略梯度方法与已学习评论家(learned critic)联合起来的结果是非常有效的,但是对离散节点训练的高度活跃的研究可能会呈现更为稳定的训练过程。
我们还发现,注意力(attention)的使用对于所填充的单词能够充分基于输入上下文来说是非常重要的。如果没有注意力,填充将会填充合理的子序列,这些子序列在相邻的周围单词的上下文中变得难以置信。考虑到这一点,我们猜想另一个有前景的途径就是像Vaswani等人(于2017年)所考虑的那样,采用只有注意力模型的GAN训练。
总的来说,我们认为所提出的连续填充任务是减少模式崩溃的好方法,并且有助于文本GAN的训练稳定性。我们的结果显示,在较大的数据集(IMDB评论)上,MaskGAN样本的表现比由人类评估所展示的相应的调优MaskMLE模型要好得多。我们还表明,尽管MaskGAN模型在对照值测试集上存在更高的复杂度,但我们仍然可以生产出高质量的样本。
原文链接:
https://arxiv.org/pdf/1801.07736.pdf
欢迎个人分享,媒体转载请后台回复「转载」获得授权,微信搜索「raicworld」关注公众号
中国人工智能产业创新联盟于2017年6月21日成立,超200家成员共推AI发展,相关动态:
中新网:
中国人工智能产业创新联盟成立





