300 + 明星创业公司,3000 + 行业人士齐聚
全球人工智能与机器人峰会 GAIR 2017
,一 同见证 AI 浪潮之巅!峰会抢票火热进行中。
今天特放出
5
个
直减 1300 元的无条件优惠码
(见文末,优惠幅度逐天减小),感谢各位读者对雷锋网的支持,用浏览器打开链接即可使用。
近日,周志华教授开源了其在深度学习领域研究的新型算法——gcForest。他在论文中提到,不同于DNN的神经网络结构,它是一种基于决策树集成的方法。同时相比DNN,gcForest的训练过程效率高且可扩展,在仅有小规模训练数据的情况下也照常运转。不仅如此,作为一种基于决策树的方法,gcForest 在理论分析方面也应当比深度神经网络更加容易。
除此之外,周志华在论文最后特别提到,对于他的新方法,英特尔的KNL可能提供了像GPU之于DNN那样的潜在加速。

究竟是什么原因产生了这样的结果?带着这个疑问,AI科技评论采访了英特尔中国研究院院长宋继强,以期为广大读者深入剖析KNL在gcForest算法方面的计算优势。
宋继强告诉
AI科技评论
,乐见类似gcForest这样的新算法思路出现,因为这种多样性对于推动AI技术的发展大有裨益。对于人工智能算法的硬件加速,宋继强表示,并不存在一个通用的方案可以包打天下。对于不同的应用场景,应该选择不同的硬件平台。他从技术的角度系统地阐释了KNL和GPU之间各自适用的范围,并不讳言GPU在深度神经网络方面的计算能力,而是从辩证的角度说明了KNL相对GPU在gcForest甚至是DNN计算上的优势所在。
他还剖析了英特尔在人工智能芯片领域的包括KN系列、Lake Crest、FPGA在内的三条重要的产品线的定位,并给出了相应的选择建议,对于甚嚣尘上的AI芯片架构之争是个很好的回应。
同时,采访中还涉及到了英特尔中国研究院下半年在AI方面的计划,研究院和刚成立不久的AIPG之间的定位关系,以及与周志华团队的合作情况等话题。

宋继强
宋继强博士现任英特尔中国研究院院长。他的研究兴趣包括智能机器人与外界的交互技术,多种形态的智能设备创新,移动多媒体计算,移动平台的性能优化,新型人机界面,并为新的应用使用模式创建软件和硬件环境。
宋博士于2008年加入英特尔中国研究院,时任清华大学-英特尔先进移动计算中心应用研发总监,是创造英特尔Edison产品原型的核心成员。在Edison成功产品化之后,他推动开发了基于Edison的智能设备开发套件来促进Edison技术在创客社区的普及,并发明了称为交互式瓷器的新的设备类别。目前他致力于研发基于英特尔技术的智能服务机器人平台。
从2001年至2008年,他历任香港中文大学博士后研究员、香港应用科技研究院(ASTRI)首席工程师、北京简约纳电子有限公司多媒体研发总监等职。2003年,他研发的算法获得IAPR GREC 国际圆弧识别算法竞赛一等奖。2006年,他参加的计算机读图技术研究荣“获教育部高等学校科学技术二等奖” (第二完成人)。他是IEEE和CCF高级会员,在IEEE TPAMI、IEEE TCSVT、Pattern Recognition、CVPR、ICPR等国际期刊与会议上发表学术论文40余篇。
宋继强于2001年获得南京大学计算机专业博士学位,博士论文被评为全国优秀博士论文。
以下是宋继强院长接受采访实录,
AI科技评论
做了不改变原意的整理:
一、关于gcForest算法
AI科技评论
:如何看待深度森林(gcForest)和深度神经网络(DNN)?
宋继强:gcForest现在还处在刚刚开始的阶段,就像2006年的深度神经网络一样。现在周老师把gcForest开源给整个学术界、工业界,这是非常好的事情。目前来看它相对于DNN的优势体现在两方面,一方面在于可解释性,一方面在于适用的领域。
可解释性
神经网络目前来看还是一个黑箱,里面有很多超参数,初始的设置包括后来调优的过程,人们不好去琢磨它的理论基础。虽然现在也有一个研究热点,就是做神经网络的可解释性,但这还是在刚刚起步阶段。
如果把它换成其他一些中间学习的部件,比如像gcForest这种基于决策树做的一系列工作,最大的好处就是,从特征过来的时候,会在每一个分支下做判断。比如这个特征要大于某一个值的时候向左分支,小于某一个值的时候向右分支,所以天然就有一些规则在那儿。它的参数空间就会小很多,训练出来以后可以去分析和解释。这也是为什么目前在著名的Kaggle数据科学比赛平台上,多数获胜者的模型还是基于决策树扩展和集成(比如XGBoost)做出来的。
如果这件事情能从理论上解释得通,我们对这个模型就有充分的信心了。机器学习真正出来一个结果后,我可以把它变成知识,而不只是停留在模型的层面。因为从让机器去学,到最后变成人可以认可的理论和知识,这是一个完整的过程。
适用领域
其实周老师在他论文的开始也提到了一个问题,在深度学习的领域,大家比较认可的是,做表示学习的时候,模型如果深、层级多,就可以更好的去表示这样的问题。为了达到这样的结果,就需要模型的容量够大,但是不是一定要采用神经网络去训练?这个是可以商榷的。
我认为不是所有的情况下神经网络都是最优的训练学习模型,因为有时候用它反而把事情复杂化了。

⬆️ 英特尔对AI领域的分类
另一方面,深度神经网络虽然非常适合语音和图像的识别,但AI领域其实不只包含这些,还包括理解,推理并做相应的决策。整个过程都构造好了,那才是让人工智能完全可以完成任务。
现在深度神经网络帮助我们解读了视觉信息,因为视觉信息是一帧一帧的图象,还有很好的空间关系。我们本身看见的东西都是像素点构成的,中间是有空间的关系。而用卷积这种方式提取特征,是很适合去提取空间关系的,并且构造了多个维度、不同方向上的,多个分辨率的提取特征的方式,最后放到巨大的多层网络里去找它相应的关联。
到下面一个层级,时间轴发生变化。比如这里是一个人,那里是一张桌子,那边是一把椅子,随着时间的推移,人在动,桌子上可能多了一个东西,所以要继续理解这个场景的时候,未必能完全依靠现在的神经网络的方式去提取特征,这时候就需要依靠别的。
gcForest论文里面用的几个测试集就很有意思,几个测试集在图象层级上的处理,其实跟深度神经网络差不多,稍微能打平,甚至是数据集大的时候,深度神经网络还是会比它好。
但是在涉及到时间维度上,有连续性的东西,或者是要把情感从杂乱无章的文本里抽取出来的时候,这种空间关系不是那么好的数据,发现它的提升还是蛮大的。比如说一个简单的识别,这里面有一个叫hand moment recognition,通过机电信号去识别手势,比别的方法提高了大概接近百分之百。这是非常有说服力的,也就说明它在处理这些连续有规则信号方面(因为这个手势是具有一定规则的),非常的简洁高效。
总之,在进一步去探索AI的技术的方向上,第一,基于决策树的模型更具有可解释性;第二,深度森林可以帮我们去理解很多在时序上和空间上都有规则的事情。
所以我觉得这是一个新的思路。从英特尔层面来讲,是欢迎有这种新的思路存在,因为这样的话才能真正体现出多样性。
二、关于AI芯片的架构之争及软件生态
AI科技评论
:能从解读产品的角度来谈谈为什么在运行gcForest方面,KNL相比GPU会有优势吗?KNL和GPU甚至是TPU的区别和联系表现在哪里?对于AI芯片的架构争论,您怎么看?
宋继强:实际上我们应该把这个问题放在不同的应用领域来看。在AI芯片这个领域,凡是有人说有一个通用的方案的,其实都是不对的,英特尔从来不会说我们有一个东西能包打天下。
所以英特尔在端层面,有Movidius;在Edge层面我们用像FPGA这样的方案;在云端我们有KNL、Lake Crest这些。
对于不同的应用,我们要给用户最适合的解决方案,这种方案里同时考虑数据的加速,带宽的处理,甚至考虑到通讯怎么处理,在前端要考虑功耗怎么样等等。
具体的拿gcForest来说,它的特点是里面有很多不同的树,每棵树本身的训练是可以分开做的,所以本身就有很大的模型的并行度。KNL和GPU都可以用,但是KNL的好处是它本身就有72个核,每个核上还可以出4个Hyper tread,等于本身就可以提供288个线程,是理想的模型级并行的加速器。
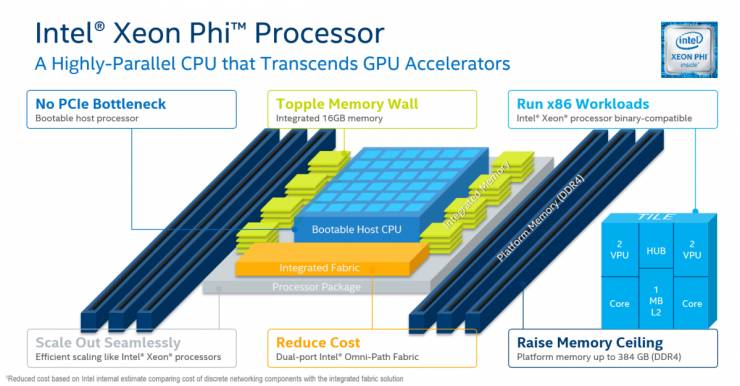
⬆️ KNL的硬件架构图
同时对于树的处理来讲,中间本身有很多条件判断跳转。在原来X86的架构上这反而是非常容易的,因为X86是基于指令运算去做加速的,单指令多数据流和单指令单数据都是它处理的强项。
而GPU里面对于处理这种跳转多的情况实际上会导致很大资源的浪费,因为它大部分是在做多指令多数据流同时的并行处理,要把很多数据准备好了打包,成形后一并做处理运算。
这时如果中间有很多的Branch,Branch的意思是指令可能要跳转到另一个地方去执行,数据级的并行度就被打破了,打破之后会导致很多问题,有可能数据在另外一个内存的地方,要重新拿过来。对于这种处理,KNL就有天然的优势。
所以周老师在他第二版论文中最后一页专门提出:
我们对比的时候就会看到,在不同数据处理的模式下,应该选择不同的加速模式。
KNL可以很好地分配内存和高速内存里的数据,因为新的KNL允许用户去配置高速内存的使用方式,它对算法怎么样使用数据是有比较好的灵活度的。
同时用上OPA这种新的数据互联加速,打破原来去访问内存和多节点互联的瓶颈。因为我们知道,GPU扩大到多GPU节点的时候,会有一个IO上限,到了上限,再增加GPU,训练的性能得不到太多提升。因为IO已经成为瓶颈了。但是如果说用KNL的方式,就可以突破这种瓶颈,增加到甚至上千个节点,仍然保持接近线性的增加。同时包含一些比如IO存储方面新的技术,可以带来不同种类的伸缩性能。
对于TPU,它跟英特尔的AI路线图里面的Lake Crest是同一个级别的东西,都是属于专门为深度神经网络定制的加速器,定制的程度是非常高的,如果换成深度森林,就未必能很快的适应。
所以我们讲的话,不会直接讲KNL比GPU好,或者是GPU比KNL好,要放在到底是加速什么样的应用下。
AI科技评论
:那是否能说对于深度神经网络的加速,GPU比KNL更适合?
宋继强:不是说KNL不能加速深度神经网络,我们曾经试过,去年在AI Day的时候也发布过这样的数据,就是当时把一个Caffe的代码放在KNL上的时候,得到一个初级的性能。后来经过我们软件部门做了软件的并行优化之后,它在KNL上提升了400倍的性能。
可见做不做软件层级的优化差别是很大的,对于深度神经网络我们也可以提高很多倍的优化性能。同时再配合上硬件的性能不断提升,因为KNL比KNC已经提高了3倍,今年下半年会出来的KNM,比KNL硬件本身能力又提高4倍。所以对于使用KN系列的算法研究者来讲,他们是可以享受到这个红利的。
一方面使用软件优化,另一方面可以享受到KN系列的硬件逐年性能提升带来的红利。
对于深度学习这个领域来讲,如果模型容量很大的话,肯定是需要利用到像KNL、KNM这种级别的加速的。GPU是一个协处理器,模型和数据一般放在显存中。现在显卡最新的一般是16G,最大的可能有24G,但很难买得到. 有一些场合需要特别大的模型,可能就放不进显存去,这时候就有很大的问题。但是对于KNL来说,可能会是比较好一点的方式。
至于它中间部件到底采用GPU还是KNL比较好?其实要看情况分析。比如说周老师这边讲到,他觉得可能做前面特征的扫描放在GPU上也很好,因为那一块有很多的数据操作,比如说块操作,可以把它整合。
回过头来想,我们的KNL上,其实每一个Core上也提供了两个512位宽的叫做矢量加速器(AVX-512)。这个矢量加速器如果用好的话,对于处理这种块并行的操作也是很有效的。其实如果说使用得当的话,在KNL上去做矢量的加速计算,我们称为SIMD的计算,和这种需要去做很多分支处理的计算,都可以并行很好的话,这个性能还是非常值得期待的。从原来没有优化过的性能到后来提升到千倍以上是可以达到的。
AI科技评论
:关于Lake Crest和KNL,在产品定位方面是一个怎样的关系?能不能这样说,Lake Crest是英特尔对于英伟达的GPU推出的竞争产品?而KNL是基于可以和CPU更好的配合关系,所以更适用于决策树模型算法的一个硬件。
宋继强:这样说还不太准确。
Lake Crest是专门针对深度神经网络深度定制的产品,目的是为了得到更快的加速比。它的定制需要综合DNN所需要的计算和带宽的需求,还有扩展节点数量等因素。因为Lake Crest里面也有很多计算节点,每个Lake Crest芯片可以和另外12个芯片互联,形成超网格,而且互联带宽是非常高的。所以在深度学习大规模模型训练的方面,速度会非常强悍。
举个例子,假如是对海量的视频做处理,这个时候不停的会有新的问题进来,就需要反复地训练模型。而且数据量会比以前大的很多,因为像“平安城市”这样的场景,会布置大量的摄像头,这些数据重新训练回来以后会比以前有大幅度的提升,所以一定要需要在云端有这样的能力去做快速的训练,更新模型下发到前端。
以后除了在云端的摄像头数据,无人车每天产生的数据,里面也会产生很多的特殊情况,是现在解决不了的。比如不同国家的行人、不同国家地面上面的物体其实都不太一样,必须反复训练,而且这个数据量也非常大。
我们不认为现在的GPU方案就是一个终点了,一定需要更快、更节省能源的方式。目前TPU和Lake Crest全部是ASIC解决方案,它是性能功耗比最优的方案,因为是深度定制。所以如果是想解决最终的那种海量的数据,并且对数据中心来讲保持低的运营成本,也就是说用电量比较少,ASIC一定是最终的方案,而且它的扩展性会很好。
如果说未来有新的算法可以处理更多的其他应用,比如说gcForest是其中一个例子,对于这些新的方法,TPU、Lake Crest都未必是最好的加速器。这时我们可以用KNL、KNM。
而对于NVIDIA来说,实际上GPGPU也是可以去支持不同领域的东西,只不过是相比其他领域,它对深度神经网络可以提供最高的加速比。
类似GPU一样,也需要有人在上面做专门的优化。其实CUDA这个项目,NVIDIA已经运作了十年,最后才找出了深度学习这一个killer APP。如果有新的Killer APP出来未必在CUDA平台上是最优的。为了应对未来不可知的新的Killer App,可以说FPGA和KNL都是很好的方案。
所以我觉得应该这样去划分,才能够比较完整地解释英特尔在AI芯片这个领域所做的重要布局。
-
对于现在已知的Killer App,就是用深度神经网络去做类似视觉方面处理的时候,Lake Crest是一个当然之选。
-
如果是为了应对还不太知道的Killer APP或者是已知道的很多生命科学、金融方面的分析,或者是其他的天气气象原本就是高性能计算的应用,KNL本身就是在做这个事情,而且它会继续去支持这些需要灵活调优但还没有到做ASIC这个程度的应用,都是可以用KNL去做的。
-
如果用户已经对硬件加速有所了解,但还不是很确定的时候,可以用FPGA去试。FPGA是比ASIC更快的可以去做硬件级别实验的一个平台。
AI科技评论
:KNL有一个上一代的产品KNC,相比之下,KNL有哪些升级?
宋继强:这个升级还是蛮大的。我来讲几个关键的点。
第一,整体性能提升了2.5倍到3倍的级别,每个单核芯的性能也提升了接近3倍。KNL最多可以到72个核心,就计算能力来说,KNL处理器的双精度浮点为3TFlops左右,单精度浮点可以到6TFlops左右。
比起原来的KNC,现在KNL采用了新的二维的网格架构。它可以允许指令乱序执行,这时处理器执行指令的时候就能够更好的去填掉比如说Cache miss、Branch等造成的空档,可以更好的提高指令处理的并行度。
现在的KNL把矢量加速单元AVX扩展到512个Bite宽,可以同时处理64个字节一起做矢量运算。同时它在内存这一块也有一个改进,增加了高速内存,高速内存是多通道的内存。这里面集成了16GB,用户可以把它配置成是Cache,也可以把它配置成自己去管理的内存。比如说用户要放一些经常要被处理器Core存取的数据,不想让它通过Cache的方式自动映射。因为Cache会产生Cache miss,把它变成自己管理,由用户来负责它的数据的加载和重新存取。
这个速度带宽就高达500G字节/秒,是原来DDR4的4-5倍,这都是大幅的提高。而且现在在KNL里面第一次集成了Omni-Path,就是高速的网络互联。KNC的定位为一个协处理器,它一定要有一个Host来跟它配合。这个Host可以是至强,也可以是Core系列的处理器。
KNL分为两种:
这些相比来讲,会更加方便用户。而且我们提供不同等级的KNL的SKU(销售型号),在价格上有不同的选择,相应来说它会有一些偏重于计算,有一些偏重于数据的I/O等。
同时,从去年开始我们在美国已经实验的,在云端给用户提供一个Educational Cluster的平台。因为对于在校学生,多节点的KNL还是蛮贵的,但是有了这个云平台,用户可以在那里提交自己的任务去做实验。
今年我们希望把云端这块的实验平台在中国部署开放起来。届时希望有两种方式去支持大家做这种计算加速,还有节点扩展加速的实验,用不同的算法和不同的应用去做相应的实验。这样的话,我觉得可以推动更多的人去试更多的硬件。英特尔在软件方面去提供的工具支持也会越来越多。
我觉得KNL还是非常有潜力的硬件加速产品,它对于很多模型本身就有并行度,而且数据之间也有一定的并行度,并且中间还要有一些决策的时候特别有帮助。
AI科技评论
:很多深度学习的用户都表示,比起芯片底层的硬件架构,他们更加关注软硬件在一起的生态,对此,英特尔是如何做的?
宋继强:在软件生态方面,英特尔支持AI应用的通用软件堆栈(雷锋网按:如下图所示),中间三层用来屏蔽底层硬件的实现差异、支持流行开源框架和与加速应用方案的工具。

⬆️ 英特尔提供的AI解决方案
具体来说,英特尔准备在软件层提供比较一致的软件接口。
对于已经在使用开源框架的用户
如果是已经在使用开源框架的用户,比如现在流行的TensorFlow、MXNet、Caffe,英特尔的策略是我们有一个对它们的统一接口,开发者可以用他们熟悉的开源的框架去训练模型。
同时底下我们会对接上英特尔的中间层,中间层可以把它映射成我们英特尔的MKL的加速和我们称为扩展性加速的库。扩展性加速是干什么的呢?因为MKL是加速数学运算的,比如说张量运算。但是如果要把它扩展到多个节点上,比如说扩展到72个核,甚至扩展到1000个核上的时候,这时候就需要用扩展加速,它去帮用户解决互联之间的数据传输和控制的传输的一些加速,而不用用户去管它。
这时虽然用户使用的是开源框架,但是他可以很容易的使用到底下的硬件加速能力,用KNL也好,用Lake Crest也好,会映射到不同的硬件上去。
对于新的学习者
如果是新的学习者,他可以有两个选择,一个选择使用开源的框架,一个是选择使用英特尔提供的基于Neon的框架,它是Nervana原来还是独立公司前的框架,也是排在前十的。现在他们还继续基于这个框架在做一些事情。
如果说用户选择这个框架的话,会直接能够利用到底下很多的加速。同时Nervana还在做一个事情,当然它现在是英特尔的AIPG。他们在做一个叫nGraph的软件层次工具,也就是说用户的程序里其实有很多可并行的地方,但是由于算法其实很复杂,要用户自己去分析的话,未必能把它拆分得很好。
而这个nGraph工具就是来抽取里面可并行的部分,把它分到不同的硬件的加速单元上去。比如说分到不同的Lake Crest,里面有好多个加速的矢量计算单元。怎么分配?它来做优化,有一点像我们传统的在高性能计算的时候,英特尔的Parallel Studio里面有Thread Building Block,就等于帮你自动去把程序里面的可以并行的线程给你提取出来,放在不同的核上去。
对于初学者来讲,他可以不用自己去搞定所有的软件堆栈的每一层怎么去优化,他可以先去使用开源的工具也好,使用我们英特尔提供的工具也好,把他的算法、模型先训练好,然后通过我们中间提供的这些工具链映射到不同的层级。
这是我们现在走的战略,软硬件结合去做。
AI科技评论
:除了深度森林和DNN以外,KNL还适合哪些应用和算法?
宋继强:KNL在Life Science里面也有很多的应用,比如像基因测序,精准医疗。在一些零售的领域同时处理很多个不同用户的一些请求,做一些相关的安全验证等,都是可以的。其实应用的领域非常适合让多个核同时去做,因为它们本身就是需要去分割这些任务去处理。而且在处理的过程中并不都是图像的块与块之间比对,生成很多完整的块的vector然后再去逐步往后走的,还需要很多灵活性的程序在运行。
三、关于英特尔中国研究院
AI科技评论
:能否详细说说英特尔和周志华团队的合作?
宋继强:周老师是国内人工智能领域的杰出学者,领军人物。所以英特尔的产品部门、学术研究部门也都一直在关注。我们现在形成的是战略合作关系,这个框架会包含几方面内容:
第一方面,学术界擅长于去定义算法和新的理论,但是如果要把性能直接提升到产业的标杆级别,这还是有一定的困难。不同AI的应用,需要不同种类的软硬件加速方案去做。
而产业界有很强的工程化资源和计算能力,比如英特尔可以提供一些新的软硬件,给学术界去做相应的学术算法的验证,我们的技术团队还可以配合他们做性能的优化。这样可以达到强强联合,把新理论真正推动到市场应用的级别。
另一方面,英特尔在AI这个领域想做三件事:
-
第一件事是Fuel AI,赋能AI。让它不只局限于现在大家看到的几个领域,让它能够更广泛的应用在各种新的行业里,这是增强AI的能力。
-
第二件事是Democratize AI,民主化。让AI更多的为一般的工程开发人员所用。我们觉得像周老师这种开源是非常好的,开源以后有很多的学生、团队、老师可以去试用,试用以后用上英特尔这样商业化的平台。比如他们现在是在不同的PC上做,这样的成本就相对来说低很多。如果愿意使用英特尔的KNL去做实验的话,我们在国内也会去发布基于云或者是基于实际计算设备的计划,来辅助学术界去用KNL做实验,把成本降低下来。
-
第三个事就是英特尔保证AI做正确的事,引导AI去做非常有益于社会的事情。
现在我们主要是关注前两块。
在业界,英特尔是具有领导力的公司。在学术界,周老师团队是具有号召力、影响力的学术团队。我们联合起来,会把AI的生态环境推动的更好,这就是现在合作的情况。
AI科技评论
:今年英特尔成立了AIPG,在公司的层面上,研究院在推进AI方面,和他们有什么样的协作和分工?
宋继强:AIPG是个产品部门,它是英特尔对外提供人工智能所驱动的产品领域的直接对外出口。这个出口实际上会整合英特尔内部软件、硬件的甚至算法的很多的技术资源,把它形成解决方案往外推。
研究院相对来说是对内的,不直接对外提供产品。我们所做的一些AI方面的研究可能会更前瞻,也更有一些变数,我们会去看外边学术界会发生什么,并相应的做一些学术方面的研究。
除了跟随外部的研究热点外,甚至我们会找一些新的热点做。我们在一些相应的CV(计算机视觉)的比赛,比如情感识别,我们都能拿到世界冠军。这些技术是在研究院里面去做的,达到一定程度,对产品部门的某些产品可以产生直接应用的时候,产品部门就会把这些技术转化到他们的产品里面去。
我觉得研究院和AIPG是一个很好的合作关系,大家在时间线上是不重叠的,并且是一个技术研究和输出的关系。
AI科技评论
:下半年研究院有没有什么新的打算?尤其是在AI方面。
宋继强:主要会在深度学习训练这块,包括和美国的研究院一起,看如何去提升深度神经网络的训练,并且把这个网络压缩。然后在新的硬件,就是KNL,Knight Mills、Knight Landing这些上面做一些新的实验,这是一种,可能会用到更多的节点去做训练。
另外,在神经网络训练好了以后,我们会做相应的裁减,裁减以后往Lake Crest,FPGA, Movidius这样的硬件上去落地。这样的话,能把AI做深度学习的能力放到更小型设备上去。
所以这是两个方向:在云端要做更大规模的训练,同时把训练时间缩短;最后训练的模型争取能够把它变小。
(完)
CCF-GAIR 2017,100 + 优质展位,1000 + 传统供应链玩家,全球顶级技术方案商悉数亮相,帮企业实现 AI 技术方案快速对接,掘金万亿 AI 产业!
高端资源、优质展位、名额有限,再不申请就没了
!
电话或微信联系方式:
15013779392
https://gair.leiphone.com/gair/coupon/s/5937fca242705
https://gair.leiphone.com/gair/coupon/s/5937fca2424cb
https://gair.leiphone.com/gair/coupon/s/5937fca2422b6
https://gair.leiphone.com/gair/coupon/s/5937fca242053
https://gair.leiphone.com/gair/coupon/s/5937fca241c3e
优惠券仅限「参会门票」
每张
只能使用一次。赠送的优惠劵
额度每天递减 50 元,有效期为 1 天。长按复制链接,在浏览器打开
立即使用。大会介绍点文末
阅读原文
AI科技评论招业界记者啦!
在这里,你可以密切关注海外会议的大牛演讲;可以采访国内巨头实验室的技术专家;对人工智能的动态了如指掌;更能深入剖析AI前沿的技术与未来!
如果你:
*对人工智能有一定的兴趣或了解
* 求知欲强,
具备强大的学习能力
* 有AI业界报道或者媒体经验优先
简历投递:
[email protected]






